第 1 章 python 入门
1.1 python 概述¶
python 是一种解释语言。命令通常在被称为 python 解释器的软件中执行。python 解释器接收到一条命令,然后评估该命令,最后返回该命令的结果。
- 程序员通常提前定义一系列命令,然后把这些命令保存为纯文本文件,这些程序被称为源代码或脚本。对于 python, 源代码通常存储在一个扩展名为 .python 的文件中(例如 demo.python) 。
- 许多集成开发环境( Integrated Development Environments , IDE) 为 python 提供了更加丰富的软件开发平台,包括一个拥有标准 python 发行版的 IDLE 。IDLE 提供了一个嵌入式的文本编辑器(可显示和编辑 python 代码),以及一个基本调试器(允许逐步执行程序,以便检查关键变量的值)
1.1.1 python 程序预览¶
print('Welcome to the GPA calculator . ')
print('Please enter all your letter grades, one per line . ')
print('Enter a blank line to designate the end.')
# map from letter grade to point value
points = {'A+':4.0,'A':4.0,'A-':3.67,'B+' :3.33,'B' :3.0, 'B-' :2.67,
'C+' :2.33,'C' :2.0, 'C' :1.67, '0+':1.33, '0' :1.0, 'F' :0.0}
num_courses = 0
totaLpoints = 0
done= False
while not done
grade = input() # read line from user
if grade =='': # empty line was entered
done = True
elif grade not in points: # unrecognized grade entered
print("Unkno叩grade'{O}'being ignored".format(grade))
else:
num_courses += 1
totaLpoints += points[grade]
if num_courses > 0: # avoid division by zero
print('Your GPA is {O:.3}' .format(totaLpoints / num_courses))
python 的语法在很大程度上依赖于缩进。典型的写法是将一条语句写在一行
在 python 划定控制结构的主体时,可以用空白字符进行缩进。具体来说,代码块缩进到其指定的控制体结构内,嵌套控制结构使用空白缩进保待代码整洁。在代码段 1-1 中,while 循环主体之后的 8 行,包括嵌套的条件结构都使用空白进行了缩进。
python 解释器会忽略代码中的注释。在 python 中,注释是以#字符标识的,# 表示该行的剩余部分是注释。
1.2 python 对象¶
python 是一种面向对象的语言,类则是所有数据类型的基础
1.2.1 标识符、对象和赋值语句¶
在 python 语言的所有语句中,最重要的就是赋值语句,例如
temperature = 98.6
这条语句规定 temperature 作为标识符(也称为名称)与等号右边表示的对象相关联,在这一示例中浮点对象的值为 98.6 。图 1-1 描述了这种赋值操作的结果

- 在 python 中,标识符是大小写敏感的,所以
temperature和Temperature是不同的标识符。 - 主要的限制是标识符不能以数字开头(因此
9lives是非法的名字),并且有 33 个特别的保留字不能用作标识符

- 每个标识符与其所引用的对象的内存地址隐式相关联。python 标 识符可以分配给一个名为 None 的特殊对象
- 与 Java 和 C++不同, python 是一种动态类型语言,标识符的数据类型并不需要事先声明。标识符可以与任何类型的对象相关联,并且它可以在以后重新分配给相同(或不同)类型的另一个对象。
- 在第一个示例中,字符 98 .6 被认为是一个浮点类型,因此标识符 temperature 与具有该值的 float 类的实例相关联。
程序员可以通过向现有对象指定第二个标识符建立一个别名。继续前面的例子,图 1-2 描绘了一个赋值操作 original = temperature 的结果。

当使用一个别名而通过另一个别名更改对象的行为,其结果是显而易见的(因为它们指的是相同的对象) 。
然而,如果对象的一个别名被赋值语句重新赋予了新的值,那么这并不影响巳存在的对象,而是给别名重新分配了存储对象。
temperature = temperature + 5.0
这条语句的执行首先从=操作符右边的表达式开始。表达式 temperature + 5.0 是基于巳存在的对象名 temperature进行运算,因此,结果的值为 103.6, 即 98.6 + 5 。
- 该结果被作为新的浮点实例存储,如果赋值语句左边的名称是
temperature, 那么(重新)分配存储对象 - 同时,后面这条语句对标识符
original继续引用现有的浮点型实例的值没有任何影响。

1.2.2 创建和使用对象¶
实例化¶
创建一个类的新实例的过程被称为实例化
一般来说,通过调用类的构造函数来实例化对象。例如,如果有一个名为 Widget 的类,假设这个构造函数不需要任何参数,我们可以 使用如 w = Widget()这样的语句来创建这个类的实例。如果构造函数需要参数,我们可以使用诸如 Widget(a, b, c) 的语句来构造一个新的实例。
许多 python 的内置类(在 1.2.3 节中讨论)都支持所谓的字面形式指定新的实例。例如,语句 temperature = 98.6 的结果是创建 float类的新实例。在该表达式中, 98.6 这个词是字面形式。我们将在接下来的部分进一步讨论 python 的字面形式
- 另一种间接创建类的实例的方法是调用一个函数来创建和返回这样一个实例。例如, python 有一个内置的函数名为 Sorted (见 1.5 . 2 节),它以一系列可比较的元素作为参数,并返回包含这些巳排序元素的 list 类的一个新实例
调用方法¶
python 支持传统函数调用(见 1.5 节),调用函数的形式如 sorted(data) 。在这种情况下,data 作为一个参数传递给函数
- python 的类也可以定义一个或多个方法(也称为成员函数),类的特定实例上的方法可以使用点操作符(".")来调用。
- 例如, python 的
list类有一个名为sort的方法,那么可以使用data. sort()这样的形式调用- 点左侧的表达式用于确认被方法调用的对象。通常,这将是一个标识符(例如
data) - 此外,我们可以根据其他操作的返回结果使用点操作符来调用一个方法。例如,如果
response标识一个字符串实例,那么可以采用response.lower().startswith('y')的形式调用函数,其中response.lower()返回一个新的字符串实例,在返回的==中间字符串的基础上==调用startswith('y')方法。
- 点左侧的表达式用于确认被方法调用的对象。通常,这将是一个标识符(例如
- 当使用一个类的方法时,了解它的行为是很重要的
- 访问器:返回一个对象的状态信息,但是并不改变该状态
- 应用程序或更新方法:如 list 类的 sort 方法,会改变一个对象的状态
1.2.3 python 的内置类¶
表 1-2 给出了 python 中常用的内置类。
- 如果类的每个对象在实例化时有一个固定的值,并且在随后的操作中不会被改变,那么就是不可变的类。例如, float 类是不可改变的。
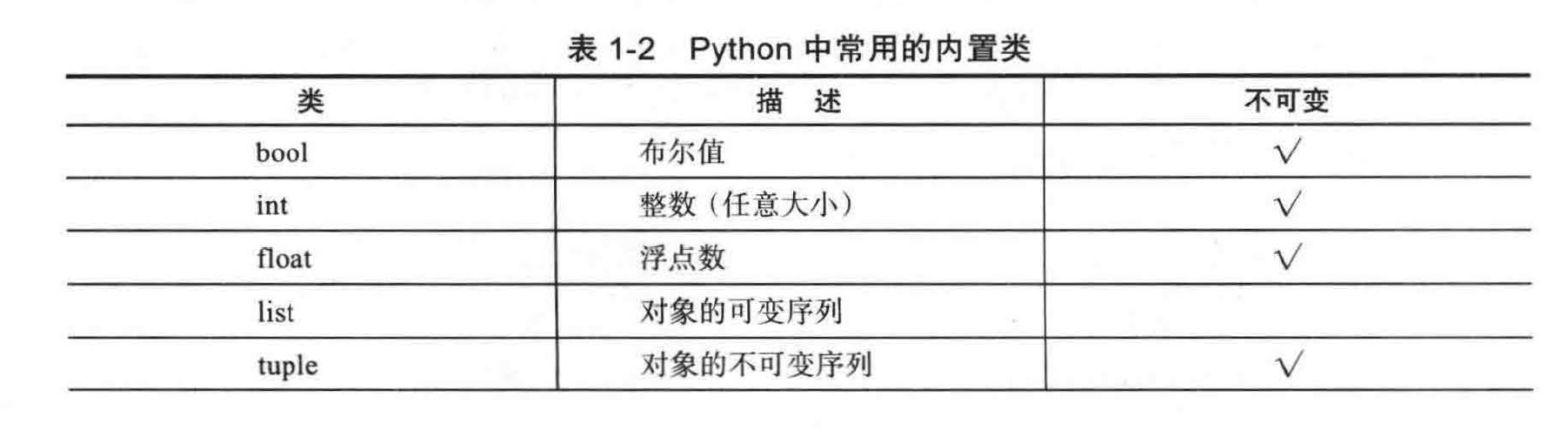

大多数内置类都存在字面形式(如 98 .6) ,所有类都支待传统构造函数形式创建基于一个或多个现有值的实例。
布尔类¶
布尔( bool ) 类用于处理逻辑(布尔)值,该类表示的实例只有两个值一 True 和 False
-
默认构造函数
bool()返回 False -
python 允许采用
bool(foo)语法用非布尔值类型为值foo创造一个布尔类型 -
就数字而言,如果为零就为 False, 否则就为 True
-
对于序列和其他容器类型,如字符串和列表,如果是空为 False, 如果非空则为 True 。
-
一个重要应用是可以使用非布尔类型的值作为控制结构的条件
python
while bool(1):
print(1)
可以一直输出 1
整型类¶
整型 (int) 和浮点 (float) 类是 python 的主要数值类型。
- int 类被设计成可以表示任意大小的整型值(python 会根据其整数的大小自动选择内部表示的方式)
- 可以使用 0 这个前缀和一个字符来描述这些进制形式(二进制、八进制或十六进制)。这样的例子分别有 0b1011 、0o52 和 0x7F 。
- 整数的构造函数 int()返回一个默认为 0 的值(强制类型转换)
- 整数的构造函数 int()返回一个默认为 0 的值。该构造函数可用于构造基于另一类型的值的整数值。例如,如果 f 是一个浮点值,表达式 int(f) 得到 f 的整数部分。例如, int(3.14) 和 int(3.99) 得到的结果都是 3
- 构造函数也可以用来分析一个字符串(例如用户输入的一个字符串),该字符串被假定为表示整型值。如果
s是一个字符串,那么 int(s) 得到这个字符串代表的整数值。例如,表达式 int('137')产生整数值 137 - 如果一个无效的字符串作了参数,如
int('hello'),那么就会产生一个 ValueError
浮点类¶
浮点 (float) 类是 python 中唯一的浮点类型,使用固定精度表示
- 浮点型数据的另一种表达形式是采用科学计数法。例如,表达式 6.022e23 代表数学上的 \(6.022\times10^{23}\)
- float()构造函数的返回值是 0.0
- 调用函数 float(2) 返回浮点值 2.0
- 如果构造函数的参数是一个字符串,如 float('3.14'),它试图将字符串解析为浮点值,那么将会产生 ValueError 的异常
序列类型:列表、元组和 str 类¶
list 、tuple 和 str 类是 python 中的序列类型,代表许多值的集合,集合中值的顺序很重要
- list 类是最常用的,表示任意对象的序列(类似于其他语言中的“数组”)
- tuple 类是 list 类的一个不可改变的版本,可以看作列表类一种简化的内部表示。
- str 类表示文本字符不可变的序列。
列表类¶
列表(list) 实例存储对象序列。
列表是一个参考结构,因为它在技术上存储其元素的引用序列(见图 1-4)
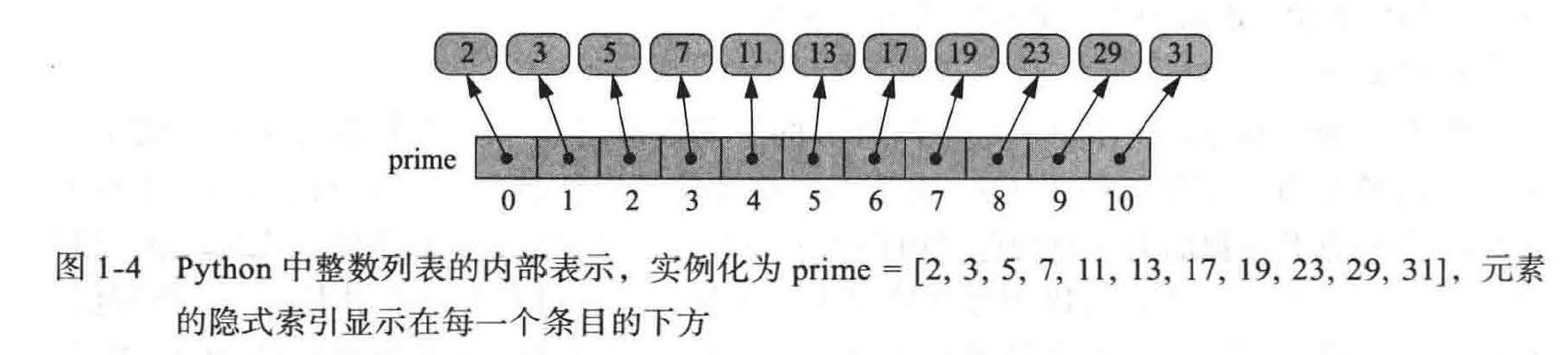
-
列表的元素可以是任意的对象(包括 None 对象)
-
列表是基于数组的序列,采用零索引,因此一个长度为 n 的列表包含索引号从 0 到 n - 1 的元素
- python 使用字符[]作为列表的分隔符, [] 本身表示一个空列表。
- [‘red','green','blue']是含有三个字符串实例的列表
- 列表中的内容并不需要在字面上表达出来。如果标识符 a 和 b 已经声明,则语法 [a, b] 是合法的。
-
list() 构造函数默认产生一个空的列表
-
所有的标准容器类型(如字符串、列表、元组、集合、字典)都可以用于迭代
-
Iist('hello') 产生一个单个字符的列表,[’h','e','I','I','o']
