第 2 章 面向对象编程
2.1 目标、原则和模式¶
顾名思义,面向对象模式中的主体被称为对象( object ) 。每个对象都是类(class) 的实例( instance ) 。类呈献给外部世界的是该类实例中各对象的一种简洁、一致的概括,没有太多不必要的细节,也没有提供访问类内部工作过程的接口
类的定义通常详细规定了对象包含的实例变量( instance variable ) ,又称数据成员(data member);还规定了对象可以执行的方法( methods) ,又称成员函数 (member function) 。
2.1.1 面向对象的设计目标¶
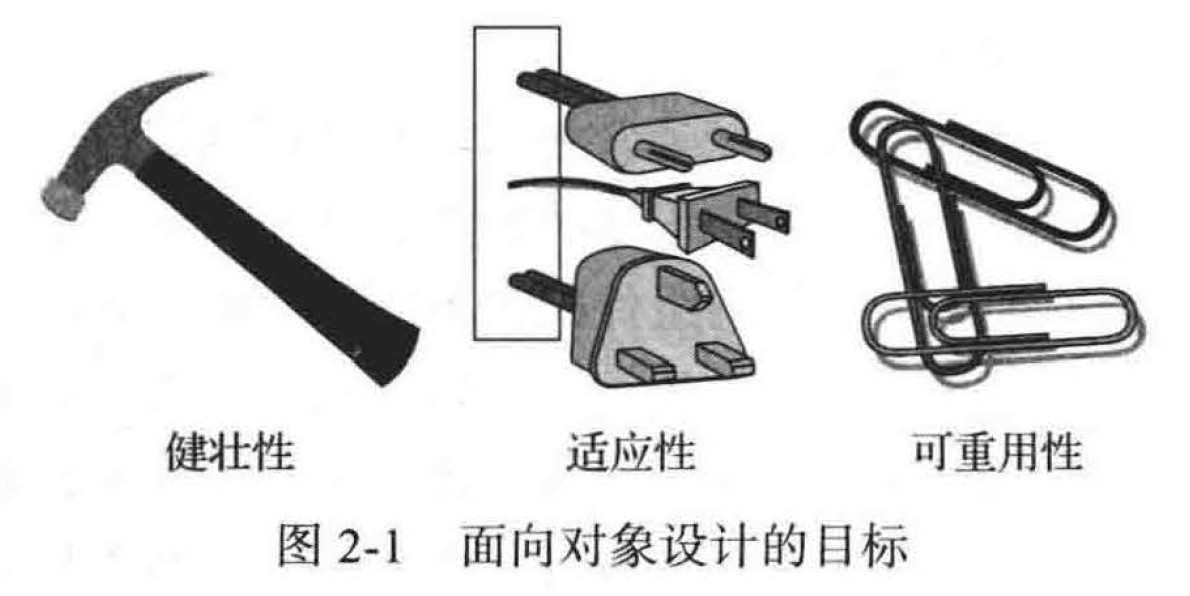
软件的实现应该达到健壮性(即鲁棒性)(robustness)、适应性(adaptability ) 和可重用性(reusability )目标,如图 2-1 所示
鲁棒性¶
每个优秀的程序设计者都想开发正确的软件,这就是说在应用程序中事先考虑到的所有输入都会产生一个正确的输出。除此之外,我们希望软件变得更健壮(robust) ,更确切地说,希望软件能处理我们在应用程序中没有明确定义的异常输入
- 例如,如果一个程序需要正整数(也许是代表一件商品的价格),然而却输入一个负整数, 那么这个程序需要“优雅“地从这个错误中恢复
更重要的是,不健壮的软件可能是致命的,比如在性命攸关的应用程序(life-critical application) 里,软件的一个错误可能会导致健康受损甚至丧命。
适应性¶
现代软件应用程序,比如网页浏览器和互联网搜索引擎,通常包含使用了多年的大型程序。软件需要随着时间不断地优化,以应对外部环境中条件的改变。于是,高质量软件的另一个重要目标是实现适应性( adaptability) (又称可进化性(evolvability ) )
可重用性¶
与适应性相似,我们希望软件也是可重用的,更确切地说,同样的代码可以用在不同系统的各种应用中。开发高质量软件的开销可能很昂贵,如果能把软件设计成高度可重用的,那么就会减少开发软件的开销。
2.1.2 面向对象的设计原则¶
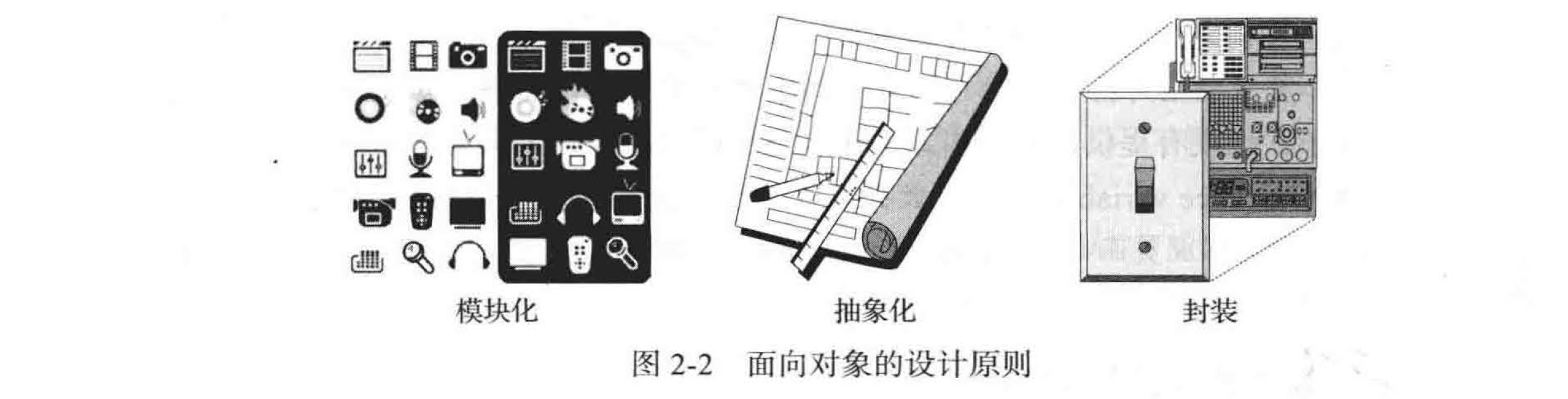
为了实现上述目标,面向对象方法的首要原则如下(见图 2-2 ):
- 模块化
- 抽象化
- 封装
模块化¶
现代软件系统通常包含一些不同的组件,为了使整个系统正常工作,这些组件必须正确地合作。恰当地组织这些组件,才能保证它们合作正常。模块化指的是一种组织原则,在这个原则中,不同的组件归为不同的功能单元
用现实世界作比, 一座房子或公寓可以视为由一些不同的相互作用的单元组成,比如电力系统、加热系统、冷却系统、水暖系统和建筑结构。有些人视这些系统为一大堆杂乱的电线、通风口、管道和板材,组织架构师则不然,他们设计房子和公寓时会将它们视为单独的模块,让这些模块在恰当的方式下相互作用。这样,他就能使用模块化的思想理出清晰的思路。这种思路提供了一个从组织功能到可管理单元的自然方法。
同样,在软件系统中采用模块化还可以为实施搭建清晰而强大的组织框架。我们巳经知道,在 python 中,模块(module) 是一个源代码中定义的密切相关的函数和类的集合。比如 python 标准库包括 math 模块,该模块提供了关键的数学常量和函数的定义,还包括提供了与操作系统的交互支持的 OS 模块
模块化的使用还有助于支持 2 .1.1 节中列出的目标。在形成大的软件系统之前,不同的组件是易于测试和调试的。此外, 一个完整系统中的错误可能会追溯到相对独立的特定组件中。因此,健壮性被大大地提高。
抽象化¶
抽象化(abstraction) 是指从一个复杂的系统中提炼出最基础的部分。通常,描述系统的各个部分涉及给这些部分命名和解释它们的功能。将抽象模式应用于数据结构的设计便产生了抽象数据类型(Abstract Data Types, ADT ) 。
ADT 是数据结构的数学模型,它规定了数据存储的类型、支持的操作和操作参数的类型。ADT 定义每个操作要做什么( what ) 而不是怎么做(how) 。我们通常参考 ADT 作为其公共接口( publ ic interface ) 所支持的行为的集合。
python 作为一种编程语言,提供了大量有关接口的说明。python 使用一种被称为鸭子类型的机制应对隐式抽象类型。
- 作为一种解释程序和动态类型的语言,在 python 中没有“编译时“检查数据类型,并且对于抽象基类的声明没有正式的要求。相反,程序员假设对象支持一系列已知的行为,如果这些假设不成立,解释程序将出现一个运行错误。
"鸭子类型 ” 这个概念来源于诗人 James Whitcomb Riley 的一句话:“ 当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
在 python 这类动态类型语言中,有一种风格叫做鸭子类型(duck typing)。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口决定的,而是由"当前方法和属性的集合"决定。这个概念最早来源于 James Whitcomb Riley 提出的“鸭子测试”,“鸭子测试”可以这样表述:“如果一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么它就可以被称为鸭子。”
在 python 中创建功能完善的序列类型无需使用继承,只需实现符合序列协议的方法。那么,协议又是什么呢?在面向对象编程中,协议是非正式的接口,只在文档中定义,不在代码中定义,可以看作是约定俗成的惯例。例如,python 的迭代器协议就包含
__iter__和__next__两个方法,任何实现了__iter__和__next__方法的类,python 解释器会将其视为迭代器,所有迭代器支持的操作,该类也会支持,譬如next()方法和for循环。用鸭子类型来解释就是:这个类看起来像是迭代器,那它就是迭代器。>>> from collections.abc import Iterator >>> class IterDuck: ... def __iter__(self): return self ... def __next__(self): return 1 ... >>> i = IterDuck() >>> issubclass(IterDuck, Iterator) True >>> isinstance(i, Iterator) True >>> next(i) 1由于实现了迭代器协议,上面代码中的 IterDuck 类甚至不需要显式的继承 Iterator 类,python 解释器就已经将它绑定为 Iterator 类的子类。
在鸭子类型中,关注点在于对象的行为,即提供的方法,而不在于对象所属的类型。
以序列协议为例
python 会特殊对待看起来像是序列的对象。序列协议包含
__len__和__getitem__两个方法。任何类,只要实现了__len__和__getitem__方法,就可以被看作是一个序列,即使这一次 python 解释器不再将其绑定为 Sequence 类的子类。由于序列的特殊性,如果你知道类的具体应用场景,甚至只需要实现序列协议的一部分。下面的代码演示了一个只实现了
__getitem__方法的类,对于序列操作的支持程度:尽管只实现了__getitem__方法,但 SeqDuck 实例却可以使用for循环迭代以及in运算符。>>> class SeqDuck: ... def __getitem__(self, index): ... return range(3)[index] ... >>> s = SeqDuck() >>> s[2] # __getitem__ 2 >>> for i in s: print(i) # __iter__ ... 0 1 2 >>> 2 in s # __contains__ True即使没有
__iter__方法,SeqDuck 实例依然是可迭代的对象,因为当 python 解释器发现存在__getitem__方法时,会尝试调用它,传入从 0 开始的整数索引进行迭代(这是一种后备机制)。同样的,即使没有__contains__方法,但 python 足够智能,能够迭代 SeqDuck 实例检查有没有指定元素。综上,鉴于序列协议的重要性,如果没有
__iter__和__contains__方法,python 会尝试调用__getitem__方法设法让迭代和in运算符可用
更正式地说, python 用一种称为抽象基类 (Abstract Base Class, ABC ) 的机制支持抽象数据类型。一个抽象基类不能被实例化(换言之,你不能直接创建该类的实例) ,但它规定了一个或多个常用的方法,抽象化的所有实现都必须包括该方法
- 通过从一个或多个抽象类中继承的具体类( concrete classes) 来实现 ABC , 同时提供由 ABC 声明这些方法的实现。
- 重写:指再写一遍,例如我们想要定义一个新的类,一般来说在类创建时已经使用了方法
__new__,我们不需要再次写(调用)这一方法
特殊方法
想要更深入地理解鸭子类型,必须要了解 python 中的特殊方法。前面我们提到的以双下划线开头和结尾的方法,比如
__iter__,就称为特殊方法(special methods),或称为魔法方法(magic methods)。python 标准库和内置库包含了许多特殊方法,需要注意的是,永远不要自己命名一个新的特殊方法,因为你不知道下个 python 版本会不会将其纳入到标准库中。我们需要做的,是重写现有的特殊方法,并且通常情况下,不需要显式的调用它们,应当使用更高层次的封装方法,比如使用
str()代替__str__(),对特殊方法的调用应交由 python 解释器进行。python 对于一些内置方法及运算符的调用,本质上就是调用底层的特殊方法。比如在使用
len(x)方法时,实际上会去查找并调用 x 对象的__len__方法;在使用for循环时,会去查找并调用对象的__iter__方法,如果没有找到这个方法,那会去查找对象的__getitem__方法,正如我们之前所说的这是一种后备方案。可以说,特殊方法是 python 语言灵活的精髓所在,下面我们结合鸭子类型中的 SeqDuck 类与特殊方法,尝试还原 python 解释器运行的逻辑。
class SeqDuck: def __getitem__(self, pos): return range(3)[pos]
- python 解释器读入 SeqDuck 类,对所有双下划线开头结尾的特殊方法进行检索。
- 检索到
__getitem__方法,方法签名符合序列协议。- 当需要对 SeqDuck 实例进行循环迭代时,首先查找
__iter__方法,未找到。- 执行
__getitem__方法,传入从 0 开始的整数索引进行迭代直至索引越界终止循环。该过程可以理解为 python 解释器对 SeqDuck 类的功能进行了运行时扩充。显然这增强了 python 语言的动态特性,但另一方面也解释了为什么 python 运行效率较低。
下面介绍了一些常用的特殊方法
__new__&__init__在 Java 和 C# 这些语言中,可以使用
new关键字创建一个类的实例。python 虽然没有new关键字,但提供了__new__特殊方法。在实例化一个 python 类时,最先被调用的就是__new__方法。大多数情况下不需要我们重写__new__方法,python 解释器也会执行 object 中的__new__方法创建类实例。但如果要使用单例模式,那么__new__方法就会派上用场。下面的代码展示了如何通过__new__控制只创建类的唯一实例。>>> class Singleton: ... _instance = None ... def __new__(cls): ... if cls._instance is None: ... cls._instance = object.__new__(cls) ... return cls._instance ... >>> s1 = Singleton() >>> s2 = Singleton() >>> s1 is s2 ## id(s1) == id(s2) True
__init__方法则类似于构造函数,如果需要对类中的属性赋初值,可以在__init__中进行。在一个类的实例被创建的过程中,__new__要先于__init__被执行,因为要先创建好实例才能进行初始化。__new__方法的第一个参数必须是cls类自身,__init__方法的第一个参数必须是self实例自身。>>> class Employee: ... def __new__(cls): ... print('__new__ magic method is called') ... return super().__new__(cls) ... ... def __init__(self): ... print ("__init__ magic method is called") ... self.name = 'Jack' ... >>> e = Employee() __new__ magic method is called __init__ magic method is called >>> e.name 'Jack'由于 python 不支持方法重载,即同名方法只能存在一个,所以 python 类只能有一个构造函数。如果需要定义和使用多个构造器,可以使用带默认参数的
__init__方法,但这种方法实际使用还是有局限性。另一种方法则是使用带有@classmethod装饰器的类方法,可以像使用类的静态方法一样去调用它生成类的实例。class Person: def __init__(self, name, sex='MAlE'): self.name = name self.sex = sex @classmethod def male(cls, name): return cls(name) @classmethod def female(cls, name): return cls(name, 'FEMALE') p1 = Person('Jack') p2 = Person('Jane', 'FEMALE') p3 = Person.female('Neo') p4 = Person.male('Tony')
__str__&__repr__str() is used for creating output for end user while repr() is mainly used for debugging and development. repr’s goal is to be unambiguous and str’s is to be readable.
__str__和__repr__都可以用来输出一个对象的字符串表示。使用str()时会调用__str__方法,使用repr()时则会调用__repr__方法。str()可以看作 string 的缩写,类似于 Java 中的toString()方法;repr()则是 representation 的缩写。这两个方法的区别主要在于受众。
str()通常是输出给终端用户查看的,可读性更高。而repr()一般用于调试和开发时输出信息,所以更加强调含义准确无异义。在 python 控制台以及 Jupythonter notebook 中输出对象信息会调用的__repr__方法。>>> x = list(("a", 1, True)) >>> x # list.__repr__ ['a', 1, True]如果类没有定义
__repr__方法,控制台会调用 object 类的__repr__方法输出对象信息:>>> class A: ... ... >>> a = A() >>> a # object.__repr__ <__main__.A object at 0x104b69b50>
__str__和__repr__也可以提供给__str__方法。>>> class Foo: ... def __repr__(self): ... return 'repr: Foo' ... def __str__(self): ... return 'str: Foo' ... >>> f = Foo() >>> f repr: Foo >>> print(f) str: Foo
__call__在 python 中,函数是一等公民。这意味着 python 中的函数可以作为参数和返回值,可以在任何想调用的时候被调用。为了扩充类的函数功能,python 提供了
__call__特殊方法,允许类的实例表现得与函数一致,可以对它们进行调用,以及作为参数传递。这在一些需要保存并经常更改状态的类中尤为有用。下面的代码中,定义了一个从 0 开始的递增器类,它保存了计数器状态,并在每次调用时计数加一:
>>> class Incrementor: ... def __init__(self): ... self.counter = 0 ... def __call__(self): ... self.counter += 1 ... return self.counter ... >>> inc = Incrementor() >>> inc() 1 >>> inc() 2允许将类的实例作为函数调用,如上面代码中的
inc(),本质上与inc.__call__()直接调用对象的方法并无区别,但它可以以一种更直观且优雅的方式来修改对象的状态。
__call__方法可以接收可变参数, 这意味着可以像定义任意函数一样定义类的__call__方法。当__call__方法接收一个函数作为参数时,那么这个类就可以作为一个函数装饰器。基于类的函数装饰器就是这么实现的。如下代码我在 func 函数上使用了类级别的函数装饰器 Deco,使得在执行函数前多打印了一行信息。>>> class Deco: ... def __init__(self, func): ... self.func = func ... def __call__(self, *args, **kwargs): ... print('decorate...') ... return self.func(*args, **kwargs) ... >>> @Deco ... def func(name): ... print('execute function', name) ... >>> func('foo') decorate... execute function foo实际上类级别的函数装饰器必须要实现
__call__方法,因为本质上函数装饰器也是一个函数,只不过是一个接收被装饰函数作为参数的高阶函数。有关装饰器可以详见装饰器一章。
__add__python 中的运算符重载也是通过重写特殊方法实现的。比如重载 “+” 加号运算符需要重写
__add__,重载比较运算符 “==” 需要重写__eq__方法。合理的重载运算符有助于提高代码的可读性。下面我将就一个代码示例进行演示。考虑一个平面向量,由 x,y 两个坐标构成。为了实现向量的加法(按位相加),重写了加号运算符,为了比较两个向量是否相等重写了比较运算符,为了在控制台方便验证结果重写了
__repr__方法。完整的向量类代码如下:class Vector: def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return f'Vector({self.x}, {self.y})' def __add__(self, other): return Vector(self.x + other.x, self.y + other.y) def __eq__(self, other): return self.x == other.x and self.y == other.y def __ne__(self, other): return not self.__eq__(other)在控制台验证结果:
>>> from vector import Vector >>> v1 = Vector(1, 2) >>> v2 = Vector(2, 3) >>> v1 + v2 Vector(3, 5) >>> v1 == v2 False >>> v1 + v1 == Vector(2, 4) True重载了 “+” 运算符后,可以直接使用
v1 + v2对 Vector 类进行向量相加,而不必要编写专门的add()方法,并且重载了==运算符取代了v1.equals(v2)的繁冗写法。从代码可读性来讲直接使用运算符可读性更高,也更符合数学逻辑。
封装¶
面向对象设计的另一个重要原则是封装(encapsulation) 。软件系统的不同组件不应显示其各自实现的内部细节。封装的主要优点之一就是它给程序员实现组件细节的自由,而不用关心其他程序员写的其他依赖千这些内部代码的程序。
- 封装提供了健壮性和适应性,因为它允许改变程序一部分的实现细节而不影响其他部分,因此,修复漏洞或者给组件中增加相对本地更改的新功能就变得更容易。
在这本书中,我们将遵循封装的原则,说明数据结构的哪些方面被认定为公共部分,哪些方面被认定为内部细节。也就是说, python 为封装提供了宽泛的支持。按照惯例,以单下划线开头的类成员(数据成员和成员函数)的名称(如,_secret) 被认定为非公开的,而且不应该被依赖。根据这些约定,自动生成文档时会忽略这些内部成员。
2.1.3 设计模式¶
面向对象的设计有助于实现健壮的、可适应的、可重用的软件。然而,设计好的代码不仅需要简单地理解面向对象的方法,更需要有效地利用面向对象的设计技术。为了设计高质量的、简洁的、正确的、可重用的面向对象软件,计算研究人员和从业人员巳经开发出多种组织的概念和方法。本书特别关注的是设计模式( design pattern ) 的概念,