-
此外,语法 backup = list(data) 可用于构造一个新的列表实例,该列表实例引用与 data 相同的内容作为原始列表元素
python
data = list('hello')
backup = list(data)
元组类¶
元组( tuple ) 类是序列的一个不可改变的版本,它的实例中有一个比列表更为精简的内部表示。
python 使用[] 符号表示列表,而使用圆括号表示元组,()代表一个空的元组
- 为了表示只有一个元素的元组,该元素之后必须有一个逗号并且在圆括号之内。例如,(17,) 是一元元组
- 如果没有添加后面的逗号,那么表达式 (17) 会被看作一个简单的带括号的数值表达式。
str 类¶
python 的 str 类专门用来有效地代表一种不变的字符序列,它基于 Unicode 国际字符集

字符串可以用单引号括起来,如 'hello' ,或双引号括起来,如 “hello” 。这种选择很方便,特别是在序列中使用另一个引号字符作为一个实际字符时,如 “Don't worry” 。
- 另外,引号的分隔作用可以用反斜杠来实现,即所谓的转义宇符
- 因为反斜杠可以实现这个目的,它在字符串中正常使用时也应该遵循这个用法,如 'C:\\python\\',它实际所要表达的字符串是 C:\python\
- 其他常用的转义字符有 \n(表示换行)和 \t(表示制表符) Unicode 字符也包括在内,如 '20 \u20AC' 表示字符串 20 €
- python 也支持在字符串的首尾使用分割符 ‘’‘ 或者 ”“” 。这样使用三重引号字符的优点是换行符可以在字符串中自然出现(而不是使用转义字符\n)
set 和 frozenset 类¶
python 的 set 类代表一个集合的数学概念,即许多元素的集合,集合中没有重复的元素,而且这些元素没有内在的联系
-
使用集合的主要优点是它有一个高度优化的方法来检查特定元素是否包含在集合内(散列表)。
-
同时也存在两个限制
-
该集合不保存任何有特定顺序的元素集(集合的无序性)
- 只有不可变类型的实例才可以被添加到一个 python 集合
→ 如整数、浮点数和字符串类型的对象才有资格成为集合中的元素
-
有可能出现元组的集合,但不会有列表组成的集合或集合组成的集合,因为列表和集合是可变的
-
frozenset 类是集合类型的一种不可变的形式,所以由 frozensets 类型组成的集合是合法的。
python 使用花括号{ 和 } 作为集合的分隔符,例如,{ 17 } 或 { 'red','green', 'blue' } 。这个规则的特例是{}并不代表一个空的集合;由于历史的原因,{}代表一个空的字典
- 除此之外,构造函数 set()会产生一个空集合。如果给构造函数提供可迭代的参数,那么就会产生不同元素组成的集合。例如, set('hello')产生集合 {'h','e','I','o'} 。
字典类¶
python 的 diet 类代表一个宇典或者映射,即从一组不同的键中找到对应的值
- python 实现 diet 类与实现集合类采用的方法几乎相同,只不过实现字典类时会同时存储键对应的值。
- 字典的表达形式也使用花括号,因为在 python 中字典类型是早于集合类型出现的,字面符号{ }产生一个空的字典
- 一个非空字典的表示是用逗号分隔一系列的键值对。例如,字典 {'ga':'Irish','de':'German'}表示 'ga' 到 'Irish' 和 'de' 到 'German' 的一一映射
diet 类的构造函数接受一个现有的映射作为参数
- 在这种情况下,它创造了一个与原有
- 字典具有相同联系的新字典。另外,构造函数接受一系列键值对作为参数, 如 dict(pairs) 中的
pairs = [('ga', 'Irish'), ('de', 'German')]。
1.3 表达式、运算符和优先级¶
在使用运算符(即各种特殊符号和关键词)的情况下,现有的值可以组合成较大的语法表达式。运算符(或称操作符)的语义取决于其操作数的类型。例如,当 a 和 b 是数字,语旬 a+ b 表示相加; 如果 a 和 b 是字符串,那么运算符就表示字符串的连接。本节中,我们在内置类型的不同上下文语义中描述 python 的运算符。
- 复合表达式的运算顺序可以影响表达式的整体结果。为此, python 定义运算符的优先级顺序,但允许程序员通过使用明确的括号对表达式中运算符的优先级进行调整。
逻辑运算符¶
python 支持以下关键字作为运算符,其结果为布尔值:
not 逻辑非 and 逻辑与 or 逻辑或
and 和 or 运算符是短路保护的,也就是说,如果其结果可以根据第一个操作数的值来确定, 那么它们不会对第二个操作数进行运算。
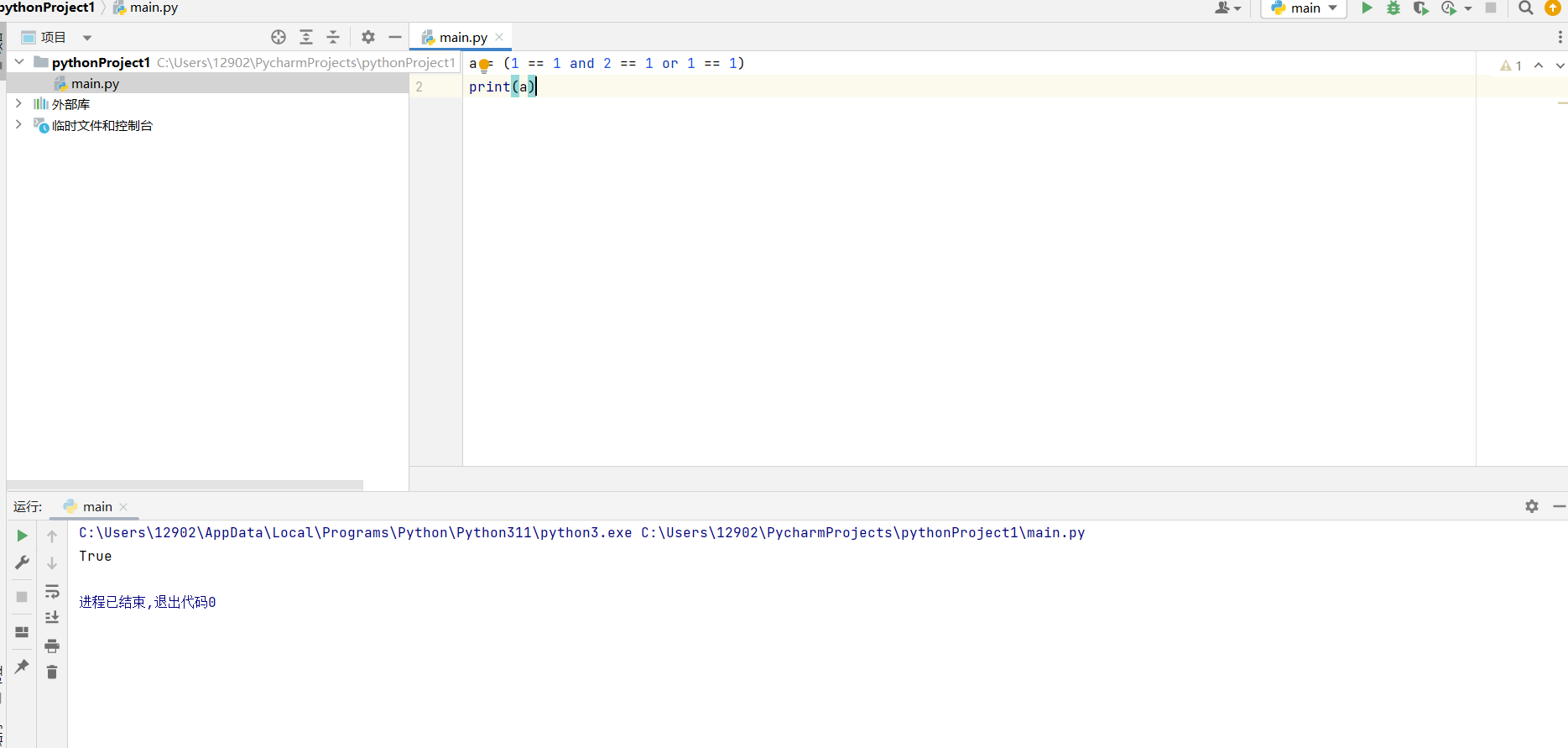
注意,此处的输出是 True,是因为虽然第一个 and 的结果是 0,但 or 的右侧是 1,因此结果是 True(and 并未判断后续的表达式)
相等运算符¶
python 支持以下运算符去测试两个概念的相等性:
is 同一实体 is not 不同的实体 == 等价 != 不等价
- 当标识符 a 和 b 是同一个对象的别名时,表达式 a is b 的结果为真
- 表达式 a == b 测试一个更一般的等价概念。如果标识符 a 和 b 指向同一个对象,那么表达式 a == b 为真。
- 如果标识符指向不同的对象,但这些对象的值被认为是等价的,那么 a = b 的结果也为真。
- 精确的等价概念取决于数据类型。例如,对于两个字符串, 如果它们的每个字符都对应相同,那么它们可以看作是等价的。两个集合包含相同的元素,而不考虑其顺序,那么这两个集合可以看作是等价的
比较运算符¶
数据类型可以通过以下运算符定义一个自然次序:
< 小于 <= 小于等于 > 大于 > = 大于等于
这些运算符对于数值类型、定义好的字典类型和有大小写之分的字符串有可预期的结果。如果操作数的类型不匹配,例如 5 < 'hello' ,那么就会产生异常。
算术运算符¶
python 支持以下算术运算符:
+ 加 - 减 * 乘 / 真正的除 II 整数除法 % 模运算符
-
加法、减法和乘法的用法是很简单的,需要注意的是,如果两个操作数都是整型,那么其结果也是整型;如果有一个是浮点型,或两个操作数都是浮点型,那么其结果也是浮点型。
-
python 对于除法有更多的考虑
-
首先考虑均是整数的情况
例如, 27 除以 4 。在数学中, 27 ÷ 4 = 6.75 。在 python 中,/运算符表示真正的除,运算返回一个浮点型的计算结果。因此, 27 / 4 得到一个浮点型的值 6.75
此外,python 支持 II 和 %运算符进行整数运算,表达式 27 // 4 运算的值是整型的 6 (数学概念中的商),表达式 27 % 4 运算的值是整型的 3, 整数除法的余数
-
在操作数有一个或两个是负数的情况下, python 谨慎地扩展了 // 和%的语义。由于符号的缘故,我们假设变量 n 和 m 分别代表商式 \(\frac nm\) 的被除数和除数, q = n // m 和 r = n % m 。
python 保证 q * m + r 等于 n ,例如,6 * 4 + 3 = 27;
- 当除数 m 为正数时, python 进一步保证 0 ≤ r < m 。因此,我们发现 -27 // 4 运算的值为 -7 并且 27 % 4 运算的值为 1, 满足算式 ( - 7) * 4 + 1 = - 27
- 当除数为负数时, python 保证 m < r ≤ 0 。作为示例, 27 // - 4 运算的值为 -7 并且 27 % -4 运算的值为 -1 满足算 式 27 = (- 7 ) * (- 4) + ( - 1)
-
// 和 % 运算符的使用甚至扩展到浮点型操作数,表达式 q = n // m 的值是不大于商的最大整数,表达式 r = n % m 表示 r 是余数,确保 q _ m + r 等于 n 。例如, 8.2 // 3.14 运算的结果为 2 .0 , 8.2 % 3.14 运算的结果为 1.92, 满足算式 2.0 _ 3.14 + 1.92 = 8.2
位运算符¶
python 为整数提供了以下位运算符:
~ 取反(前缀一元运算符) & 按位与 I 按位或 ^ 按位异或 << 左移位,用零填充 >> 右移位,按符号位填充
序列运算符¶
python 每个内置类型的序列 (str 、tuple 和 list) 都支持以下操作符语法:
s[j] 索引下标为 j 的元素 s[start:stop] 切片操作得到索引为[start, stop) 的序列 s[start: stop: step] 切片操作,新的序列包含索引为 start,start + step, start + 2 _ step, …,直到序列结束 s+t 序列的连接 k _ s 序列 s 连接即 s+s+s+ … ( K 次) val in s 检查元素 val 在序列 s 中 val not in s 检查元素 val 不在序列 s 中
python 使用序列的零索引,因此一个长度为 n 的序列的元素的索引是从 0 到 n - 1
- python 还支持使用负索引, 表示离序列尾部的距离;索引 -1 表示序列的最后一个元素
- python 使用切片标记法来描述一个序列的子序列。切片被描述为一种半开放的状态,即==开始索引的元素包含在内==,结束索引的元素排除在外。例如,语句 data[3:8] 产生一个子序列,子序列包含 5 个索引值: 3, 4, 5, 6, 7
- 一个可选的 "step" 值,有可能是负数,可以当作切片的第三个参数。如果在切片表达式中省略了一个起始索引或结束索引,则假设起始或结束对应的是原始序列的头或尾。
因为列表是可变的,语法 s[j] = val 可以替换给定索引的元素。列表还支持语法 del s [j],即从列表中删除指定的元素。切片标记法也可以用来取代或删除子列表
表达式 val in s 可以用在任何序列中检验其中是否有元素与 val 的值相等。对字符串来说,这个语法可以用来匹配其中的一个字符或一个较大的子串,如 'amp'in'example'
所有序列规定的比较操作都是基于字典顺序,即一个元素接一个元素地比较, 直至找到第一个不同的元素。例如,[5, 6, 9] < [5, 7] ,因为第一个序列中索引为 1 的元素小。因此,下面的操作由序列类型支待:
s == t 相等(每一个元素对应相等) s != t 不相等 s < t 字典序地小于 s <= t 字典序地小于或等于 s > t 字典序地大于 s >= t 字典序地大于或等于
集合和字典的运算符¶
set 和 frozenset 支持以下操作:
key in s 检查 key 是 s 的成员、 key not in s 检查 key 不是 s 的成员 s1 == s2 s1 等价 s2 s1 != s2 s1 不等价 s2 s1 <= s2 s1 是 s2 的子集 s1 < s2 s1 是 s2 的真子集 s1 >= s2 s1 是 s2 的超集 s1 > s2 s1 是 s2 的真超集(s1 不等于 s2)
s1 I s2 s1 与 s2 的并集 s1 & s2 s1 与 s2 的交集 s1 - s2 s1 与 s2 的差集 s1 ^ s2 对称差分(该集合中的元素在 s1 与 s2 的其中之一)
需要注意的是,集合并不保证它们内部元素以特定的顺序排列,所以比较运算符(如<)不是以字典顺序进行比较的;相反,它们是基于子集的数学概念的
字典像集合一样,它们的元素没有一个明确定义的顺序。此外,对于字典,子集的概念并没有太大的意义,所以 diet 类并不支持形如<的运算符。字典支持等价的概念,如果两个字典包含相同的键-值对集合,那么 d1 == d2
- 字典最广泛使用的操作是访问一个值,这个值与特定的索引语法为 d[k] 的键 k 相关联。支待的操作如下:
d[key] 给定键 key 所关联的值 d[key] == value 设置(或重置)与给定的键相关联的值 del d[key] 从字典中删除键及其关联的值 key in d 检查 key 是 d 的成员 key not in d 检查 key 不是 d 的成员 d1== d2 dl 等价于 d2 d1 != d2 d1 不等价于 d2
扩展赋值运算符¶
python 支持对大多数二元运算符进行扩展赋值运算,例如,允许形如 count += 5 的语法表达式
- 对于不可变类型,如数字或字符串,不应该认为该语法会改变现有对象的值,而是它将对新构造的值重新分配标识符,然而,对于一种类型,它可通过重新定义语法规则去改变对象的行为,如对列表类进行+=操作
alpha = [1, 2, 3]
beta = alpha # an alias for alpha
beta += [4, 5] # 给原来的列表增添了两个元素
beta = beta + [6, 7] # 将 β 变为新列表 [1, 2, 3, 4, 5, 6, 7] 的别名
print(alpha) # will be [1, 2, 3, 4, 5]
这个例子展现了语句 beta += foo 与 beta = beta + foo 在列表语义方面的微妙差异。
复合表达式和运算符优先级¶
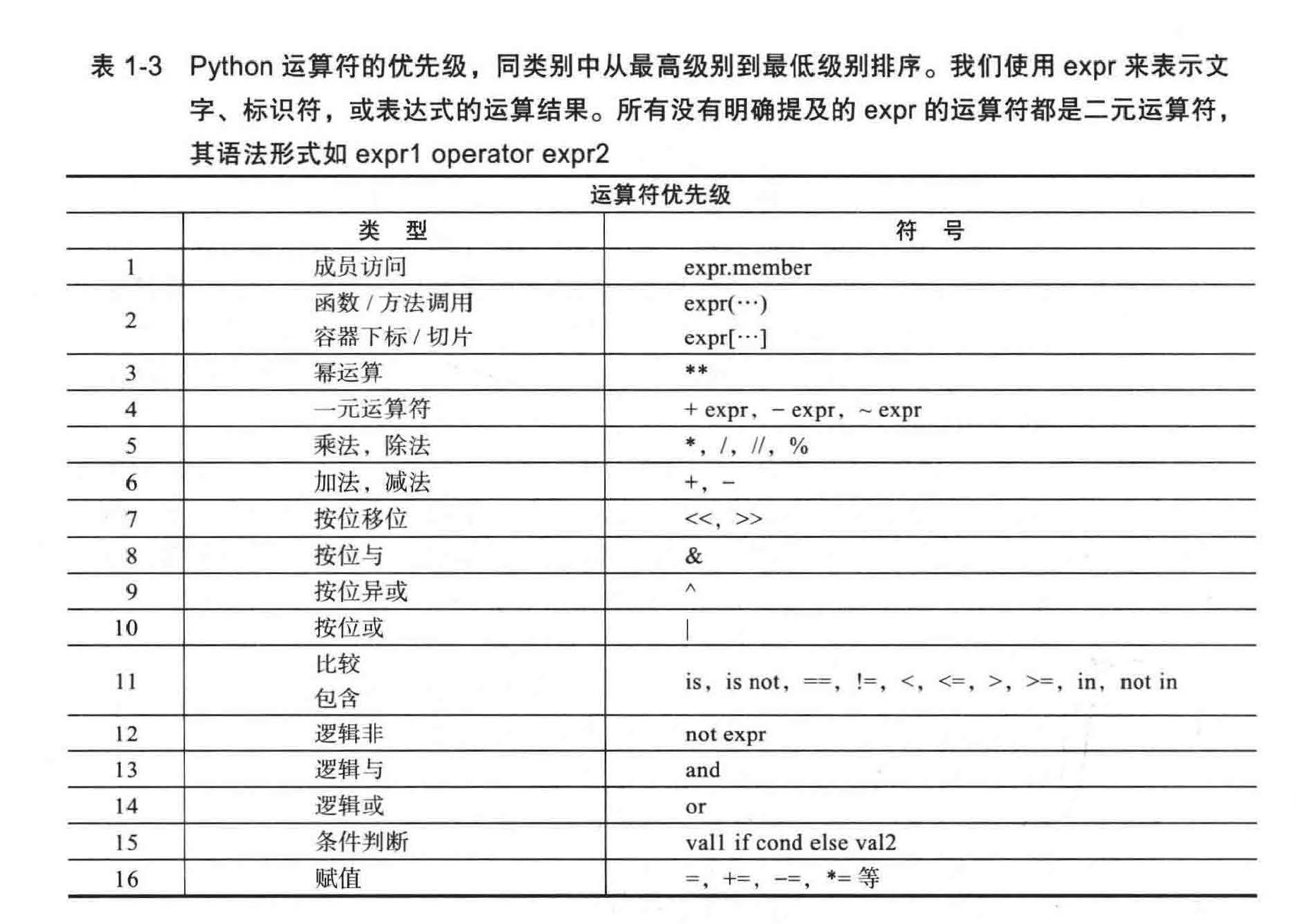
- 在同一个级别中,优先级高的运算符将会比优先级低的运算符先执行,除非表达式中有括号
- 同一个级别中的运算符是从左到右计算的,因此 5-2+3 的值为 6 。此规则的例外情况是一元运算符和求幕运算是从右至左运算的
- python 支持多级赋值,如
x = y = 0, 将最右边的值赋值给指定的多个标识符。python 还支持链接比较运算符。例如,表达式1 <= x + y <= 10等价于复合表达式(1 <= x + y) and (x + y <= 10),这样可以不用将中间值 x + y 计算两次
1.4 控制流程¶
在本节中,我们将回顾 python 中最基本的控制结构: 条件语句和循环语句
- python 依赖于缩进级别或嵌套结构来指定代码块。同样的原则适用于指定一个函数体(见 1. 5 节)和一个类的主体(见 2.3 节)
1.4.1 条件语句¶
条件结构(也称为 if 语句)提供了一种方法,用以执行基于一个或多个布尔表达式的运行结果而选择的代码块。在 python 中, 条件语句一般的形式如下:
if first_condition:
first_body
elif second_conditionsecond_
body
elif third_condition:
third_body
else:
fourth_body
每个条件都是布尔表达式,并且每个主体包含一个或多个在满足条件时才执行的命令
- 如果满足第一个条件,那么将执行第一个结构体,而其他条件或结构体不会执行
- 如果不满足第一个条件,那么这个流程以相似的方式评估第二个条件,并将继续下去
- 最后一条
else语句是可选的。
非布尔值(例如字符串)也可以隐式的被看作一个布尔值,同样以字符串为例:response 是一个由用户决定其内容的字符串
if response:
可以等价于
if response != '':
例如,一个机器人控制器可能有以下逻辑:
if door_is_closed:
open_door()
advance()
注意: 最后的命令 advance() 没有缩进,因此不是条件结构体的一部分。它将会被无条件地执行(尽管它在打开一个关着的门之后) 。
我们可以在一个控制结构中嵌套另一个控制结构,基于缩进可以明确不同结构体的范围。
if door_is_closed:
if door_ is_ locked:
unlock_door()
open_door()
advance()
上面的例子中,机器人除了判断门是否关着以外,还会在关着的情况下判断是否上了锁,或者也可以表示成流程图
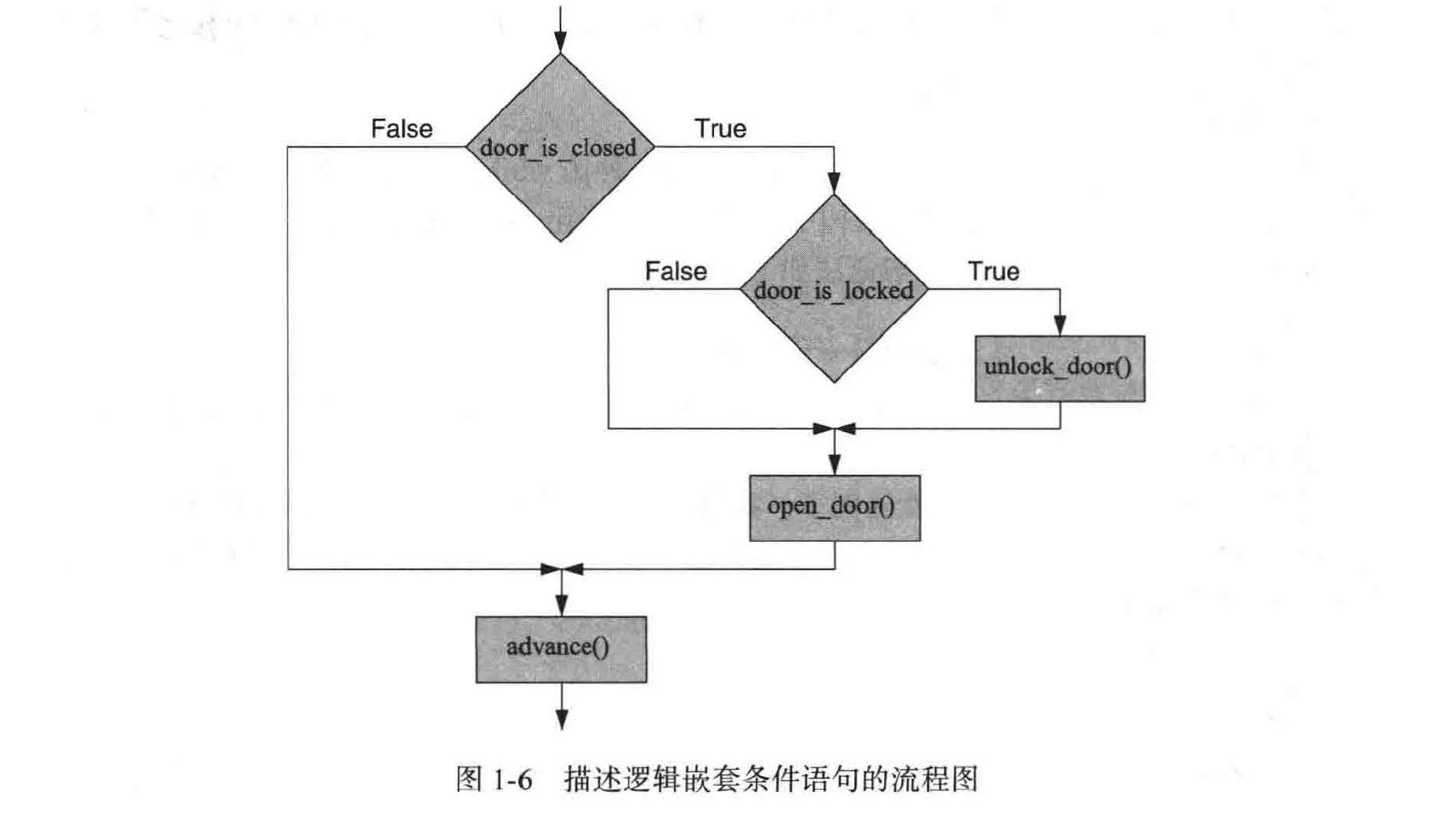
1.4.2 循环语句¶
python 提供了两种不同的循环结构。while 循环允许以布尔条件的重复测试为基础的一般重复。for 循环对定义序列的值提供了适当的迭代(如字符串中的字符、列表中的元素或一定范围内的数字)
while 循环¶
while 循环的一般形式可以描述如下
while condition
body
condition 可以是任意布尔表达式,结构体可以是任意代码块(包括嵌套控制结构) 。执行 while 循环时首先测试布尔条件。如果条件的结果为 True, 执行循环的主体。每次执行结构体后,重新测试循环条件
如果测试条件的结果为 False (假设曾经出现过),那么循环退出,并且控制流在循环的主体之外继续。
作为示例,这里给出一个循环,通过字符序列的索引,找到一个输入值为 'X' 的值或直接到达序列的尾部。
j = 0
while j < len(data) and data[j] != 'X'
j += 1
len 函数返回一个序列(如列表或字符串)的长度
- 这个循环的正确性依赖于 and 运算符的短路效应。在访问元素 data[j] 之前,首先测试 j < len(data) 以确保 j 是一个有效的索引。如果我们以相反的顺序写成复合条件, 当 'X' 不存在时, data[j] 的结果将最终会抛出
IndexError异常 - 如上所述,当这个循环结束时,如果 'X' 存在,变量 j 的值是出现在最左边的 'X' 的索引,否则就是序列的长度(这将会被作为一个预示着搜索失败的无效索引) 。值得注意的是这段代码本身的正确性,甚至在特殊情况下,如当列表为空时,条件 j < len(data) 一开始即执行失败,而循环体永远不会被执行
for 循环¶
在迭代一系列的元素时, python 的 for 循环是一种比 while 循环更为便利的选择。for 循环的语法可以用在任何类型的迭代结构中,如列表、元组、str 、集合、字典或文件(我们将在 1.8 节正式讨论迭代器) 。其一般语法如下
for element in iterable:
body # body may refer to 1element1 as an identifier
作为 for 循环一个很有启发性的例子,我们考虑的是计算列表中元素数值的总和( 当然,python 中有一个内置的函数 sum, 也可以达到这一目的) 。我们在 for 循环中执行如下计算,假设 data 是一个列表的别名
total = 0
for val in data:
total += val # note use of the loop variable, val
- 标识符 val 从 for 循环指定的元素开始遍历,对于 data 序列中的每一个元素,循环体都会执行一次。值得注意的是, val 被视为一个标准标识符。
- 如果原始 data 中的元素是可变的,可以使用 val 标识符调用它的方法。但是给标识符 val 重新赋一个新的值并不影响原始 data,也不影响下一次的迭代循环
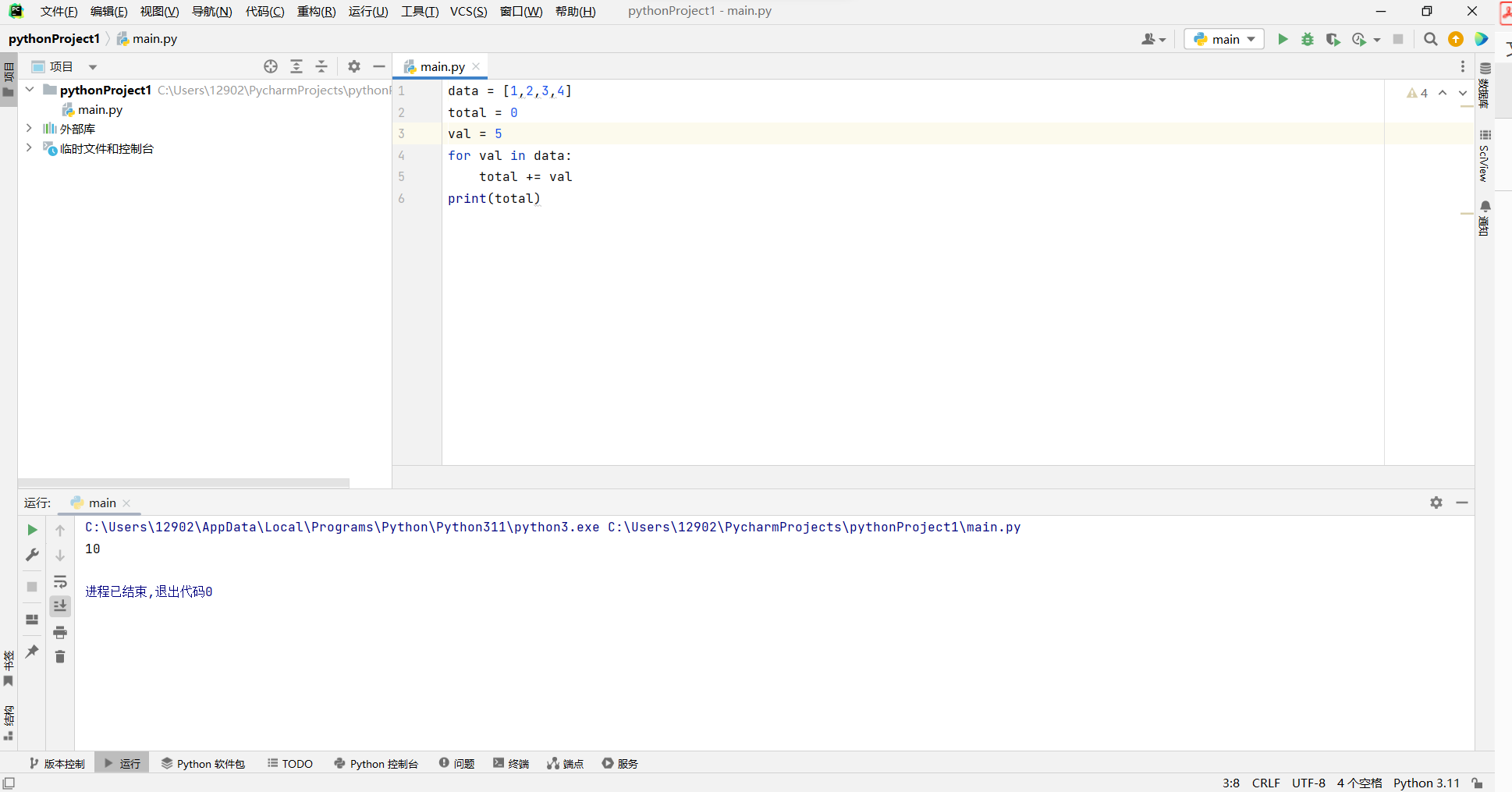
注意,即使事先给 val 赋值,也不影响后续的循环(甚至事先赋予的值都不在列表中),即 val 在循环中仅被视为一个标准标识符
第二个经典的例子,我们考虑在一个列表的元素中寻找最大值( python 的内置函数 max 已经提供了这种功能) 。我们可以假设 data 列表至少有一个元素,那么可以实现这个任务:
biggest = data[O]
for val in data:
if val > biggest:
biggest = val
虽然我们可以用 while 循环来完成上述任务,但 for 循环的优点是简洁,即不需要管理列表的明确索引及构造布尔循环条件
基于索引的 for 循环¶
标准的 for 循环用于遍历一个列表的元素时是很简洁的,但这种形式的一个限制是我们不知道元素在这个序列的哪一个位置,例如,假设我们想知道列表中最大元素所在的位置。
在这种情况下,我们宁愿遍历列表中所有可能的索引,而不是直接在列表的元素上循环。为此, python 提供了一个名为 range 的内置类,它可以生成整数序列
- 在最简单的形式中, 语法
range(n)生成具有 n 个值的序列,下标从 0 到 n - 1 。很明显,这一系列有效的索引构成的序列的长度为 n 。因此,标准的 python 语言对数据序列的一系列索引应用 for 循环时,使用以下语法
for j in range(len(data))
在这种情况下,标识符 j 并不是 data 中的元素,它是一个整数。而表达式 data[j] 可以用来检索序列中相应的元素。例如,我们可以找到列表中最大元素的索引,如下:
big_index = 0
for j in range(len(data))
if data[J] > data[big_index]
big_index = j
break 和 continue 语句¶
python 支持 break 语句, 当在循环体内执行 break 语句时, while 或 for 循环就会立即终止。更正式地说,如果在嵌套的控制结构中使用 break 语句,它会导致内层循环立刻终止
found = False
for item in data
if item == target:
found = True
break
一个典型的例子如上面的代码所示,它是确定一个目标值是否出现在数据集中
python 也支持 continue 语句, continue 语句会使得循环体的当前迭代停止,但循环过程的后续迭代会正常进行。
1.5 函数¶
在这一节中,我们探讨 python 中函数的创建和使用。正如我们在 1.2.2 节讨论的, 应明确函数和方法之间的区别。我们用一般的术语一函数来描述一个传统的、无状态的函数,
- 该函数被调用而不需要了解特定类的内容或该类的实例,例如
sorted(data) - 我们使用更具体的术语——方法来描述一个成员函数,在调用特定对象时使用面向对象的消息传递语法,如
data.sort()
我们从一个例子开始说明在 python 中定义函数的语法。在任何形式的可迭代数据集中,下面的函数计算给定目标值出现的次数。
def count(data, target)
n = O
for item in data:
if item == target:
n += 1
return n
- 以关键字
def开始的第一行作为函数的签名。这个标志建立了一个新的标识符作为函数的名称(在这个示例中是 count),并且设立了期望的参数个数,以及标识这些参数的名称(在这个示例中是 data 和 target) 。 - 与 Java 和 C++ 不同, python 是一种动态类型语言,因此 python 签名不指定这些参数的类型,也不指定返回值的类型(如果有的话) 。这些参数的使用在函数的说明文档中描述(见 2.2.3 节),并且在函数体中执行,但是对于函数的错误使用只有在运行时才被检测到。
函数定义的其余部分称为函数的主体。
- 和 python 中控制结构的情况一样,函数体通常以缩进的代码块的形式表示。
- 每次调用函数时, python 会创建一个专用的活动记录用来存储与当前调用相关的信息。这个活动记录包括了命名空间(见 1.10 节) 。命名空间用以管理当前调用中局部作用域内的所有标识符。
- 命名空间包含该函数的参数以及在函数体内定义的其他本地标识符
- 函数调用者局部作用域内的标识符与调用者作用域内的其他相同名称的标识符没有关系(虽然在不同的作用域的标识符可能是同一对象的别名) 。
return 语句¶
return 语旬一般用在函数体内,用来表示该函数应立即停止执行,并将所得到的值返回给调用者。
- 如果 return 语句在执行之后没有明确的返回值,则 None 值会自动返回给调用者。