- 模式包括一个名称(它标识了该模式)、一个语境(它描述应用该模式的情况)、一个模板(它描述如何应用该模式)以及一个结果(它描述和分析该模式会产生什么结果) 。
在本书中,我们介绍一些设计模式,同时展示它们如何被持续地应用于数据结构和算法的实现。这些设计模式被分为两组——解决算法设计问题的模式和解决软件工程问题的模式。所讨论的算法设计模式包括以下内容:
- 递归
- 摊销
- 分治法
- 去除法(减治法)
- 暴力算法
- 动态规划
- 贪心法
所讨论的软件工程模式包括以下内容:
- 迭代器
- 适配器
- 位置
- 合成
- 模板方法
- 定位方法
- 工厂模式
2.2 软件开发¶
传统的软件开发包括几个阶段。其中 3 个主要阶段如下:
- 设计。
- 实现。
- 测试和调试。
在本节中,我们将简要讨论这些阶段所扮演的角色,介绍在利用 python 编程时一些好的做法,包括编码风格、命名约定、文档和单元测试。
2.2.1 设计¶
对于面向对象编程,设计步骤也许是软件开发过程中最重要的阶段。因为在决定如何把程序的工作分成若干个的设计步骤中,我们决定这些类的交互方式、将要存储的数据和将要执行的功能。事实上,程序设计者刚开始面临的主要的挑战之一是决定用什么类去实现程序的功能。虽然一般的计划都很难总结,但这里有一些我们可以应用的经验规则,为确定如何设计类提供方便
- 责任(responsibility) :把这些工作分为不同的角色(actor) ,它们有各自不同的责任。试着用行为动词描述责任。这些角色将形成程序的类。
- 独立(independence) :在尽可能独立于其他类的前提下规定每个类的工作。细分各个类的责任,这样每个类在程序的某个方面上就有自主权。把数据作为那些需要控制和访问这些数据的类的实例变量。
- 行为(behavior) :仔细且精确地为每个类定义行为,这样与它进行交互的其他类可以很好地理解这个由类执行的动作结果。这些行为将定义该类执行的方法,并且,类的接口(interface) 是一系列类的行为,因为这些类构成了其他代码与类中对象交互的方法。
面向对象程序设计的关键是定义类和它们的实例变量及方法。随着时间的推移,一个好的程序设计者在执行这些任务时自然会探寻更好的技巧,就好像是经验在教他去注意项目需要的模式,该模式与他之前见过的模式相匹配
2.2.2 伪代码¶
作为在设计实现前的中间步骤,通常要求程序设计者通过一种专门为人准备的方法来描述算法。这种描述被称为伪代码(pseudo-code) 。伪代码不是计算机程序,但是比平常文章更加结构化。伪代码是自然语言和高级编程结构的混合,用于描述隐藏在数据结构和算法实现之后的主要编程思想。
在本书中,我们依靠伪代码样式,并使用数学符号和字母注释的组合,使得对于 python 程序设计者来说该伪代码风格是清晰的。例如,我们也许会用短语 “indicate an error" 代替正式的语句。遵循 python 的惯例,我们依靠缩进来表示控制结构的程度,依靠从 A[0] 到 A[n - 1] 的索引符号给长度为 n 的序列 A 编号。不过,在伪代码中,我们选择把注释放入大括号{ }中,而不是用 python 中的#字符。
2.2.3 编码风格和文档¶
程序应该被设计得易于阅读和理解。因此,好的程序设计者应该注意自己的编码风格,并且形成一种无论是对人还是计算机的交流都有好处的风格。编码风格的惯例在不同编程团体中是不同的。在网站 http: //www.python.org/ dev /peps/pep-0008/ 中可得到官方的 python 代码风格指南(Style Guide for python Code) 。
我们采取的主要原则如下:
- python 代码块通常缩进 4 个空格。但是,为了避免代码段超过本书的边界,我们以 2 个空格作为每一级的缩进。因为不同系统中以不同的宽度显示制表符,而且 python 解释器视制表符和空格是不同的字符,所以强烈建议避免使用制表符。许多能识别 python 语言的编辑器会自动用适量的空格代替制表符。
- 标识符命名要有意义。试着选择大家易于理解名字,选择能反映行为、责任或其命名的数据的名字。
- 类(不同于 python 的内置类)应该以首字母大写的单数名词(例如, Date 而不是 date 或 Dates ) 作为名字。当多个单词连接起来形成一个类的名字时,它们应该遵循所谓的"骆驼拼写法”规则。即在该规则中,每个单词的首字母要大写(例如 CreditCard) 。
- 函数,包括类的成员函数,应该小写。如果将多个单词组合起来, 它们就应该用下划线隔开(例如, make_payment) 。函数的名字通常应该是一个描述它的作用的动词。但是,如果这个函数的唯一目的是返回一个值,那么函数名可以是一个描述返回值的名词(例如, sqrt 而不是 calculate_sqrt)
- 标识某个对象(例如,参数、实例变量或本地变量) 的名字应该是一个小写的名词(例如, price ) 。有时候,当我们使用一个大写字母来表示一个数据结构的名称时,会不遵守这条规则(如 tree T) 。
- 传统上用大写字母并用下划线隔开每个单词的标识符代表一个常量值(例如,MAX_SIZE) 。
回顾我们讨论的封装,在任何情况下,以单下划线开头的标识符(例如, _secret ) 意在表明它们只为类或模块“ 内部“使用,而不是公共接口的一部分。
- 用注释给程序添加说明,解释有歧义或令人困惑的结构。内嵌的行注释有助于快速理解代码有好处。在 python 中,#字符后的内容表示注释,如:
if n % 2 == 1: # n is odd
多行注释块可以很好地解释更复杂的代码段。在 python 中,有专门的多行字符串,通常用三引号( """ )表示,这种注释对程序执行没有任何影响。在下一节中,我们将讨论使用块注释作为文档。
文档¶
python 使用一个称作 docstring 的机制为在源码中直接插入文档提供完整的支持。从形式上讲,任何出现在模块、类、函数(包括类的成员函数) 主体中的第一个语句的字符串都被认为是 docstring 。按照惯例,这些字符串应该限定在三引号(""")中。例如, 1.5 .1 节的缩放功能的版本可以有如下记录:
def scale(data, factor)
""" Mult iply all entries of numeric data list by the given factor."""
for 」in range(len(data))
data[j] *= factor
对于 docstring, 通常用三引号字符串分隔符,即使像上面例子中的字符串仅有 1 行。更详细的 docstring 应该以概述目的一行开头,接下来是一个空白行,然后是进一步的细节描述。例如,我们可以用如下方式更清楚地记录函数 scale 的信息:
def scale(data, factor).
""" Multiply all entries of numeric data list by the given factor.
data an instance of any mutable seque nce type (such as a list)
containing numeric elements
factor a number that serves as t he multiplicative factor for scaling
"""
for j in range(len(data))
data [i] *= factor
docstring 作为模块、功能或者类的声明的一个域进行存储。它可以作文档用,并且可以用多种方式检索。例如,在 python 解释器中,用命令 help(x) 会生成与标识对象 x 关联的文档 docstring 。还有一个名叫 pythondoc 的外部工具,该工具是 python 发行的,可以用于生成
文本或网页格式的正式文档。可在网站 http ://www.python.org/ dev /peps/pep-0257/ 中得到有用的 docstring 书写指南
2.2.4 测试和调试¶
测试是通过实验检验程序正确性的过程,调试是跟踪程序的执行并在其中发现错误的过程。在程序开发中,测试和调试通常是最耗时的一项活动
测试¶
详细的测试计划是编写程序最重要的部分。用所有可能的输入检验程序的正确性通常是不可行的,所以我们应该用有代表性的输入子集来运行程序。最起码我们应该确保类的每个方法都至少被执行一次(方法覆盖) 。更好的是,程序中的每个代码语句应该至少被执行一次(语句覆盖) 。
在特殊情况(special cases) 的输入下,程序往往会失败。需要仔细确认和测试这些情况。例如,当测试一个对整数序列排序的方法(即 sort) 时,我们应该考虑以下的输入:
- 序列具有零长度(没有元素) 。
- 序列有一个元素。
- 序列中的所有元素是相同的。
- 序列已排序。
- 序列已反向排序。
除了对于程序而言特殊的输入以外,我们也应该考虑使用该程序结构的特殊情况。例如,如果用一个 python 列表存储数据,我们应该确保诸如添加或删除列表的开头或末尾的边界情况都可以正确处理
手工测试是必不可少的,用大量随机生成的输入测试也是有优势的。python 中的随机模块为生成随机数或随机集合的顺序提供了几种方法。
程序类和函数之间的依赖关系形成层次结构。
- 在层次结构中,如果组件 A 依赖于组件 B , 比如函数 A 调用函数 B , 或者函数 A 依赖于一个参数,该参数是类 B 中的实例,就称组件 A 高于组件 B 。
这里有两种主要的测试策略,自顶向下( top-down ) 和自底向上( bottom-up ) ,它们的不同之处在于测试组件的顺序不同。
- 自上而下的测试从层次结构的顶部向底部进行。它通常用于连接存根(stubbing) , 一种用桩函数 ( stub ) 代替了底层组件的启动技术,桩函数是一种模拟原函数组件的替换技术。例如,如果函数 A 调用函数 B 获取文件的第一行,当测试 A 时,我们可以用返回固定字符串的桩函数代替 B 。
- 自下而上的测试从低级组件向更高级组件进行。例如,首先测试不调用其他函数的底层函数,其次测试只调用底层函数的函数,等等。相似的, 一个不依赖于其他类的类可以在依赖前者的其他类之前被测试。常将这种测试的形式称为单元测试( unit testing ) ,在大型软件项目的孤立状态下测试特定组件的功能。如果使用得当,这种策略能够更好地把错误的起因与被测试的组件隔离开来,因为该组件依赖的低级组件已经被充分测试过了。
python 为自动测试提供了几种支待形式。当函数或类定义在一个模块中时,该模块的测试可以被嵌入同一个文件中。1.11 节中描述了这样做的机制。当 python 直接调用该模块,而不是该模块用作大型软件项目的输入时, 在形式的条件结构中被屏蔽的代码
if __ name __ == '__ main __' :
# perform tests...
对于单元测试自动化, python 的 unittest 模块提供了更强大的支持。这个框架允许将单个测试用例分组到更大的测试套件中,并为执行这些套件提供支持,并报告或分析测试结果。为了维护软件,使用回归测试( regression testing) , 即通过对所有先前测试的重新执行来确保对软件的更改不会在先前测试的组件中引入新的错误
调试¶
最简单的调试技术包括使用打印语句( print statement ) 来跟踪程序执行过程中变址的值。这种方法的一个问题是, 最终需要删除或注释掉打印语句,因为最终发布软件时不能执行这些语句。
一种更好的方法是用调试器( debugger ) 运行程序。调试器是一个专门用于控制和监视程序执行的环境。调试器提供的基本功能是在代码中插入断点(breakpoint) 。当在调试器中执行时, 程序在每个断点处中止。当程序中止时,可以检查变量当前的值
标准的 python 程序包括一个 pdb 模块,该模块直接在解释器中提供调试支持。python 的大多数集成开发环境 IDE, 比如 IDLE, 用图形用户界面提供调试环境。
2.3 类定义¶
类是面向对象程序设计中抽象的主要方法。在 python 中, 类的实例代表了每个数据块。类以及实现它的所有实例给成员函数(也称方法( methods) )提供了一系列的行为
2.3.1 例子: CreditCard 类¶
作为第一个例子,我们提供了一个基于图 2-3 和 2.2.1 节中介绍的设计 CreditCard 类的实现方法。CreditCard 类定义的实例为传统的信用卡提供了一个简单的模型。实例已经确定了关于客户、银行、账户、信用额度和余额信息。该类会根据消费额度限制支付,但不收取利息或滞纳金(我们将在 2.4.1 节中再讨论这个主题) 。
我们的代码开始于代码段 2-1, 并在代码段 2-2 中继续。结构以关键词 class 开始,接着是类的名字和一个冒号,然后是一块作为类主体的缩进代码。主体包括所有类的方法的定义。用 1.5 节中介绍的技术把这些方法定义为函数,并用到一个名为 self 的特殊参数,该参数用来识别调用成员的特定实例。
在介绍 python 的 self 用法之前,先来介绍下 python 中的类和实例…… 我们知道,面向对象最重要的概念就是类(class)和实例(instance),类是抽象的模板,比如学生这个抽象的事物,可以用一个 Student 类来表示。而实例是根据类创建出来的一个个具体的“对象”,每一个对象都从类中继承有相同的方法,但各自的数据可能不同。 1、以 Student 类为例,在 python 中,定义类如下
class Student(object): pass(Object)表示该类从哪个类继承下来的,Object 类是所有类都会继承的类。
2、实例:定义好了类,就可以通过 Student 类创建出 Student 的实例,创建实例是通过类名+()实现:
student = Student()3、由于类起到模板的作用,因此,可以在创建实例的时候,把我们认为必须绑定的属性强制填写进去。这里就用到 python 当中的一个内置方法
__init__方法,例如在 Student 类时,把 name、score 等属性绑上去:class Student(object): def __init__(self, name, score): self.name = name self.score = score这里注意:(1)、
__init__方法的第一参数永远是 self,表示创建的类实例本身,因此,在__init__方法内部,就可以把各种属性绑定到 self,因为 self 就指向创建的实例本身。(2)、有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但 self 不需要传,python 解释器会自己把实例变量传进去>>>student = Student("Hugh", 99) >>>student.name "Hugh" >>>student.score 99另外,这里 self 就是指类本身,self.name 就是 Student 类的属性变量,是 Student 类所有。而 name 是外部传来的参数,不是 Student 类所自带的。故,self.name = name 的意思就是把外部传来的参数 name 的值赋值给 Student 类自己的属性变量 self.name。
4、和普通数相比,在类中定义函数只有一点不同,就是第一参数永远是类的本身实例变量 self,并且调用时,不用传递该参数。除此之外,类的方法(函数)和普通函数没啥区别,你既可以用默认参数、可变参数或者关键字参数(*args 是可变参数,args 接收的是一个 tuple,**kw 是关键字参数,kw 接收的是一个 dict)。
5、既然 Student 类实例本身就拥有这些数据,那么要访问这些数据,就没必要从外面的函数去访问,而可以直接在 Student 类的内部定义访问数据的函数(方法),这样,就可以把”数据”封装起来。这些封装数据的函数是和 Student 类本身是关联起来的,称之为类的方法:
class Student(obiect): def __init__(self, name, score): self.name = name self.score = score def print_score(self): print "%s: %s" % (self.name, self.score)>>>student = Student("Hugh", 99) >>>student.print_score Hugh: 99这样一来,我们从外部看 Student 类,就只需要知道,创建实例需要给出 name 和 score。而如何打印,都是在 Student 类的内部定义的,这些数据和逻辑被封装起来了,调用很容易,但却不知道内部实现的细节。
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线,在 python 中,实例的变量名如果以开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,所以,我们把 Student 类改一改:
class Student(object): def __init__(self, name, score): self.__name = name self.__score = score def print_score(self): print "%s: %s" %(self.__name,self.__score)改完后,对于外部代码来说,没什么变动,但是已经无法从外部访问实例变量
.__name和实例变量.__score了:>>> student = Student('Hugh', 99) >>> student.__name Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Student' object has no attribute '__name'这样就确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。
但是如果外部代码要获取 name 和 score 怎么办?可以给 Student 类增加 get_name 和 get_score 这样的方法:
class Student(object): ... def get_name(self): return self.__name def get_score(self): return self.__score如果又要允许外部代码修改 score 怎么办?可以给 Student 类增加 set_score 方法:
class Student(object): ... def set_score(self, score): self.__score = score需要注意的是,在 python 中,变量名类似
__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是 private 变量,所以,不能用__name__、__score__这样的变量名。有些时候,你会看到以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
封装的另一个好处是可以随时给 Student 类增加新的方法,比如:get_grade:
class Student(object): ... def get_grade(self): if self.score >= 90: return 'A' elif self.score >= 60: return 'B' else: return 'C'同样的,
get_grade方法可以直接在实例变量上调用,不需要知道内部实现细节>>> student.get_grade() 'A'6、
self的仔细用法 (1)、self 代表类的实例,而非类。class Test: def ppr(self): print(self) print(self.__class__) t = Test() t.ppr() 执行结果: <__main__.Test object at 0x000000000284E080> <class '__main__.Test'>从上面的例子中可以很明显的看出,self 代表的是类的实例。而 self.class则指向类。 注意:把 self 换成 this,结果也一样,但 python 中最好用约定俗成的 self。 (2)、self 可以不写吗? 在 python 解释器的内部,当我们调用 t.ppr()时,实际上 python 解释成 Test.ppr(t),也就是把 self 替换成了类的实例。
class Test: def ppr(): print(self) t = Test() t.ppr()运行结果如下
Traceback (most recent call last): File "cl.python", line 6, in <module> t.ppr() TypeError: ppr() takes 0 positional arguments but 1 was given运行时提醒错误如下:ppr 在定义时没有参数,但是我们运行时强行传了一个参数。
由于上面解释过了 t.ppr()等同于 Test.ppr(t),所以程序提醒我们多传了一个参数 t。
这里实际上已经部分说明了 self 在定义时不可以省略。
当然,如果我们的定义和调用时均不传类实例是可以的,这就是类方法
class Test: def ppr(): print(__class__) Test.ppr() 运行结果: <class '__main__.Test'>(3)、在继承时,传入的是哪个实例,就是那个传入的实例,而不是指定义了 self 的类的实例。
class Parent: def pprt(self): print(self) class Child(Parent): def cprt(self): print(self) c = Child() c.cprt() c.pprt() p = Parent() p.pprt()运行结果:
<__main__.Child object at 0x0000000002A47080> <__main__.Child object at 0x0000000002A47080> <__main__.Parent object at 0x0000000002A47240>解释: 运行 c.cprt()时应该没有理解问题,指的是 Child 类的实例。 但是在运行 c.pprt()时,等同于 Child.pprt(c),所以 self 指的依然是 Child 类的实例,由于 self 中没有定义 pprt()方法,所以沿着继承树往上找,发现在父类 Parent 中定义了 pprt()方法,所以就会成功调用
(4)、在描述符类中,self 指的是描述符类的实例
class Desc: def __get__(self, ins, cls): print('self in Desc: %s ' % self ) print(self, ins, cls) class Test: x = Desc() def prt(self): print('self in Test: %s' % self) t = Test() t.prt() t.x运行结果如下:
self in Test: <__main__.Test object at 0x0000000002A570B8> self in Desc: <__main__.Desc object at 0x000000000283E208> <__main__.Desc object at 0x000000000283E208> <__main__.Test object at 0x0000000002A570B8> <class '__main__.Test'>这里主要的疑问应该在:Desc 类中定义的 self 不是应该是调用它的实例 t 吗?怎么变成了 Desc 类的实例了呢? 因为这里调用的是 t.x,也就是说是 Test 类的实例 t 的属性 x,由于实例 t 中并没有定义属性 x,所以找到了类属性 x,而该属性是描述符属性,为 Desc 类的实例而已,所以此处并没有顶用 Test 的任何方法。
那么我们如果直接通过类来调用属性 x 也可以得到相同的结果。
下面是把 t.x 改为 Test.x 运行的结果。
self in Test: <__main__.Test object at 0x00000000022570B8> self in Desc: <__main__.Desc object at 0x000000000223E208> <__main__.Desc object at 0x000000000223E208> None <class '__main__.Test'>
self 标识符¶
在 python 中, self 标识符扮演了一个重要的角色。在 CreditCard 类的语境下,可以有很多不同的信用卡实例,而且每个都必须保持自己的余额、信用额度等。因此,每个实例都存储自己的实例变量,以反映其当前状态
在语句构成上, self 确定了调用方法的实例。例如,假设类的用户有一个变量 my_card, 它就确定了 CreditCard 类的一个实例。当用户调用 my_card.get_balance() 时, self 标识符用 get balance 方法引用被调用者名为 my_card 的卡。self._balance 表达式引用一个名为 _balance 的实例变量,存储为特定信用卡状态的一部分
class CreditCard·
""" A consumer credit card."""