- 同样,如果控制流在没有执行 return 语句的情况下到达过函数体的末端,那么 None 值被返回
如果命令执行受条件逻辑控制,那么在同一函数中可以有多个 return 语句。作为一个深入的例子,下面考虑这样一个函数——测试序列中是否有一个这样的值。
def contains(data, target):
for item in data
if item == target·
return True
return False
# found a match
如果满足循环体内的条件,那么 return True 语句就会执行,然后函数就会立即结束
1.5.1 信息传递¶
要成为一个优秀的程序员,你必须对编程语言如何从函数中传递信息的机制有一个清晰的理解。
- 在函数签名的上下文中,用来描述预期参数的标识符被称为形式参数
- 调用者调用函数时发送的对象是实际参数。
在 python 中,参数传递遵循标准赋值语句的语法。当调用一个函数时,在函数的局部范围内,每个标识符将作为一个形式参数被赋值给该函数的调用方提供的相应的实际参数。
例如,考虑以下来自前面 count 函数的调用:
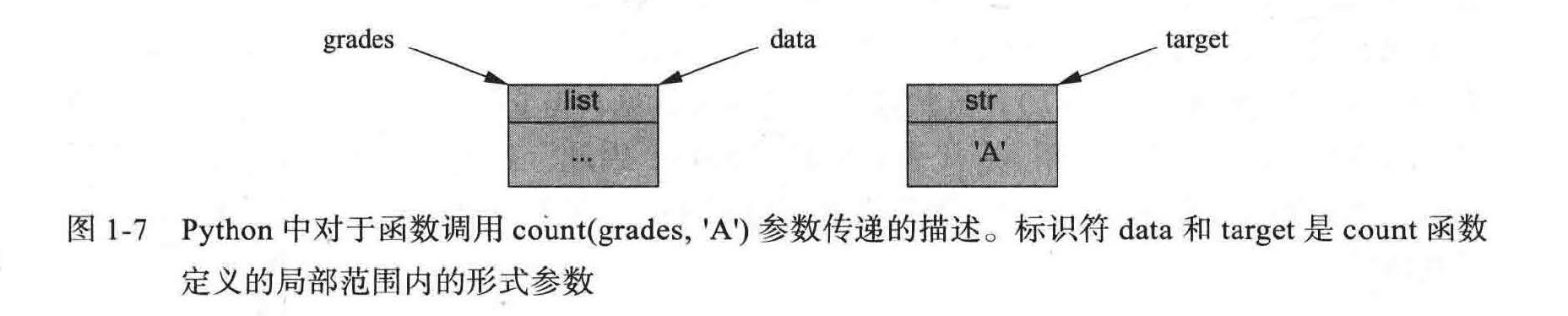
prizes = count(grades,'A')
在执行函数体之前,实际参数 grades 和 'A' 已经被隐式分配给了形式参数 data 和 target。代码如下:
data = grades
target = 'A'
这些赋值语句将标识符 data 作为 grades 的别名,并将 target 作为字符串 'A' 的别名,如图 1-7 所示。
函数的返回值传递给调用者这一实现类似于赋值。因此,我们的示例调用 prizes = count(grades,'A'),在调用者作用域内的标识符 prizes 赋值给了对象,此对象就是函数体中返回语句确定的 n
可变参数¶
当一个参数是可变对象时, python 的参数传递模式有其他作用。因为形参是实际参数的一个别名,函数体与对象的交互或许会改变它的状态
-
考虑对于示例 count 函数的调用,如果函数体执行
data.append('F')这条命令,新的条目被添加到函数中 data 列表的末尾,这改变了被调用者所知的相同的列表,比如 grades -
但是,在函数体内给形式参数重新赋予新值,形如设置 data = [],并不改变实际参数——这种重新赋值的方式只是改变了别名。
仔细想想,给实际参数(在这个例子中是列表 grade)添加一个新的内容似乎违背了我们设计 count 函数的初衷,对参数有这样一个意想不到的影响将是相当糟糕的设计。然而,在许多合法的情况下,一个函数可以被设计(和清楚地记录)用以修改参数的状态
- 作为一个具体的例子,我们提出实现一个名为
scale的方法,主要的目的是给数据集中的所有数都乘上一个给定的因子。
def scale(data, factor).
for j in range(len(data))
data[j] *= factor
默认参数值¶
python 可以通过多种不同的方式来调用某些特殊的函数签名(这样的函数被称为“多态的”)
- 最值得注意的是,函数可以为参数声明一个或多个默认值,从而允许调用方用不同个数的实际参数调用函数。例如,如果一个函数用下列签名来声明
def foo(a, b = 15, c = 27):
在这个函数签名中,事先声明了两个默认值—— b = 15,c = 27;调用者可以使用下面不同的方法来调用这个函数
- 调用方可以提供三个实际参数,如 foo(4 ,12, 8) 。在这种情况下,事先设定的默认值会被替换为调用者输入的实际参数—— b = 15,c = 8
- 如果调用方只能提供一个参数 foo(4),该函数将以参数值 a = 4 、b = 15 、c = 27 执行
- 如果调用方提供两个参数,那么这两个参数被假定赋给形式参数的前两位,形式参数的第三位还是取默认值。因此, foo(8, 20) 将以参数值 a = 8 、b = 20 、c = 27 执行
- 注意,形如
bar(a, b = 15, c)的签名,其中 b 具有默认值而后续的 c 没有默认值,使用这样的签名定义函数是不合法的。如果一个默认的参数具有参数值,那么它后面的参数也必须具有默认值。
作为一个使用默认参数的更加深入的例子,我们重新计算一个学生平均绩点( GPA ) 的任务(见代码段 1 -1) 。不是假设与控制台进行直接的输入和输出,我们希望设计一个函数,这个函数用于计算并返回一 个 GPA
- 我们设计了一个
compute_gpa函数,如代码段 1 -2 所示,它允许调用者指定自定义的等级到值的映射,同时提供标准的系统默认值。
def compute_gpa(grades, points={ 'A+' :4.0, 'A' :4.0,'A-' :3.67, 'B+' :3.33,'B' :3.0, 'B-' :2.67,'C+' :2.33,'C':2.0,'C' :1.67, 'D+' :1.33,'D' :1.0, 'F' :0.0})
num_courses = 0
totaLpoints = 0
for g in grades:
if g in points:
num_courses += 1
totaLpoints += points[g]
return totaLpoints / num_courses
作为有趣的多态函数的另外一个示例,我们考虑 python 对 range 的支持。( 从技术上讲,这是一个 range 类的构造函数, 但是为了讨论这个问题,我们可以把它当作一个纯函数来对待。)
python 对于 range 支持三种调用语法
- 单参数的形式,如
range(n),产生一个从 0 到 n 但不包含 n 的整数序列 - 两个参数的形式,如
range(start, stop),生成从 start 开始到 stop 结束但不包含 stop 的整数序列 - 三个参数的形式,如
range(start, stop, step), 生成一个类似于 range(start, stop) 的序列,但序列增量的大小是 step 而不是 1
这种形式的组合似乎违反了默认参数的规则。特别是当只有单参数时,如 range(n) ,它作为一个 stop 值(这是第二个参数) 。在这种情况下, start 的有效值是 0 。然而,这种效果可以用一些手法来实现,代码如下:
def range(start, stop = None, step = 1)
if stop is None:
stop = start
start = 0
...
从技术角度来看,当 range(n) 被调用时,实际参数 n 将被赋值给形式参数 start 。在函数体内, 如果只接收到一个参数, start 和 stop 的值将会重新被赋值以提供所需的语义
关键字参数¶
python 支持另一种将关键宇参数传递给函数的机制。关键字参数是通过显式地按照名称将实际参数赋值给形式参数来指定的
- 例如,对于函数签名 foo(a = 10,b =20,c = 30) 来说,调用 foo(c = 5) 将以参数 a = 10 、b = 20 、c = 5 的形式执行
在 python 标准库中会看到唯一关键字参数的几个重要的用法。例如,内置的 max 函数接收一个名为 key 的关键字参数,可以用来改变使用的“最大”的概念。
- 默认情况下, max 运算符是根据<操作符对元素的自然顺序进行操作的。但是最大的数可以通过比较元素的其他方面得出。例如,如果有兴趣寻找绝对值最大的一个数( 即考虑 -35 要大于 20) ,我们可以调用语法
max(a, b, key = abs) - 在这种情况下,内置的 abs 函数本身就是传递与关键字参数 key 相关联的值(在 python 中函数是第一类对象,参见 1.10 节)
- 在这种方式下调用 max 函数,它会比较 abs(a) 和 abs(b) ,而不是 a 和 b
1.5.2 python 的内置函数¶
表 1-4 列出了 python 中自动可用的常见函数,包括前面讨论的 abs 、max 和 range 。
- 标识符 x 、y 、z 表示任意数值类型
- k 代表整数
- a 、b 和 c 表示任意可比较类型
- 用标识符 iterable 代表任何可迭代类型的一个实例(如 str 、list 、tuple 、set 、diet)
- 序列代表可索引类的一个更窄的范畴, 包含 str 、列表和元组,但不包含集合和字典

上表根据函数的功能将其分为下面几类
- 输入/输出: print 、input 和 open 函数,细节参见 1.6 节的内容。
- 字符编码: ord 和 chr 将字符和其对应的整型编码关联起来。如 ord('A')的值是 65 , chr(65) 的值是 'A' 。
- 数学: abs 、divmod 、pow 、round 和 sum 提供了通用的数学功能。1.11 节介绍了一个额外的数学模块
- 排序: max 和 min 适用于支持比较概念的任何数据类型或这些值的任何集合。同样,从已存在的集合中抽取元素, 可以使用 sorted 生成排序的列表
- 集合/ 迭代: range 产生一个新的数字数列; len 得到任何现有集合的长度;函数 reversed 、all 、any 和 map 操作任意的迭代类型; iter 和 next 通过集合中的元素对迭代提供一个总体框架, 参见 1.8 节相关内容。
1.6 简单的输入和输出¶
在本节中,我们会谈到 python 语言中输入和输出的基本知识,并描述通过用户控制台来实现标准输入和输出,以及对读写文本文件的支持。
1.6.1 控制台输入和输出¶
print 函数¶
print 函数( python 语言中的内置函数)用来生成标准输出到控制台。在其最简单的形式中,它可以打印任意序列的参数
- 多个参数之间以空格作为分隔,末尾有一个换行符。例如,命令
print('maroon', 5)就是输出字符串 'maroon 5\n' - 注意: 这些参数也可以不是字符串实例, 一个非字符串参数 x 也将会以 str(x) 的形式显示。要是没有任何参数,命令 print() 输出的就是单个的换行符。
print 函数可以使用下列关键字参数进行自定义(参照 1.5 节对关键字参数的讨论) :
- 默认情况下, print 函数在输出时会在每对参数间插入空格作为分隔,其实可以通过关键字参数 sep 自定义想要的分隔符以分隔字符串。例如,用冒号分隔可以使用
print(a, b, c, sep= ':')。分隔字符串不需要一定用单个字符,它可以是一个长的字符串,当然,它也可以是一个空串,如 sep = '',这样可使得这些参数直接相连 - 默认情况下,在最后一个参数后会输出换行符。使用关键字参数 end 可以指定一个可选择的结尾字符串。指定空字符串 end= '',这样结束后不输出任何字符
- 默认情况下, print 函数会直接将输出发送到标准控制台。然而,通过使用关键字参数
file指示一个输出文件流(参见 1.6.2 节), 也可以直接输出到一个文件
input 函数¶
input 是一个内置函数,它的主要功能是接收来自用户控制台的信息
-
如果给出一个可选参数,那么这个函数会显示提示信息,然后等待用户输入任意字符, 直到按下返回键——这个函数的返回值是按下返回键之前用户所输入的字符串( 即换行符不存在于返回值中)(返回值一定是字符串类型)
-
可以通过强制类型转换来将输入的字符串转换为想要的 int 或者 float 类型
如果 response = input(),用户输入字符串 '2013' ,那么 int(response) 可以得到整型值 2013 。将这些操作和语法结合起来是很常见的,例如,
year = int(input('In what year were you born?'))