def __init__(self, customer, bank, acnt, limit):
"""C reate a new credit card instance.
The initial balance is zero.
customer the name of the customer (e.g.,'John Bowman')
bank the name of the bank (e.g., 'California Savings')
acnt the acount identifier (e.g., 15391 0375 9387 53091)
limit credit limit (measured in dollars)
"""
self._customer = customer
self._bank = bank
self._account = acnt
self._limit = limit
self._balance = 0
def get_customer(self):
""" Return name of the customer."""
return self._customer
def get_bank(self)
""" Return the bank's name."""
return self._bank
def get_account(self).
""" Return the card identifying number (typically stored as a string) ."""
return self._account
def get_limit(self)
""" Return current credit limit """
return self._limit
def get_balance(self).
""" Return current balance."""
return self._balance
def charge(self, price):
"""Charge given price to the card, assuming sufficient credit limit
Return True if charge was processed; False if charge was denied .
"""
if price + self._balance > self._limit # if charge would exceed limit,
return False # cannot accept charge
else:
self._balance += price
return True
def make_payment(self, amount):
""" Process customer payment that reduces balance """
self._balance -= amount
我们可以看到调用者使用方法签名与类内部定义声明使用方法签名之间的差异。例如,从用户的角度来看,我们知道 get_balance 方法不带参数,但在类定义中, self 是一个明确的参数。同样,在类中声明 charge 方法有两个参数 (self 和 price),但是这个方法调用时只使用一个参数,例如 my_card.charge(200)。解释器在调用这些函数时自动将调用对应函数的实例绑定为 self 参数。
构造函数¶
用户可以用类似于下面的语法创建 CreditCard 类的实例
cc = CreditCard('John Doe','1st Bank','5391 0375 9387 5309', 1000)
其中,名为 _init_ 的方法是类的构造函数( constructor ) 。它最主要的责任是用适当的实例变量建立一个新创建的 CreditCard 类对象。就 CreditCard 类来说,每个对象保存 5 个实例变量,我们将其命名为_customer 、_bank 、_account 、_limit 和_balance
- 这 5 个变量中前 4 个的初始值是由明确的参数提供的,这些参数是在实例化信用卡时由用户发送的,并在构造函数的主体中给这些参数赋值。
- 比如, self._customer = customer, 把参数 customer 的值赋值给实例变量 self._customer 。注意:因为等号右侧的 customer 没有限定,所以它指的是本地命名空间中的参数
封装¶
2.2.3 节中所描述的惯例,在数据成员名称中的前加下划线,比如_balance, 表明它被设计为非公有的(nonpublic) 。类的用户不应该直接访问这样的成员。
通常,我们将所有数据成员视为非公有的。这使我们能够更好地对所有实例执行一致的状态。我们可以提供类似于 get_balance 的访问函数,以提供拥有只读访问特性的类的用户。如果希望允许用户改变状态,我们可以提供适当的更新方法。在数据结构中,封装内部表达的方式允许我们更加灵活地设计类的工作方式,这或许能提高数据结构的效率
附加方法¶
我们的类中最有趣的行为是收款和付款。收款功能通常会在信用卡余额中增加所收费用,以反映顾客提到的购买价格。然而,在收取费用前,我们的实现方法要验证新的消费不会导致余额超过信用额度。付款费用反映了客户给银行支付给定的款项,从而减少信用卡中的余额。
- 我们注意到,在 self._balance -= amount 命令中 self. _balance 的语句由 self 标识符做了限定,因为它代表了卡的实例变量, 而没有被限定的 amount 表示局部参数
错误检查¶
CreditCard 类的实现方法不是特别健壮。首先,我们注意到对于收款和付款,没有明确地检查参数的类型,也没有给构造函数任何参数
-
如果用户创建了一个类似于
visa.charge('candy')的调用, 当企图在余额中添加参数时,代码可能会崩溃 -
除了明显的类型错误,我们的实现方法可能会受到逻辑错误的影响。例如,如果允许用户收取一个类似于
visa. cbarge(-300)的负的价格,这将导致用户的余额变少。这是可以不通过支付来减少余额的一个漏洞。当然,如果模拟信用卡收到顾客给商家的退货时,这也会被视为合法的情况。我们将在本章末的练习中用 CreditCard 类讨论一些这样的问题
测试类¶
在代码段 2 -3 中,我们演示了 CreditCard 类的一些基本用法,在 wallet 列中插入 3 张卡。我们循环地进行收款和付款,并使用各种访问函数将结果打印到控制台。
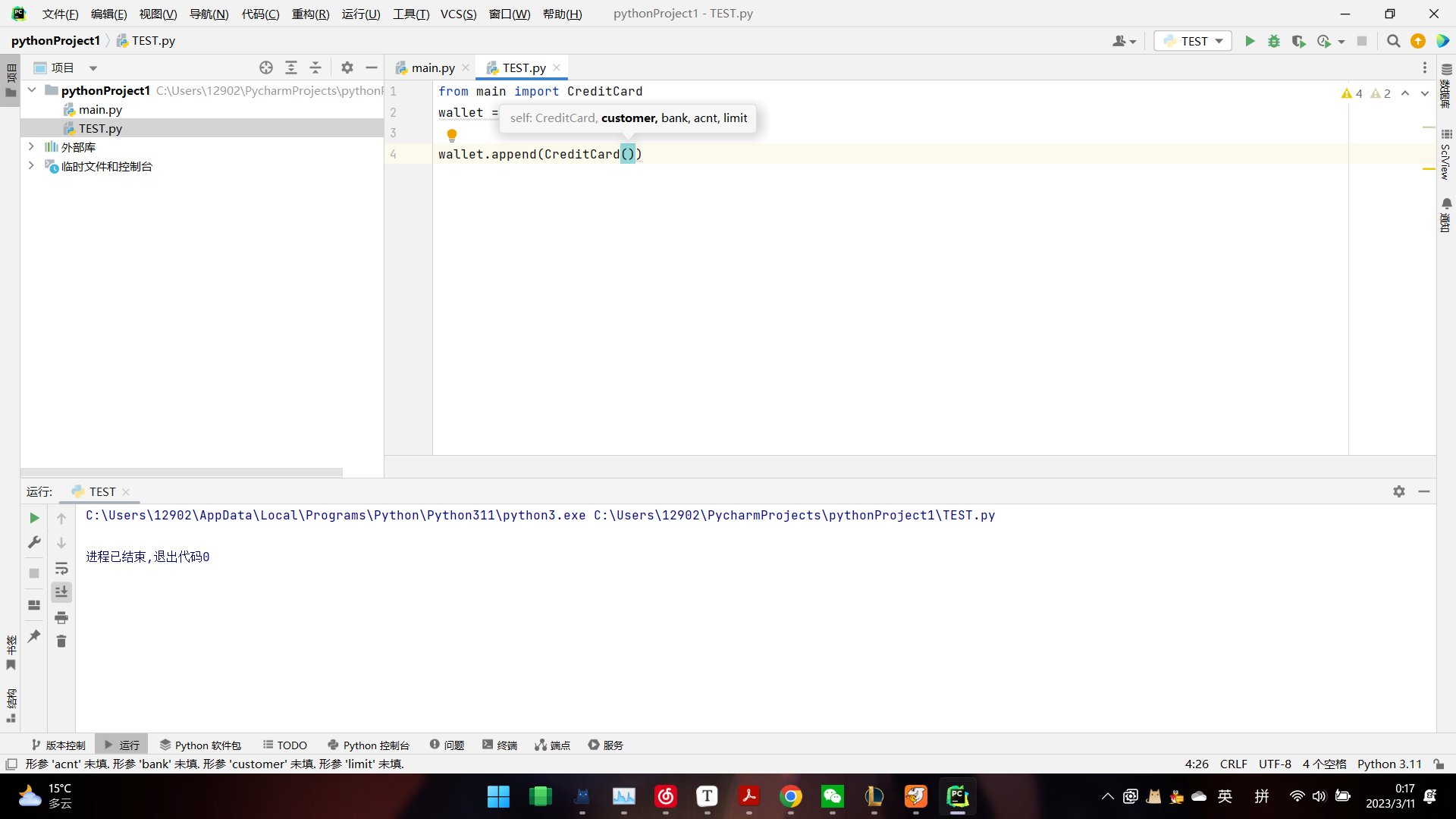
这些测试封闭在 if__ name __ =='__ main__': 条件中,这样它们可以通过类的定义嵌入源代码中。使用 2.2.4 节中的术语,这些测试提供方法覆盖, 每个方法至少被调用一次,但是这些测试不提供语句覆盖,因为有信用额度,所以这里不会有任何一种情况中的收款被拒绝。这种测试比较落后,必须手动地审核给定测试的输出结果,以确定是否该类表现得如我们所预期的一样。python 有更正式的测试工具( 见 2.2.4 节中讨论的 unittest 模块),这样得到的值可以与预测结果自动地比较, 只有当检测到错误时才产生输出。
if __ name __ == '__main__'
wallet = []
wallet.append(CreditCard('John Bowman' , 'California Savings',
'5391 0375 9387 5309', 2500))
wallet.append(CreditCard('John Bowman' , 'California Federal',
'3485 0399 3395 1954', 3500))
wallet.append(CreditCard('John Bowman','California Finance',
'5391 0375 9387 5309', 5000))
for val in range(1, 17)
wallet[O].charge(val)
wallet[1].charge(2*val)
wallet[2].charge(3*val)
for c in range(3)
print('Customer =' , wallet[c].get_customer())
print('Bank =', wallet[c] .get_bank())
print('Account =', wallet[c].get_account())
print('Limit =' , wallet[c].get_limit())
print('Balance =', wallet[c].get_balance())
while wallet[c].get_balance() > 100
wallet[c].make_payment(1OO)
print('New balance =', wallet[c] .get_balance())
print()
学过 Java、C、C++的程序员应该都知道,每次开启一个程序,都必须写一个主函数作为程序的入口,也就是我们常说的 main 函数。如下所示, main()就是 Java 中的一个 main 函数。
public class HelloWorld { public static void main(String[] args) { System.out.println("HelloWorld"); } }与 Java、C、C++等几种语言不同的是,python 是一种解释型脚本语言,在执行之前不同要将所有代码先编译成中间代码,python 程序运行时是从模块顶行开始,逐行进行翻译执行,所以,最顶层(没有被缩进)的代码都会被执行,所以 python 中并不需要一个统一的 main()作为程序的入口。在某种意义上讲,“
if __name__==’__main__:”也像是一个标志,象征着 Java 等语言中的程序主入口,告诉其他程序员,代码入口在此——这是“if __name__==’__main__:”这条代码的意义之一。1. name的理解¶
1.1 为什么使用name属性?