因为 input 函数会返回一个字符串作为结果,如附录 A 中所述,该函数的使用可以与 string 类的现有功能相结合。例如,如果用户在同一行上输入多个信息,则通常会对结果调用 split 方法,即
reply = input('Enter x and y, separated by spaces:')
pieces = reply.split() # returns a list of strings, as separated by spaces
x = float(pieces[O])
y = float(pieces[l])
示例程序
age = int(input('Enter your age in years:'))
max_ heart_rate = 206.9 - (0.67 * age) # as per Med Sci Sports Exerc
target = 0.65 * max_heart_rate
print('Your target fat-burning heart rate is' , target)
1.6.2 文件¶
在 python 中访问文件要先调用一个内置函数 open, 它返回一个与底层文件交互的对象
- 例如,命令
fp = open('sample. txt')用于打开名为 sample.txt 的文件,返回一个对该文本文件允许只读操作的文件对象
open 函数的第二个可选参数是确认对文件的访问权限, 默认权限 'r' 是只读。其他常见权限如 'w' 是对文件进行写操作(会覆盖当前文件之前的内容), ‘a’ 是对当前文件的尾部追加内容。
- 尽管我们对文本文件的使用比较关注,但使用 'rb' 或者 'wb' 也可以对二进制文件进行访问。
在处理一个文件时,文件对象使用距离文件开始处的偏移量(以字节为单位)维护文件中的当前位置
- 当以只读权限 'r' 或只写权限 'w' 打开文件时,初始位置是 0;如果是以追加权限 'a' 打开,初始位置是在文件的末尾
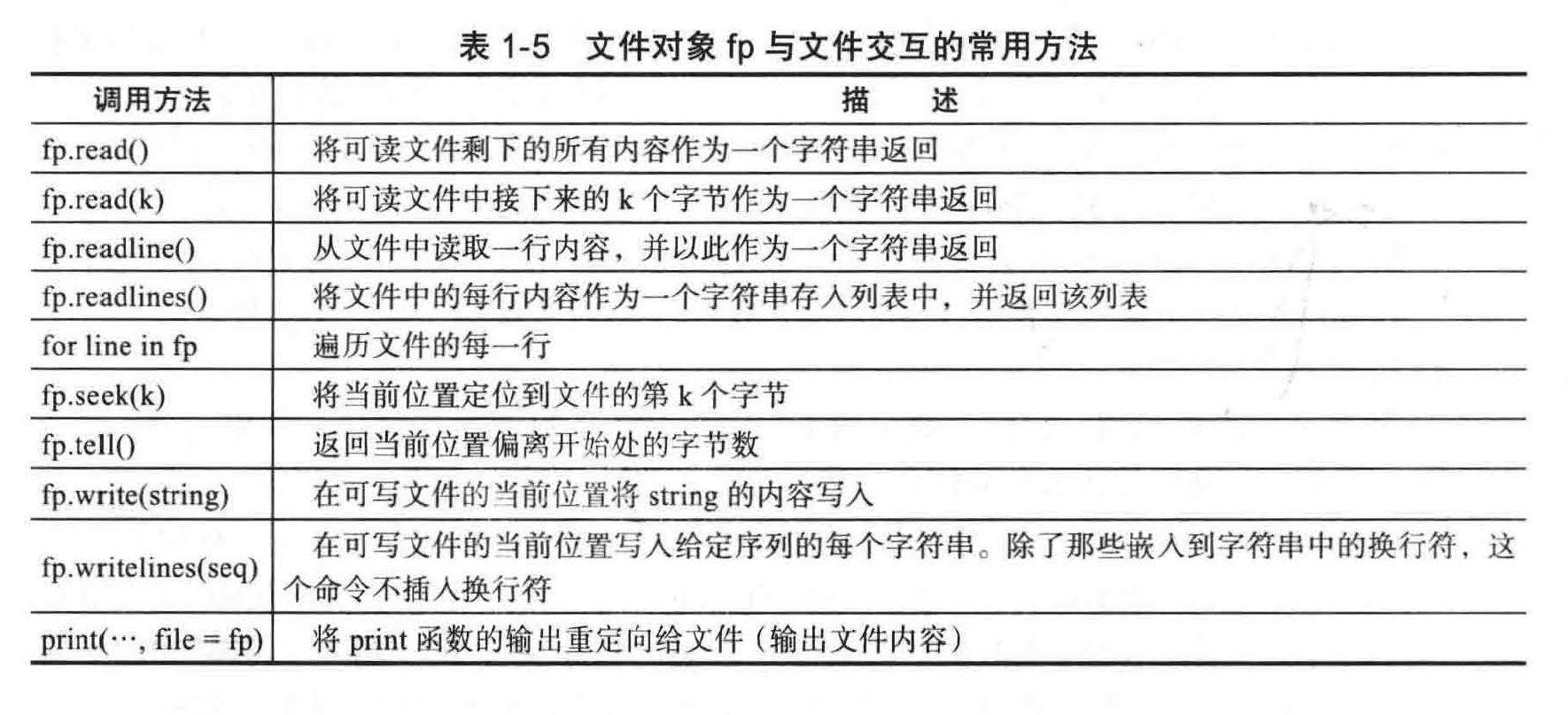
fp.close() 会关闭与文件对象 fp 相关的文件,确保写入的内容已被保存。读写文件的常用方法见表 1-5 。
读文件¶
通过文件对象读取文件最基本的命令是 read 方法。
- 当使用
fp.read(k)命令时,将返回从文件当前位置开始后继的 k 个字节 - 如果没有参数,即形如
fp .read(),则返回文件当前位置后的全部内容。
文件也可以一次读取一行,使用 readline 方法或者 readlines 方法将剩余的每一行以列表方式返回
- 文件也支持 for-loop 操作,即逐行遍历(例如
for line in fp)
写文件¶
当文件对象是可写的,例如,以写权限 'w' 或追加权限 'a' 创建一个文件时,就可以使用 write 方法或 write lines 方法。
- 例如,如果现在定义
fp = open('results .txt' , 'w'),执行fp .write('Hello World.\n')就是将给定字符串在文件中单独写一行。 - 注意: 在写文件时,它不会自动在尾部追加换行符。如果需要换行符,则必须将其写入字符串中
1.7 异常处理¶
异常是程序执行期间发生的突发性事件。逻辑错误或未预料到的情况都有可能造成异常。在 python 中,异常(也被称为错误)也是执行代码时遇到突发状况所引发(或抛出) 的对象。当遇到突发状况如内存溢出时, python 解释器也可以引发异常。如果在上下文中有 处理异常的代码,那么异常可能会被捕获。如果没有捕获,异常可能会导致解释器停止运行程序,并且向控制台发送合适的信息。
常见错误类型¶
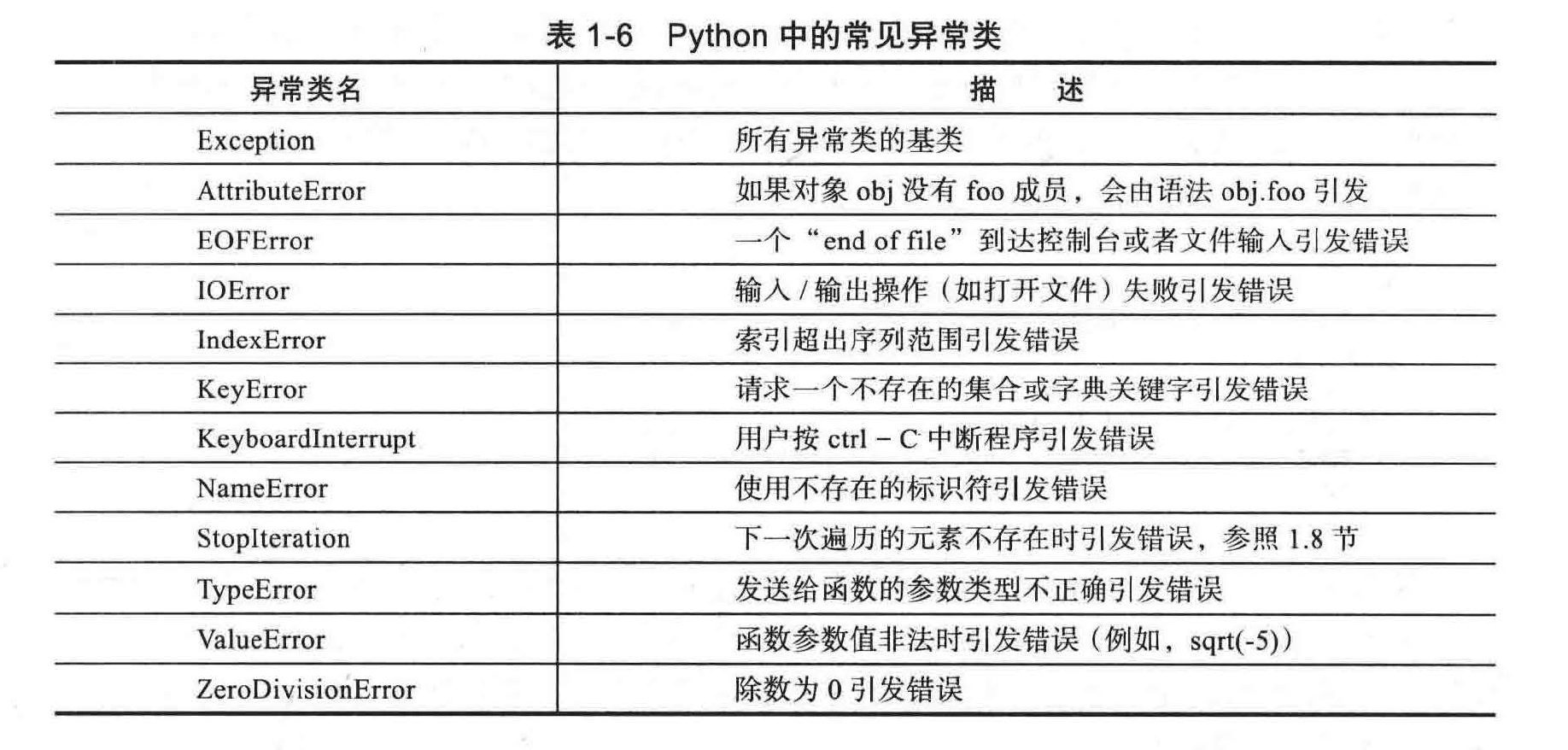
python 含有大量的异常类,它们定义了各种不同类型的异常。表 1-6 给出了一些常见的异常类。Exception 类是所有异常类的基类
各子类的实例都编码成已发生问题的细节。本章所介绍的异常案例就会引发一些异常。例如,在表达式中使用未定义的标识符会造成
NameError 异常,还有 ‘ . ’ 符号的错误使用,如 foo .bar(),如果对象 foo 没有 bar 成员,则会引发 AttributeError 异常
向函数发送一个错误的数字、类型或参数值是引发异常的另一个常见起因
- 例如,调用
abs('hello')就会引发TypeError异常,因为参数不是数字型的;调用abs(3, 5)也会引发TypeError异常,因为只允许一个参数。 - 如果传递参数的类型和数目都是正确的,但对于函数来说参数值是非法的,那就会引发
ValueError异常。例如, int 型构造函数可接收字符串,如int('137'),但如果字符串代表的不是整数,如int('3.14')或int('hello'),就会引发ValueError异常 - 当
data[k]中的 k 对于所给序列是一个非法的索引时, python 的序列类型(如列表、元组和 str 类)会引发IndexError异常。当试图访问一个不存在的元素时,集合和字典会引发KeyError异常
1.7.1 抛出异常¶
当执行到带有异常类的实例(其中以指定问题作为参数)的 raise 语句时,就会抛出异常。
- 例如,计算平方根的函数传递了一个负数作为参数,就会引发有如下命令的异常:
raise ValueError('x cannot be negative')
检查一个函数参数的有效性,首先要验证参数类型是否正确,然后再验证参数的值的正确性。例如,在 python 的 math 库中 sqrt 函数有错误检测,代码如下:
def sqrt(x):
if not isinstance(x, (int, float)) :
raise TypeError('x must be numeric')
elif x < 0:
raise ValueError('x cannot be negative')
#do the real work here ...
检测一个对象的类型可以在运行时使用内置函数 isinstance 来实现。在最简单的形式中,如果对象 obj 是 cls 类的一个实例或者是该类型的任何子类, isinstance(obj, cls) 会返回 True 。
要对函数执行多少次错误检测是一个有争议的问题。检查参数的类型和数值需要额外的执行时间,如果走向极端,似乎与 python 的本质不符。例如,内置函数 sum() 用于计算一系列数字的总和,其错误检测的实现如下:
def sum(values):
if not isinstance{values, collections.lterable):
raise TypeError('parameter must be an iterable type')
total = 0
for v in values:
if not isinstance(v, (int, float)):
raise TypeError{'elements must be numeric')
total = total+ v
return total
- 抽象基类
collections.lterable包括所有确保支持 for 循环语法的 python 迭代容器类型(如 list 、tuple 、set) 。
该函数更直接、更清晰的实现如下:
def sum(values):
total = 0
for v in val ues:
total = total + v
return total
有趣的是,上面的代码不仅实现了与内置函数 sum() 类似的功能,异常代码也会在相似的情况下抛出,特别是,如果 values 不是一个迭代类型,尝试使用 for 循环则会引发 TypeError, 同时报告该对象是不可迭代的。在用户传递了一个包括非数字化元素的迭代类型的情况下,如 sum([3. 14 , 'oops']),计算表达式 total + v 则自然会引发一个 TypeError 异常,然后向调用者发送错误信息
unsupported operand type(s) for +:'float'and'str'
- 稍微不那么明显的错误来自
sum(['alpha', 'beta'])。当 total 初始化为 0 后,由于表达式 total + 'alpha' 的初始计算,则会报告整数与字符串相加是一个错误的尝试。
1.7.2 捕捉异常¶
有一些关于写代码时如何应对可能出现的异常情况的观点。例如,在计算除法 x/y 时,有一定的风险, 当变量 y 为 0 时,引发ZeroDivisionError 异常。在理想情况下,如果程序的逻辑可以表明 y 是非零的,那么就不用担心错误。然而,对于更复杂的代码,或在 y 的值取决于一些外部输入的程序的情况下,仍有发生错误的可能性。
想要完全避免异常发生,则要使用积极的条件测试。重温除法的例子,我们可以通过如下写法来避免异常发生:
if y != 0.
ratio = x / y
else:
... do something else ...
第二个理念通常被 python 程序员所接受,就是 “ 请求原谅比得到许可更容易" 。这句话是计算机科学的先驱 Grace Hopper 提出来的。该观点是指我们不需要花费额外的时间来维护每一个可能发生的异常,只要异常发生时,有一个处理问题的机制就可以了
- 在 python 中,这一理念是使用
try-except控制结构来实现的。回顾除法的例子,确保运算正确的代码如下:
try
ratio = x / y
except ZeroDivisionError:
... do something else ...
在这种结构中, try 块中的代码是要执行的,虽然这个例子中只有一条命令,不过更多的是一个较大块的缩进代码。try 块后面会跟着一个或多个 except 子句,如果 try 块中引发了指定的错误,确定的错误类型和缩进代码块都要被执行。
使用 try-except 结构的相对优势是,非特殊情况下高效运行,不需要多余的检查异常条件。然而,在处理异常情况时,使用 try-except 结构比使用一个标准的条件语句会需要更多的时间。为此, 当我们有理由相信异常情况是相对不可能的,或主动评估条件来避免异常代 价异常高时,最好使用 try-except 语句
- 当用户输入时或读取文件时,异常处理是非常有用的,因为有一些情况是不可预测的。在 1.6.2 节中,我们推荐用语法
fp = open('sample.txt')以读取访问权限打开文件。该命令可能因为多种原因引发 IOError , 如一个不存在的文件, 或者缺乏足够的权限打开文件等。显然,尝试输入命令然后捕捉错误结果比准确预测命令是否成功会更容易
下面是另外一个例子
try:
fp = open('sample . txt')
except IOError as e:
print('Unable to open the file:', e)
在上面的例子中,我们同时为异常对象 IOError 建立了一个标识符
- 在这种情况下,名称 e 表示抛出异常的实例,输出并显示详细的错误消息(如“文件未找到“) 。
一个 try 语句可能处理不止一种类型的异常。例如 1.6.1 节中的命令:
age = int(input('Enter your age in years:'))
这个命令可能因为各种各样的原因而出错。如果控制台输入出错,那么调用 input 命令会抛出 EOFError 。如果调用 input 成功完成,但是用户没有输入表示一个有效整数的字符,那么 int 构造函数会抛出 ValueError。如果想要处理两个或两个以上类型的错误,我们可以使用一个 except 语句,像下面的例子:
age = -1 # an initially invalid choice
while age <= 0:
try:
age = int(input('Enter your age in years:'))
if age <= 0:
print('Your age must be positive')
except (ValueError, EOFError)
print('Invalid response')
我们希望使用 except 语句来捕获异常,使用元组 (ValueError, EOFError) 来指定错误类型
-
在这个实现中,我们捕获一个错误,就会输出一个响应,并继续 while 循环(直到没有错误才会终止)。我们注意到,当一个错误发生在 try 块中时,剩下的语句会直接跳过。在这个例子中,如果在调用 input 中出现异常或在后续调用 int 构造函数时发生异常,那么 age 就不会被赋值,也不会输出你的年龄必须是正数的信息。
-
如果希望在不输出 'Invalid response' 的清况下继续 while 循环,我们可以写入 except 语句:‘
except (ValueError, EOFError)
pass
关键词 pass 仅仅是一个声明,但它可以作为一种控制结构的主体。这样,我们就“悄悄“地捕获异常,从而允许 while 循环继续。
为了对不同类型的错误提供不同的响应,我们可以使用两个或两个以上 except 语句作为 try 结构的一部分。
- 在前一个例子中, EOFError 表明不可逾越的错误不仅仅是输入了一个错误值。在这种情况下,我们希望能提供更准确的错误信息,或者是允许异常能中断循环并传达给上下文。我们可以通过以下方法实现:
age = -1 # an initially invalid choice
while age <= 0:
try:
age = int(input('Enter your age in years:'))
if age <= 0:
print('Your age must be positive')
except ValueError
print('That is an invalid age specification')
except EOFError:
print('There was an unexpected error reading input.')
raise # let 1's re- raise this exception
在这个实现中,对于 ValueError 和 EOFError 情况,我们有单独的 except 语句。处理 EOFError 的语句体依赖于 python 中的另一种技术。它使用 raise 语句且没有其他后续参数来重新抛出相同的目前正在处理的异常。这使我们对异常能提供自己的响应,然后中断 while 循环并向上传播。
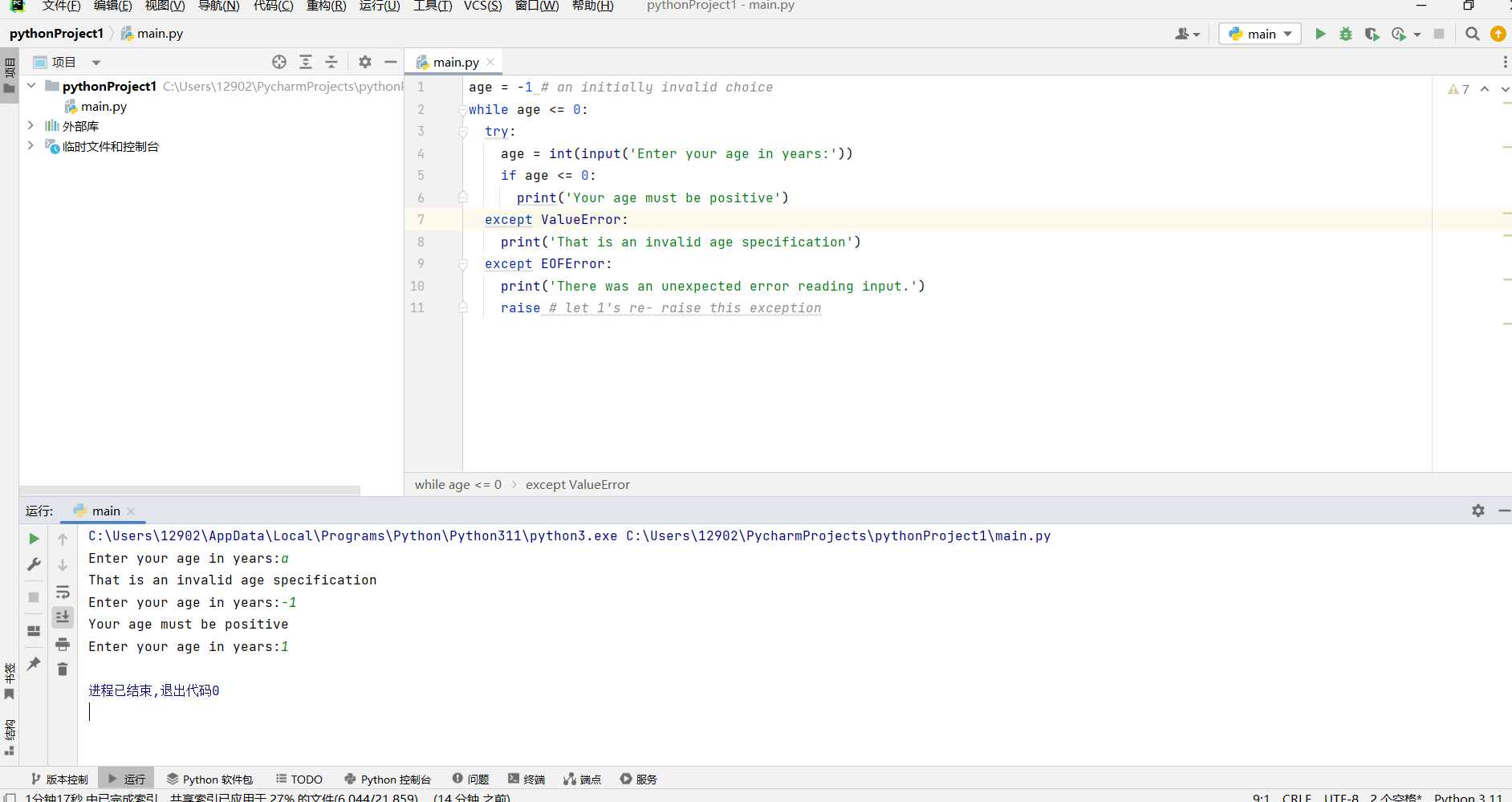
最后,我们注意到 python 中 try-except 结构的另外两个特征。它允许最后一个 except 语句不加特定的错误类型,直接使用 “except:" 来捕获一些其他异常,不过这种技术比较少用,因为对于如何处理一个未知类型的异常是比较困难的。
- 一个 try 语句允许有
finally子句,这个子句中的代码总是会被执行,无论是在正常情况下还是在异常情况下,甚至是未捕获异常 或重复抛出异常的情况下。通常该代码块是用于清理工作的,如关闭一个文件。
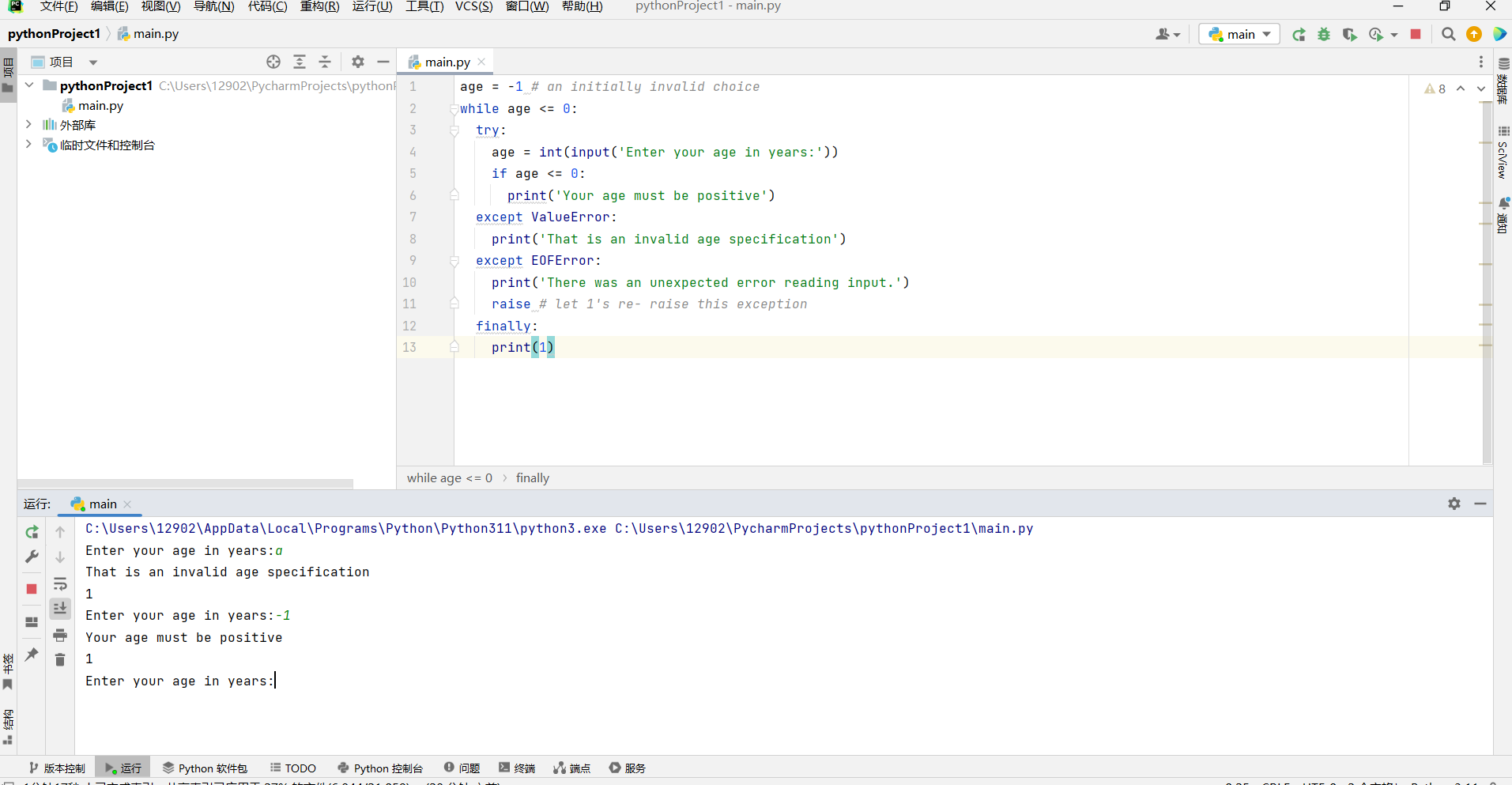
如上图,可以看到每次输入(无论正确还是错误都会输出一个 1)
1.8 迭代器和生成器¶
我们注意到, python 中有许多类型的对象可以被定义为可迭代的,如列表、元组和集合,都可以定义为迭代类型。此外,字符串可以产生它的字符的迭代,字典可以生成它的键的迭代,文件可以产生它的行的迭代。用户自定义类型也可支持迭代。在 python 中,迭代的机制基于以下规定:
- 迭代器是一个对象,通过一系列的值来管理迭代。如果变量 i 定义为一个迭代器对象,接下来每次调用内置函数
next(i),都会从当前序列中产生一个后续的元素; 要是没有后续元素了, 则会抛出一个 StopIteration 异常。 - 对象 obj 是可迭代的,那么通过语法
iter(obj)可以产生一个迭代器
通过这些定义, list 的实例是可迭代的,但它本身不是一个迭代器。如 data= [1, 2, 4, 8],调用 next(data) 是非法的。然而,通过语法i = iter(data) 则可以产生一个迭代器对象,然后调用 next(i) 将返回列表中的元素
- for 循环语法使这个过程自动化,为可迭代的对象创造了一个迭代器,然后反复调用下一个元素直至捕获 Stoplteration 异常
一般情况下,基于同一个可迭代对象可以创建多个迭代器,同时每个迭代器维护自身演进的状态。
- 迭代器不存储自己列表的元素。相反,它保存原始列表的当前索引,该索引指向下一个元素
- 如果原始列表的内容在迭代器构造之后但在迭代完成之前被修改,迭代器将报告原始列表的更新内容
python 还支持产生隐式迭代序列值函数和类, 即无须立刻构建数据结构来存储它所有的值。
- 调用
range(1000000)不是返回一个数字列表,而是返回一个可迭代的 range 对象。 - 这个对象只有在需要的时候一次性产生百万个值。这样的懒惰计算法有很大的优势。在 range 的例子中,它允许执行“
for j in range(1000000):" 这样的循环形式,无须留出内存来存储一百万个值。
懒惰计算在 python 中的许多库中都用到了,例如, 字典类支持方法 keys()、values()和 items() ,它们分别在字典中产生所有 keys 、values 或 ( key, value ) 的“视图” 。这些方法没有一个能产生显式的结果列表,相反,产生的视图是基于字典的实际内容的可迭代对象。
- 从这样的迭代中而来的一个显式值的列表可以通过将迭代作为参数调用 list 构造器来快速构造,例如,语法
list(range(1000))会生成一个值为 0 ~ 999 的列表实例 - 语法
list(d.values())则会生成一个其元素基于字典 d 的当前值生成的列表
生成器¶
在 python 中创建迭代器最方便的技术是使用生成器。生成器的语法实现类似于函数,但不返回值
- 作为一个例子,考虑确定一个正整数的所有因子。例如,数字 100 有因子 1, 2, 4, 5, 10, 20, 25, 50, 100 。传统的函数可能会 产生并返回一个包含所有因子的列表,实现如下:
def factors(n): # traditonal function that computes factors
results = [] # store factors in a new list
for k in range(1,n + 1):
if n % k == 0: # d ivides evenly, thus k is a factor
results.append(k)#H add k to the list of factors
return results
# return the entire list
- 而生成器中计算这些因子的实现如下:
def factors(n): # generator that computes factors
for k in range(1,n + 1):
if n % k == 0: # divides evenly, thus k is a factor
yield k # yield this factor as next result
注意: 我们使用关键字 yield 而不是 return 来表示结果。这表明在 python 中,我们正在定义一个生成器,而不是传统的函数。
在同一实现中,将 yield 和 return 语句结合起来是非法的,一个没有返回参数的 return 语句也会导致生成器终止执行
如果一个程序员写了一个循环如 " for factor in factors(100):”,那么会创建一个生成器的实例;在每次循环迭代中, python 执行程序直到一个 yield 语句指出下一个值为止。
- 在这一点上,该程序是暂时中断的,只有当另一个值被请求时才恢复。当控制流自然到达程序的末尾时(或碰到一个零参数的 return 语句) ,会自动抛出一个
Stoplteration异常。
下面这个例子通过依赖不同构造中的多个 yield 语句,以及由控制的自然流决定的生成序列来显著提高生成器的运行效率
def factors(n):
k = 1
while k * k < n:
if n % k == 0.