python 解释器在导入模块时,会将模块中没有缩进的代码全部执行一遍(模块就是一个独立的 python 文件)。开发人员通常会在模块下方增加一些测试代码,为了避免这些测试代码在模块被导入后执行,可以利用name属性。
1.2 name属性。
name属性是 python 的一个内置属性,记录了一个字符串。
若是在当前文件,name 是main。
- 在 hello 文件中打印本文件的name属性值,显示的是main
若是导入的文件,name是模块名。
- test 文件导入 hello 模块,在 test 文件中打印出 hello 模块的name属性值,显示的是 hello 模块的模块名。
因此name == 'main' 就表示在当前文件中,可以在 if name == 'main':条件下写入测试代码,如此可以避免测试代码在模块被导入后执行。
2. 模块导入¶
我们知道,当我们把模块 A 中的代码在模块 B 中进行 import A 时,只要 B 模块代码运行到该import 语句,模块 A 的代码会被执行。
模块 A:
# 模块A a = 100 print('你好,我是模块A……') print(a)模块 B:
# 模块B from package01 import A b = 200 print('你好,我是模块B……') print(b)运行模块 B 时,输出结果如下:
你好,我是模块A…… 100 你好,我是模块B…… 200如果在模块 A 中,我们有部分的代码不想在被导入到 B 时直接被运行,但在直接运行 A 时可直接运行,那该怎么做呢?那就可以用到“
if __name__==’__main__:”这行代码了,我们队上面用到的 A模块代码进行修改:A 模块代码修改为:
# 模块A a = 100 print('你好,我是模块A……') if __name__=='__main__': print(a)B 模块不做修改,直接执行 B 模块,输出结果如下:
你好,我是模块A…… 你好,我是模块B…… 200看到了吗,A 模块中的 a 的值就没有再被输出了。所以,当你要导入某个模块,但又不想改模块的部分代码被直接执行,那就可以这一部分代码放在“
if __name__=='__main__':”内部。3. “name”与“main”¶
看到现在也许心中还是疑惑,那么现在我们来说一说“
if__name__=='__main__':”的原理。“name”是 python 的内置变量,用于指代当前模块。我们修改上面用到的 A 模块和 B 模块,在模块中分别输出模块的名称:
模块 A:
# 模块A print('你好,我是模块A……') print('模块A中__name__的值:{}'.format(__name__)) print('-------------------------')模块 B:
# 模块B from package01 import A print('你好,我是模块B……') print('模块B中__name__的值:{}'.format(__name__))执行 A 模块时,输出结果:
你好,我是模块A…… 模块A中__name__的值:__main__ -------------------------执行 B 模块时,输出结果:
你好,我是模块A…… 模块A中__name__的值:package01.A ------------------------- 你好,我是模块B…… 模块B中__name__的值:__main__发现神奇之处了吗?当哪个模块被直接执行时,该模块“
__name__”的值就是“__main__”,当被导入另一模块时,“__name__”的值就是模块的真实名称。用一个类比来解释一下:记得小时候要轮流打算教室,轮到自己的时候(模块被直接执行的时候),我们会说今天是“我”(__main__)值日,称呼其他人时,我们就会直接喊他们的名字。所以,“__main__”就相当于当事人,或者说第一人称的“我”。所以,当运行“
if __name__=='__main__':”语句时,如果当前模块时被直接执行,__name__的值就是__main__,条件判断的结果为 True,“if __name__=='__main__':”下面的代码块就会被执行。无论是类属性还是类方法,都无法像普通变量或者函数那样,在类的外部直接使用它们。我们可以将类看做一个独立的空间,则类属性其实就是在类体中定义的变量,类方法是在类体中定义的函数。
前面章节提到过,在类体中,根据变量定义的位置不同,以及定义的方式不同,类属性又可细分为以下 3 种类型:
- 类体中、所有函数之外:此范围定义的变量,称为类属性或类变量;
- 类体中,所有函数内部:以“self.变量名”的方式定义的变量,称为实例属性或实例变量;
- 类体中,所有函数内部:以“变量名=变量值”的方式定义的变量,称为局部变量。
不仅如此,类方法也可细分为实例方法、静态方法和类方法,后续章节会做详细介绍。
那么,类变量、实例变量以及局部变量之间有哪些不同呢?接下来就围绕此问题做详细地讲解。
类变量(类属性)¶
类变量指的是在类中,但在各个类方法外定义的变量。举个例子:
class CLanguage : # 下面定义了2个类变量 name = "C语言中文网" add = "http://c.biancheng.net" # 下面定义了一个say实例方法 def say(self, content): print(content)上面程序中,name 和 add 就属于类变量。
类变量的特点是,所有类的实例化对象都同时共享类变量,也就是说,类变量在所有实例化对象中是作为公用资源存在的。类方法的调用方式有 2 种,既可以使用类名直接调用,也可以使用类的实例化对象调用。
比如,在 CLanguage 类的外部,添加如下代码:
#使用类名直接调用 print(CLanguage.name) print(CLanguage.add) #修改类变量的值 CLanguage.name = "python教程" CLanguage.add = "http://c.biancheng.net/python" print(CLanguage.name) print(CLanguage.add)程序运行结果为:
C 语言中文网 http://c.biancheng.net python 教程 http://c.biancheng.net/python
可以看到,通过类名不仅可以调用类变量,也可以修改它的值。
当然,也可以使用类对象来调用所属类中的类变量(此方式不推荐使用,原因后续会讲)。例如,在 CLanguage 类的外部,添加如下代码:
clang = CLanguage() print(clang.name) print(clang.add)运行程序,结果为:
C 语言中文网 http://c.biancheng.net
注意,因为类变量为所有实例化对象共有,通过类名修改类变量的值,会影响所有的实例化对象。例如,在 CLanguage 类体外部,添加如下代码:
print("修改前,各类对象中类变量的值:") clang1 = CLanguage() print(clang1.name) print(clang1.add) clang2 = CLanguage() print(clang2.name) print(clang2.add) print("修改后,各类对象中类变量的值:") CLanguage.name = "python教程" CLanguage.add = "http://c.biancheng.net/python" print(clang1.name) print(clang1.add) print(clang2.name) print(clang2.add)程序运行结果为:
修改前,各类对象中类变量的值: C 语言中文网 http://c.biancheng.net C 语言中文网 http://c.biancheng.net 修改后,各类对象中类变量的值: python 教程 http://c.biancheng.net/python python 教程 http://c.biancheng.net/python
显然,通过类名修改类变量,会作用到所有的实例化对象(例如这里的 clang1 和 clang2)。
注意,通过类对象是无法修改类变量的。通过类对象对类变量赋值,其本质将不再是修改类变量的值,而是在给该对象定义新的实例变量(在讲实例变量时会进行详细介绍)。
值得一提的是,除了可以通过类名访问类变量之外,还可以动态地为类和对象添加类变量。例如,在 CLanguage 类的基础上,添加以下代码:
clang = CLanguage() CLanguage.catalog = 13 print(clang.catalog)运行结果为:
13
实例变量(实例属性)¶
实例变量指的是在任意类方法内部,以“self.变量名”的方式定义的变量,其特点是只作用于调用方法的对象。另外,实例变量只能通过对象名访问,无法通过类名访问。
举个例子:
class CLanguage : def __init__(self): self.name = "C语言中文网" self.add = "http://c.biancheng.net" # 下面定义了一个say实例方法 def say(self): self.catalog = 13此 CLanguage 类中,name、add 以及 catalog 都是实例变量。其中,由于 init() 函数在创建类对象时会自动调用,而 say() 方法需要类对象手动调用。因此,CLanguage 类的类对象都会包含 name 和 add 实例变量,而==只有调用了 say() 方法的类对象,才包含 catalog 实例变量==。
例如,在上面代码的基础上,添加如下语句:
clang = CLanguage() print(clang.name) print(clang.add) #由于 clang 对象未调用 say() 方法,因此其没有 catalog 变量,下面这行代码会报错 #print(clang.catalog) clang2 = CLanguage() print(clang2.name) print(clang2.add) #只有调用 say(),才会拥有 catalog 实例变量 clang2.say() print(clang2.catalog)运行结果为:
C 语言中文网 http://c.biancheng.net C 语言中文网 http://c.biancheng.net 13
前面讲过,通过类对象可以访问类变量,但无法修改类变量的值。这是因为,通过类对象修改类变量的值,不是在给“类变量赋值”,而是定义新的实例变量。例如,在 CLanguage 类体外,添加如下程序:
clang = CLanguage() #clang访问类变量 print(clang.name) print(clang.add) clang.name = "python教程" clang.add = "http://c.biancheng.net/python" #clang实例变量的值 print(clang.name) print(clang.add) #类变量的值 print(CLanguage.name) print(CLanguage.add)程序运行结果为:
C 语言中文网 http://c.biancheng.net python 教程 http://c.biancheng.net/python C 语言中文网 http://c.biancheng.net
显然,通过类对象是无法修改类变量的值的,本质其实是给 clang 对象新添加 name 和 add 这 2 个实例变量。
类中,实例变量和类变量可以同名,但这种情况下使用类对象将无法调用类变量,它会首选实例变量,这也是不推荐“类变量使用对象名调用”的原因。
另外,和类变量不同,通过某个对象修改实例变量的值,不会影响类的其它实例化对象,更不会影响同名的类变量。例如:
class CLanguage : name = "xxx" #类变量 add = "http://" #类变量 def __init__(self): self.name = "C语言中文网" #实例变量 self.add = "http://c.biancheng.net" #实例变量 # 下面定义了一个say实例方法 def say(self): self.catalog = 13 #实例变量 clang = CLanguage() #修改 clang 对象的实例变量 clang.name = "python教程" clang.add = "http://c.biancheng.net/python" print(clang.name) print(clang.add) clang2 = CLanguage() print(clang2.name) print(clang2.add) #输出类变量的值 print(CLanguage.name) print(CLanguage.add)程序运行结果为:
python 教程 http://c.biancheng.net/python C 语言中文网 http://c.biancheng.net xxx http://
不仅如此,python 只支持为特定的对象添加实例变量。例如,在之前代码的基础上,为 clang 对象添加 money 实例变量,实现代码为:
clang.money = 30 print(clang.money)局部变量¶
除了实例变量,类方法中还可以定义局部变量。和前者不同,局部变量直接以“变量名=值”的方式进行定义,例如:
class CLanguage : # 下面定义了一个say实例方法 def count(self,money): sale = 0.8*money print("优惠后的价格为:",sale) clang = CLanguage() clang.count(100)通常情况下,定义局部变量是为了所在类方法功能的实现。需要注意的一点是,局部变量只能用于所在函数中,函数执行完成后,局部变量也会被销毁。
2.3.2 运算符重载和 python 的特殊方法¶
python 的内置类为许多操作提供了自然的语义。比如, a+b 语句可以询用数值类型语句,也可以连接序列类型。当定义一个新类时,我们必须考虑到当 a 或者 b 是类中的实例时是否应该定义类似于 a + b 的语句。
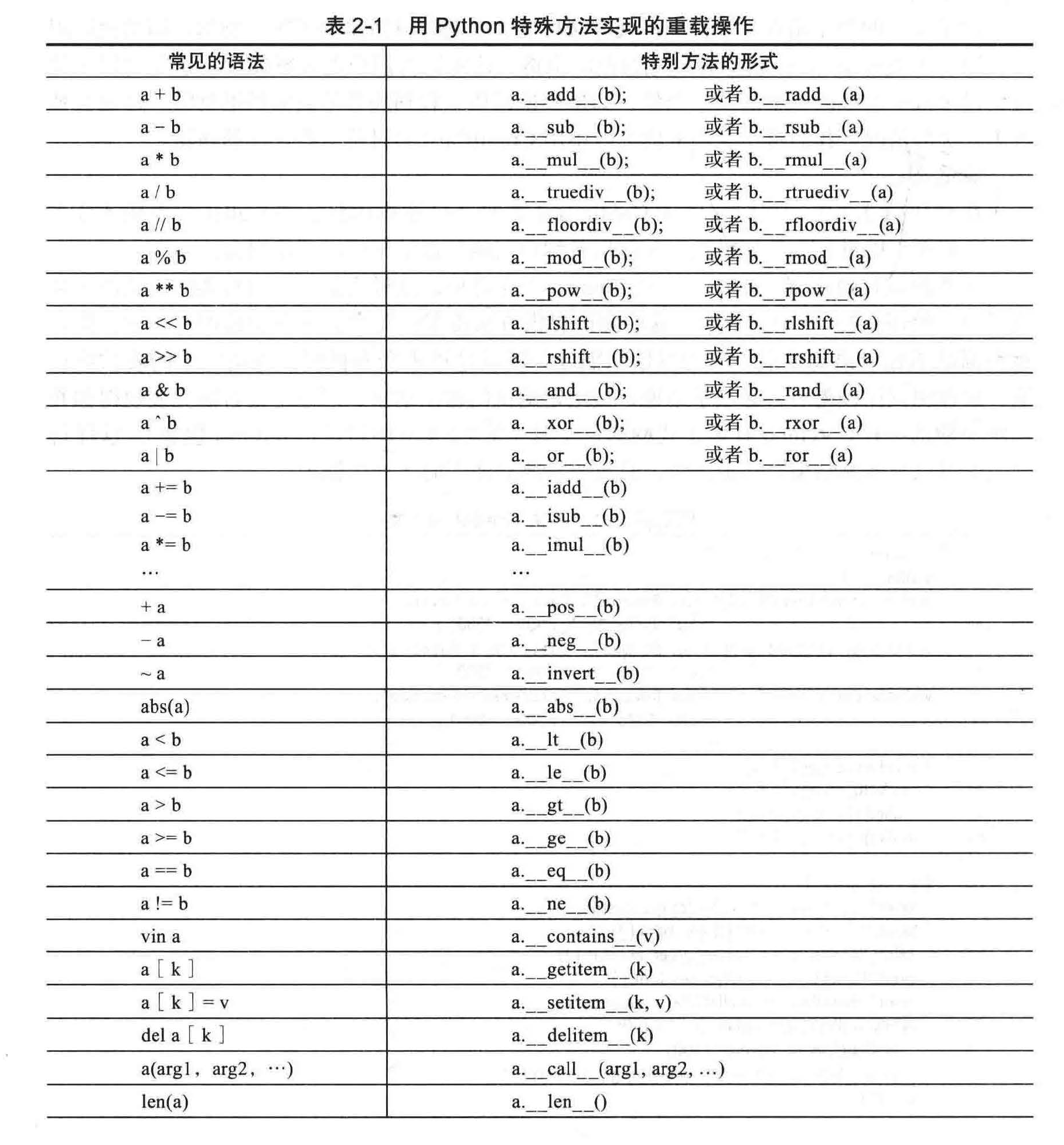
默认情况下,对于新的类来说,“+“操作符是未定义的。然而,类的作者可通过操作符重载(operator overloading) 技术来定义它。这个定义可通过一个特殊的命名方法来实现。特别的是,名为 __add__的方法重载+操作符,__add_用右边的操作作为参数并返回表达式的结果。也就是说, a+b 语旬,被转换为一个调用 a.__add__(b) 对象的方法。类似的特殊命名的方法存在其他操作符中。表 2-1 提供了与这一方法类似的完整列表
在这里,我们事先在 CreditCard 类中定义了类变量(并非实例变量)
a = 1
b = 2
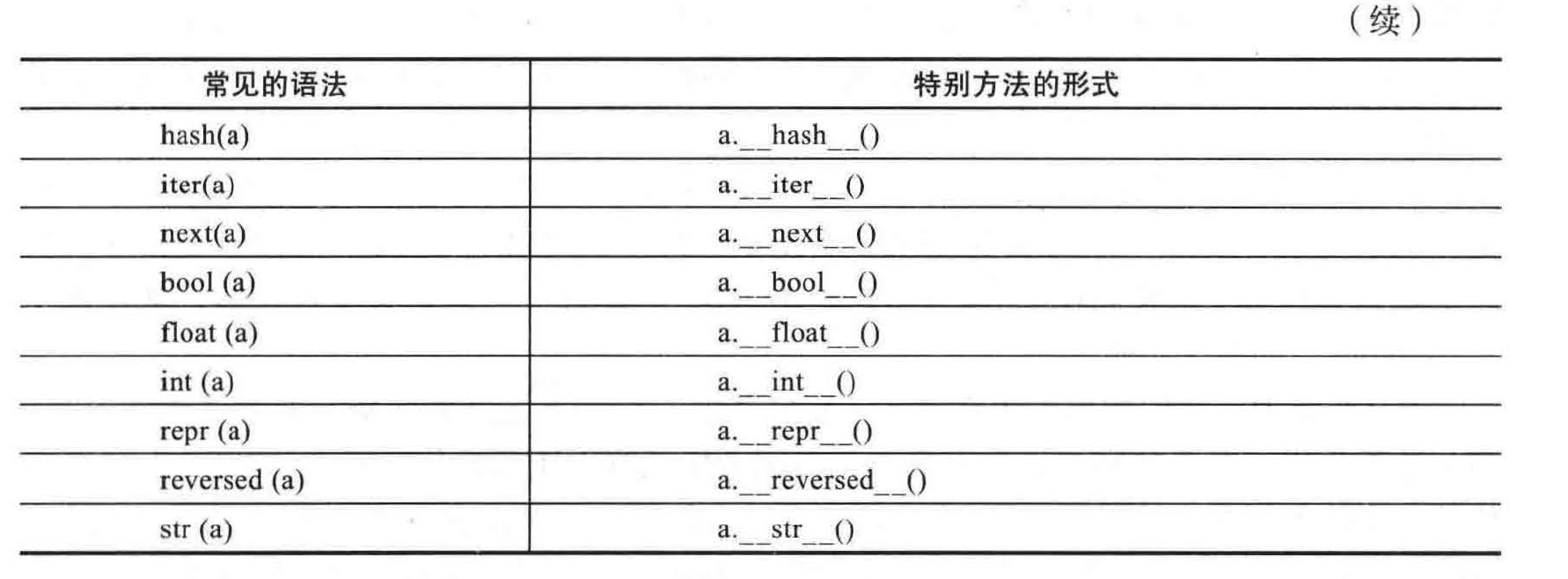
像 3 *'love me' 一样,当一个二元操作符应用于两个不同类型的实例中时, python 根据左操作数的类进行判断。在这个例子中,对于使用__mul__ 方法把字符串与实例相乘,可以通过检查 int 类是否提供了相应的定义。然而, 如果这个类没有实现这一行为, python
就会以一种名为__rmul__ ( 即“右乘")的特殊方法来检查右操作数的类的定义。该方法为新用户定义的类提供了一个支持包含已存在类(所给的已存在的类可能没有定义引用该新类的行为)的实例的混合操作的方法。___mul__和 __rmul__ 的区别也允许类根据情况定义不同的语义,如操作数在矩阵乘法中就是不可交换的( 即 A _ X 可能与 X _ A 不同) 。
非运算符重载¶
当使用用户自定义的类时,除了传统的操作符重载, python 依靠特殊的命名方法来控制各种功能的行为。例如, str(foo) 语句,是 string 类的构造函数的一个调用。
- 如果参数是用户定义的类的实例, string 类的原作者当然不知道应该如何根据这个实例构造字符串。所以字符串构造函数调用一个专门的命名方法,
foo.__ str__(),它必须返回一个恰当的字符串表示形式。
类似的方法也被用于通过一个用户自定义类来构造 int 、float 或 bool 类型。将一个用户自定义类转换为一个 Boolean 值尤为重要,因为即使当 foo 不是一个 Boolean 值(见 1.4.1 节)时也可以使用 if foo : 语句。对于用户自定义的类,用专门的方法 foo.__ bool__() 返回对应的真值。
隐式的方法¶
作为一般规则,如果在用户已定义的类中没有实现特定的特殊方法, 则依赖于该方法的标准语法将引发异常。例如,用户自定义类未定义 __add__或者__radd__方法,则计算自定义==类的实例相加==的语句 a + b 将会引发异常
然而,当缺乏特殊方法时,有一些操作符已经由 python 提供了默认定义,也有一些操作符的定义来源于其他定义。例如, 支持 If foo: 语句的__bool__ 方法有默认语义,以至于除了 None 以外的每个对象的值都为 True 。然而,对于容器类型,通常定义__len__方法返回容器的大小。如果这种方式存在,对于长度不为 0 的实例, bool(foo) 的值默认情况下为 True, 对于长度为 0 的实例,值默认情况下为 False, 允许用类似于 if waitlist: 的语句测试是否在等待队列中有一个或多个条目。
在 2.3.4 节中,我们将讨论 python 通过特殊方法__iter__为集合提供迭代器的机制。也就是说,如果一个容器类实现了__len__和__getitem__方法,则它可以自动提供一个默认迭代器(用我们在 2.3.4 节中讨论的方法) 。此外, 一旦定义了迭代器,就提供了
__ contains__的默认功能
在 1.3 节中,我们指出了表达式 a is b 和表达式 a == b 之间的区别,前者评估标识符 a 和 b 是否为同一对象的别名,后者测试两个标识符是否引用等价值的概念。”等价"的概念依赖于类的上下文,并用__eq__方法定义语义。然而,如果没有实现__eq__方法,语句 a == b 和 a is b 语义是等价的,即一个实例只和其自身是等价的,和其他实例都不相等。
我们也应该注意到, python 并没有自动提供一些我们认为自然而然的表达式。例如,__ eq__方法支持 a == b 语旬,但该方法不影响 a!= b 语句的值(该值通过__ne__ 方法计算,通常返回 not (a == b) 作为结果) 。同样,提供__lt__方法支持 a < b 语句,并且间接支
持 b >a 语句,但是提供的__lt__和__eq__都没有 a < = b 的语义
2.3.3 例子:多维向量类¶