yield k
yield n // k
k += 1
if k * k == n·
yield k
# while k < sqrt(n)
# special case if n is perfect square
我们应该注意到,这个生成器的实现与我们的第一个版本不同, 因为这些因子不是以严格递增的顺序产生的。例如, factors(100) 产生序列 1 , 100, 2, 50, 4, 25 , 5 , 20, 10
总之,我们在使用生成器而不是传统的函数时,总是强调懒惰计算的好处——只计算需要的数,并且整个系列的数不需要一次性全部驻留在内存中。事实上, 一个生成器可以有效地产生数值的无限序列。
- 作为一个例子,斐波那契数列是一个经典的数学序列、初始值为 0 , 接着值为 1 , 然后每个后续的值是前两个值的总和。因此,斐波那契数列以 0, 1, 1, 2, 3, 5, 8,13, … 开始。下面的生成器可以产生这个无穷级数。
def fibonacci():
a = O
b = 1
while True:
yield a
future = a + b
a = b
b = future
# keep going.
# report value, a, during this pass
# this will be next value reported
# and subsequent ly this
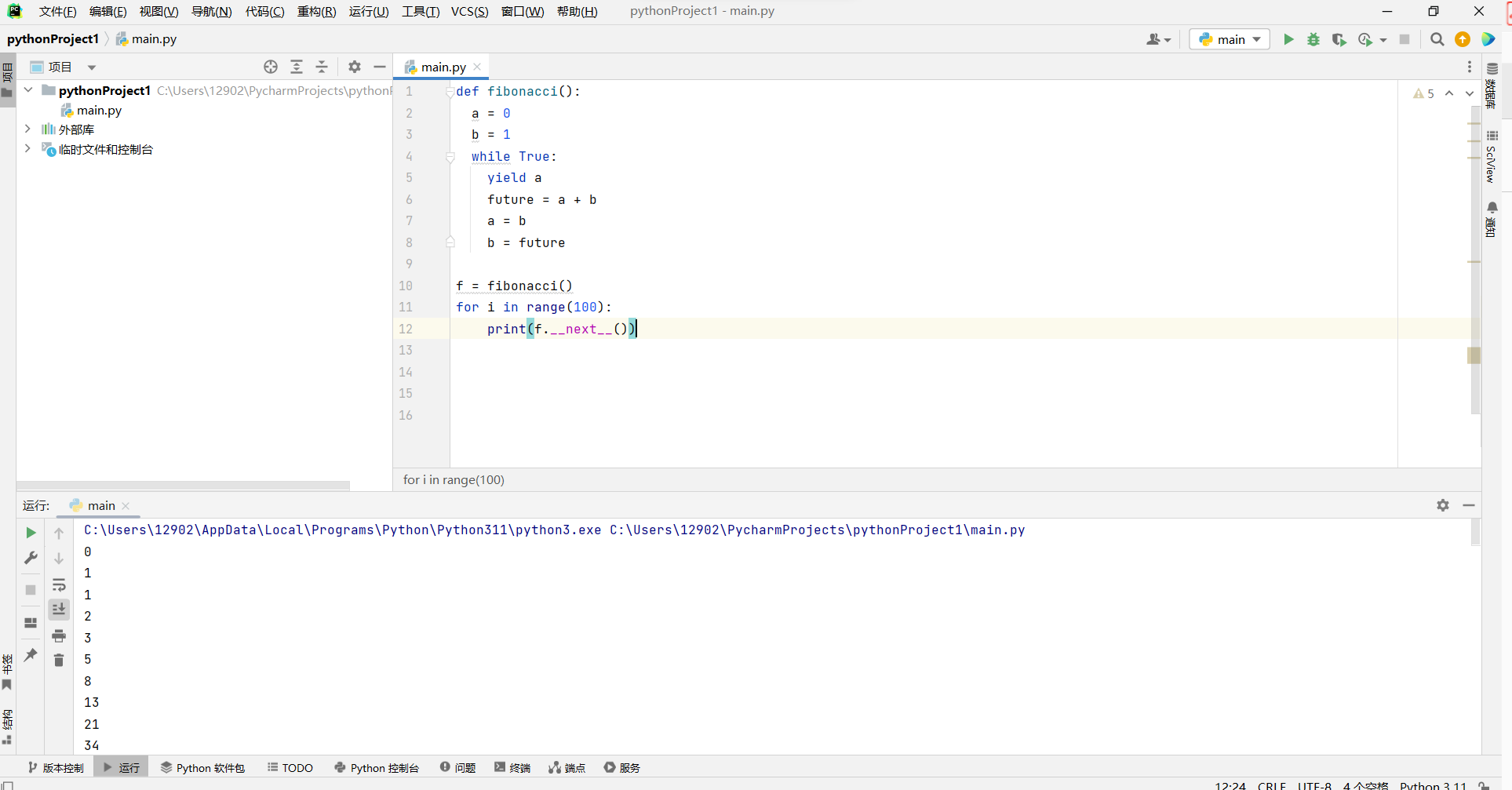
计算的飞快我只能说
1.9 python 的其他便利特点¶
在本节中,我们介绍 python 的若干特性,这些特性尤其便于编写清晰、简洁的代码。这些语法提供了一些功能,这些功能可以用本章前面提到的功能实现。不过, 有时候新语法会有更清晰和直接的逻辑表达。
1.9.1 条件表达式¶
python 支持条件表达式的语法,可以取代一个简单的控制结构。一般语法表达式的语法形式如下:
expr1 if condition else expr2
对于这种复合表达式, 如果条件为真, 则计算 expr1 ; 否则,计算 expr2 。这相当于 Java 或 C++ 中的语法 ” condition ? expr l : expr2 " 。
- 考虑这样一个例子,将变量 n 的绝对值传递给一个函数(不依赖内置函数 abs 的功能) 。若使用传统控制结构,可实现如下:
if n >= 0:
param = n
else:
param = - n
result = foo(param) # call the function
在条件表达式的语法中,我们可以直接给变量 param 赋值,如下所示:
param = n if n >= 0 else -n # pick the appropriate value
result = foo(param) i# call the function
事实上,没有必要将复合表达式赋值给变量。条件表达式本身就可以作为一个函数的参数,如下所示:
result = foo(n if n > = 0 else -n)
有时,缩短源代码是有好处的,因为它避免了更繁琐的控制结构。不过,我们建议仅当一个条件表达式能提高源代码的可读性,或者当两个选项的第一个是更“自然”的清况下,为了在语法上强调其重要性才使用。(我们希望当异常发生时可以查看变量的值)
1.9.2 解析语法¶
一个很常见的编程任务是基于另一个序列的处理来产生一系列的值。通常,这个任务在 python 中使用所谓的解析语法后实现很简单
- 我们先演示列表解析语法,因为这是 python 支持的第一种形式。它的一般形式如下:
[ expression for value in iterable if condition ]
注意到 expression 和 condition 都取决于 value, 而 if 子句是可选的。解析计算与下面的传统控制结构计算结果列表在逻辑上是等价的。
result = []
for value in iterable:
if condition:
result.append(expression)
举一个具体的例子,数字 1 ~ n 的平方的列表是 [ 1, 4, 9, 16, 25, …, n^2],这可以通过传统方式实现如下
squares = []
for k in range(1, n + 1):
squares.append(k * k)
使用列表解析,这个逻辑表达式的实现如下:
squares = [k * k for k in range(1, n + 1))
再举一个例子, 1.8 节介绍的求一个整数 n 的因子的列表,其使用列表解析的实现如下:
factors = [k for k in range(1,n + 1) if n % k == O]
python 支持类似的集、生成器或字典的解析语法。我们通过“计算数字的平方”的例子来比较这些语法。
[k * k for k in range(1, n + 1) ] 列表解析
{k + k for k in range(1, n + 1)} 集合解析
(k * k for k in range(1, n + 1)) 生成器解析
{k : k * k for k in range(1, n + 1) } 字典解析
当结果不需要存储在内存中时,生成器语法特别有优势。例如,计算前 n 个数的平方和,生成器语法total = sum(k * k for k in range(1, n + 1)) 是一种推荐的方法,该方法将列表作为参数使用。
1.9.3 序列类型的打包和解包¶
python 提供了另外两个涉及元组和其他序列类型的处理的便利。第一个便利是相当明显的。如果在大的上下文中给出了一系列逗号分隔的表达式,它们将被视为一个单独的元组,即使没有提供封闭的圆括号。例如,命令
data = 2, 4, 6, 8
会使标识符 data 赋值成元组 (2, 4, 6, 8) ,这种行为被称为元组的自动打包
在 python 中,另一种常用的打包是从一个函数中返回多个值。如果函数体执行命令
return x, y
就自动返回单个对象,也就是元组 (x,y)
作为一个对偶的打包行为, python 也可以自动解包一个序列,允许单个标识符的一系列元素赋值给序列中的各个元素。例如,我们可以这样写
a, b, c, d = range(7, 11)
这与 a= 7 、b = 8 、c = 9 和 d = 10 的赋值效果一样
- 对于这个语法,右边的表达式可以是任何迭代类型,只要左边的变量数等于右边迭代的元素数。
这种技术可以用来解包一个函数返回的元组。例如,内置的函数 divmod(a, b),返回这个整除相关的一对数值(a//b , a % b),尽管调用者可以认为返回值是一个元组,但也可以写成以下形式:
quotient, remainder = divmod(a , b)
来分别标识返回的元组中的两个值。这个语法也可以使用在 for 循环中
for x, y in [ (7, 2), (5, 8), (6, 4) ]
在这个例子中,循环将执行 3 次。第一次为 x = 7,y = 2, 然后以此类推。这种循环的风格常用于遍历由字典类的 item()方法返回的键值对,就像:
for k, v in mapping.items():
同时分配¶
自动打包和解包结合起来就是同时分配技术,即我们显式地将一系列的值赋给一系列标识符,所用语法为:
x, y, z = 6, 2, 5
实际上,该赋值右边将自动打包成一个元组,然后自动解包,将它的元素分配给左边的三个标识符。
- 当使用同时分配技术时,所有表达式都是在对左边的变量赋值之前先计算右侧,它提供了一种方便的方法,用来交换与两个变量相关联的值:
j , k = k, j
有了这个命令,原来的 k 值赋给 j ,原来的 j 值赋给 k 。如果没有同时分配技术,那么一个典型的交换需要使用一个临时变量,如:
temp = j
j = k
k = temp
使用同时分配技术可以大大简化代码演示。作为一个例子,我们考虑 1.8 节生成的斐波那契数列。原来的代码需要对序列开始的变量 a 和 b 初始化。在每一次循环中,其目标是给 a 和 b 分别赋予 b 和 a+ b 的值。当时我们完成这个目标时使用了第三个变量。有了同时分配技术, 生成器直接按以下方式实现:
def fibonacci():
a, b = 0, 1
while True
yield a
a, b = b, a+b
1.10 作用域和命名空间¶
当在 python 中以 x + y 计算两数的和时, x 和 y 这两个名称一定要与先前作为值的对象相关联;如果没有找到相关定义,会抛出一个 NameEorror 异常。确定与标识符相关联的值的过程称为名称解析。
每当标识符分配一个值,这个定义都有特定的范围。最高级赋值通常是全局范围,对于在函数体内的赋值,其范围通常是该函数调用的局部。因此, 函数体内的 x = 5 对外部函数标识符 x 没有影响。
python 中的每一个定义域使用了一个抽象名称,称为命名空间。命名空间管理当前在给定作用域内定义的所有标识符。图 1 - 8 描绘了两个命名空间, 一个是 1. 5 节调用 count 函数的命名空间,另一个是在函数执行过程中本地的命名空间
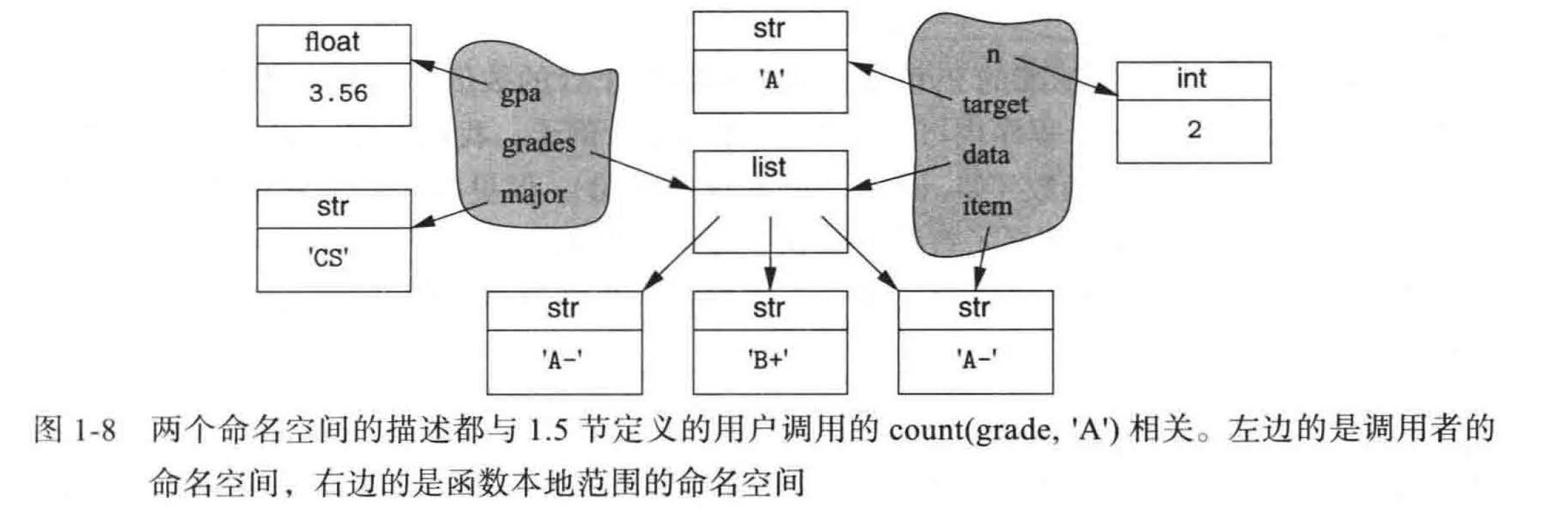
python 实现命名空间是用自己的字典将每个标识符字符串( 例如 'n' ) 映射到其相关的值。python 还提供了几种方法来检查一个给定的命名空间。函数 dir() 报告给定命名空间中的标识符的名称( 即字典的键),而函数 var() 返回完整的字典。默认情况下,调用 dir() 和 var()报告的是执行过程中本地封闭的命名空间
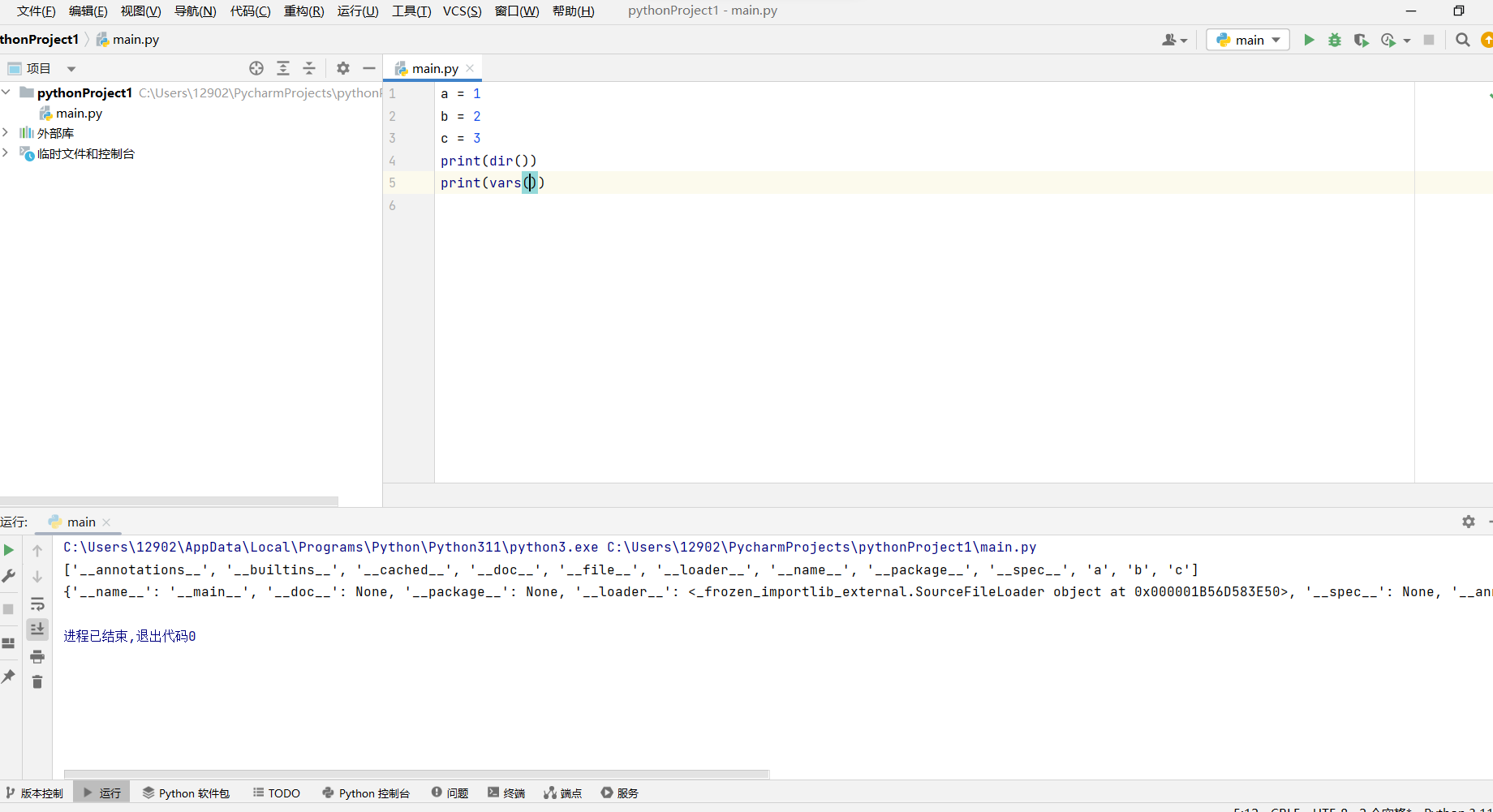
在命令中指示标识符时, python 会在名称解析过程中搜索一系列的命名空间。首先,搜索的是所给名字的本地命名空间,若没找到,则搜索外一层的命名空间,然后以此类推。
第一类对象¶
在编程语言的术语中,笫一类对象是一些可以分配给一个标识符的类型的实例, 可作为参数传递,或由一个函数返回。
- 函数和类也作为第一类对象处理。例如:
scream = print # assign name 'scream ' to the function denoted as ' print'
scream('Hello') # call that function
在这个例子中,我们没有创建新的函数,只是简单地将 scream 定义为现有 print 函数的别名
- 它说明了 python 允许一个函数作为参数传递到另一个函数的机制。
在之前计算最大值时,我们已经提到过这一概念——内置函数 max() 可接收一个可选的关键字参数去指定一个非默认的序列。例如, 调用者可以使用语法 max(a, b, key = abs) ,以确定哪个值有更大的绝对值。在该函数的主体中,形式参数 key 是将要赋值给实际参数 abs 的标识符。
就命名空间而言, 赋值语句如 scream = print 将标识符 scram 引入当前的命名空间,其值表示的是内置函数对象 print
- 同样的机制也可以应用在用户定义的函数声明中。例如,1.5 节的 count 函数的声明语法:
def count(data, target):
这样一个声明将标识符 count 引入了命名空间,它的值是一个表示其实现的函数实例。
1.11 模块和 import 语句¶
除了内置的定义外,标准的 python 分配包括数以千计的数值、函数以及被组织在附加库中的类(称为模块, 一个程序内可以导入) 。作为一个例子,我们考虑 math 模块。虽然内置命名空间包含一些数学函数( 如, abs 、min 、max 、round) ,但更多的是归为 math 模块( 如.sin 、cos 、sqrt) 。该模块还定义了数学常数 pi 和 e 的近似值。
python 的 import 声明可以将定义从一个模块载入当前命名空间。import 语句的语法形式如下:
from math import pi, sqrt
这个命令将在 math 模块定义的 pi 和 sqrt 添加到当前的命名空间,允许直接使用标识符 pi ,或调用函数 sqrt(2) 。
- 如果有许多定义来自导入的同一模块,则可以使用*,如
from math import*, 但这种形式应谨慎使用。危险在于,模块中定义的一些名称可能与当前命名空间中的名称冲突(或与导入的另一个模块冲突),而导入的模块会产生新定义去替换原有的定义。
另一种可以用于从相同模块访问许多定义的方法是导入模块本身,使用如下语法:
import math
同时将标识符 math 以及作为其值的模块引入当前的命名空间(模块在 python 中是第一类对象) 。
- 一旦引入,模块中的定义可以用一个完全限定的名称来访问,例如 math.pi 或者 math.sqrt(2) 。
创建新模块¶
要创建一个新模块,你只需要简单地把相关的定义放在一个扩展名为 .python 的文件里。这些定义可以从同一工程目录下的其他 .python 文件中导入
- 如果我们把计数函数的定义(见 1.5 节)放到 utility.python 文件中,那么可以使用语法
from utility import count来导入该 count 函数。
现有模块¶
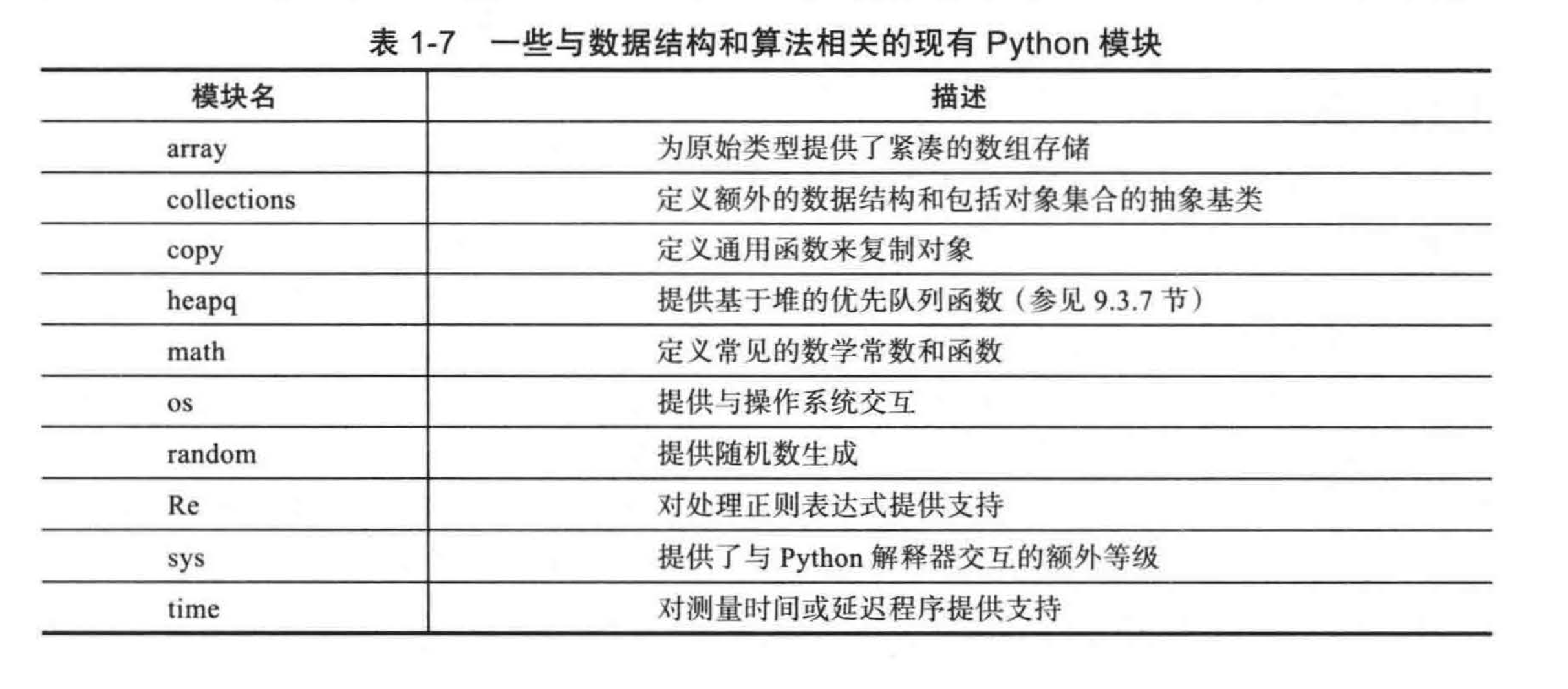
表 1 -7 给出了一些可用的与数据结构的研究相关的模块小结。之前我们已经简略地讨论过 math 模块了。在本节的其余部分,我们将重点介绍另一个对于我们在本书后面研究的一些数据结构和算法特别重要的模块。
伪随机数生成¶
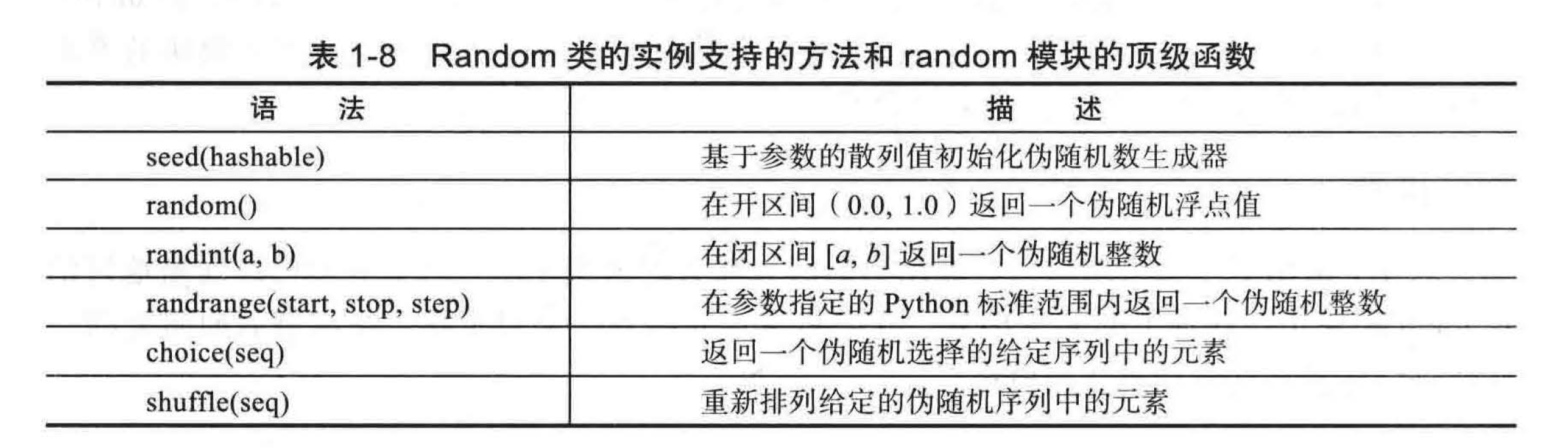
python 的 random 模块能够生成伪随机数,即数字是统计上随机的(但不一定是真正随机的) 。伪随机数生成器使用一个确定的公式来根据一个或多个过去数字生成的序列来产生下一个数
一个简单而流行的伪随机数生成器选择它的下一个数字是基于最近选择的数和一些额外的参数,所使用的公式如下:
next = (a*current + b) % n;
这里的 a 、b 和 n 是适当选择的整数。python 使用更先进的技术梅森旋转算法( Mersenne twister) 。事实证明这些技术所产生的序列是系统统一的,对于大多数需要随机数字的应用程序(比如游戏)通常是足够的。
- 对于应用程序,如计算机安全设置这样一个需要不可预测的随机序列的程序,就不应该使用这种公式。相反,我们需要真正随机的理想样本,如来自外太空的静态无线电。
由于伪随机数生成器中的下一个数是由前一个数决定的,这样的发生器总是需要一个开始的数字,这就是所谓的种子。一个给定的种子产生的序列将永远是相同的。要在每次程序运行时得到不同序列,一个常见的技巧是每次运行时使用不同的种子。例如,我们可以用来自某个用户输入的或当前以毫秒为单位的系统时间作为种子。
python 的 random 模块通过定义一个 Random 类支持伪随机数生成,这个类的实例作为有独立状态的生成器(见表 1-8) 。这允许一个程序的不同方面依靠自己的伪随机数生成器,因此,一个生成器的调用不影响由另一个生成器产生的数字的序列。
- Random 类支持的所有方法在 random 模块中都有支持的独立函数(基本上单个的生成器实例可用于所有的顶级调用) 。