为了演示通过特殊方法使用运算符重载,我们给出一个 Vector 类的实现方法,代表了一个多维空间中向量的坐标。例如,在三维空间中,也许我们希望用坐标 ( 5, - 2, 3 )代表一个向量。虽然直接使用 python 列表代表那些坐标可能更有吸引力,但是列表不能为几何 向量提供适当的抽象。特殊的是,如果使用列表,表达式 [5, - 2, 3] + [1 , 4, 2] 的结果是 [5, 2, 3, 1, 4, 2] 。当用向量工作时,如果 u = (5, - 2, 3 ) 并且 v = ( 1,4, 2 ),我们希望用表达式 u + v 来返回一个坐标为 (6, 2, 5 ) 三维向量。
因此,我们在代码段 2-4 中定义一个 Vector 类,它为几何向量的概念提供了一个更好的抽象。在内部,我们的向量依赖列表名为_coords 的实例,作为它的存储机制。通过保持内部列表的封装,我们可以为类中的实例执行所请求的公共接口。示例如下:
代码段 2-4 一个简单 Vector 类的定义
import collections
class Vector:
"""Represent a vector in a multidimensional space."""
def __init__(self, d):
if isinstance(d, int):
self._coords = [0] * d
else:
try: # we test if param is iterable
self._coords = [val for val in d]
except TypeError:
raise TypeError('invalid parameter type')
def __len__(self):
"""Return the dimension of the vector."""
return len(self._coords)
def __getitem__(self, j):
"""Return jth coordinate of vector."""
return self._coords[j]
def __setitem__(self, j, val):
"""Set jth coordinate of vector to given value."""
self._coords[j] = val
def __add__(self, other):
"""Return sum of two vectors."""
if len(self) != len(other): # relies on __len__ method
raise ValueError('dimensions must agree')
result = Vector(len(self)) # start with vector of zeros
for j in range(len(self)):
result[j] = self[j] + other[j]
return result
def __eq__(self, other):
"""Return True if vector has same coordinates as other."""
return self._coords == other._coords
def __ne__(self, other):
"""Return True if vector differs from other."""
return not self == other # rely on existing __eq__ definition
def __str__(self):
"""Produce string representation of vector."""
return '<' + str(self._coords)[1:-1] + '>' # adapt list representation
def __neg__(self):
"""Return copython of vector with all coordinates negated."""
result = Vector(len(self)) # start with vector of zeros
for j in range(len(self)):
result[j] = -self[j]
return result
def __lt__(self, other):
"""Compare vectors based on lexicographical order."""
if len(self) != len(other):
raise ValueError('dimensions must agree')
return self._coords < other._coords
def __le__(self, other):
"""Compare vectors based on lexicographical order."""
if len(self) != len(other):
raise ValueError('dimensions must agree')
return self._coords <= other._coords
if __name__ == '__main__':
# the following demonstrates usage of a few methods
v = Vector(5) # construct five-dimensional <0, 0, 0, 0, 0>
v[1] = 23 # <0, 23, 0, 0, 0> (based on use of __setitem__)
v[-1] = 45 # <0, 23, 0, 0, 45> (also via __setitem__)
print(v[4]) # print 45 (via __getitem__)
u = v + v # <0, 46, 0, 0, 90> (via __add__)
print(u) # print <0, 46, 0, 0, 90>
total = 0
for entry in v: # implicit iteration via __len__ and __getitem__
total += entry
很多接口可以通过调用和内部坐标列表类似的方法实现。然而,__add__的实现方法却不同。假设两个操作数是长度相同的向量,该方法创建了一个新的向量,并将新向量的坐标置为各自操作数对应分量元素的和。
请注意代码段 2-4 中该方法的定义很有趣,该定义自动支持 u = v + [5, 3, 10, - 2, 1] 语法,并产生一个新的向量,该向量的各个元素是第一个向量和列表实例对应位置元素之和。这是 python 多态性(polymorphism) 的结果。从字面上看,“多态” 的意思是"许多形式” 。虽然它容易使我们想到 __add__方法中的 other 参数是一个 Vector 的实例,但我们并没这样声明它。在内部,我们依赖于参数 other 的唯一行为是它支持 len(other) 并且可以访问 other[j] 。因此,当右边的操作数是一个数字(匹配的长度)列表时,代码依然可以执行(而并非一定要求是该类(Vector)的一个实例)。
2.3.4 迭代器¶
在数据结构的设计中,迭代器是一个重要的概念。在 1.8 节中,我们介绍了 python 迭代器的机制。简而言之,集合的迭代器(iterator) 提供了一个关键行为:它支持一个名为 _next_ 的特殊方法,如果集合有下一个元素,该方法返回该元素,否则产生一个 Stopfteration 异常来表明没有下一个元素。
我们的首选方法是使用生成器(generator) 语法(巳在 1.8 节中描述了),它自动地产生一个已生成值的迭代器
python 也为实现_len__ 和__getitem__的类提供了一个自动的迭代器。为了提供一个低级迭代器的例子,代码段 2-5 演示了这种迭代器类可用于任何支持__len__和__getitem__的集合的处理。该类可被实例化为 Sequencelterator(data)。它通过保存在内部的数据序列引用来操作该序列以及当前的索引。每次调用*\_next*时,索引递增,直到序列结束。

2.3.5 例子: Range 类¶
作为本节中的最后一个例子,我们实现一个类来模拟 python 的内置 range 类。在介绍这个类之前,我们先讨论内置版本的历史。在发布 python 3 之前, range 作为一个函数来实现,并且用特定范围内的元素返回一个列表实例。例如, range(2, 10 , 2) 返回列表[2, 4 , 6 , 8 ] 。然而,该函数的典型用法是支持类似于 for k in range(10000000) 的循环语法。不幸的是,这会引起一个数字范围列表的实例化和初始化,在时间和内存的使用上都造成了不必要的浪费。
在 python 3 中, range 的机制是完全不同的( 公平地说,这种“新”方法在 python 2 中也存在,但是名为 xrange) 。它使用了一种被称为惰性求值(lazy evaluation) 的策略。与其创建一个新的列表实例,不如使用 range, 它是一个类,可以有效地表示所需的元素范围,
而不必在内存中明确地存储它们。为了更好地探讨内置 range 类,我们建议你创建一个类似于 r = range(8, 140, 5) 的实例。其结果是一个相对轻量级的对象, 一个只有几个行为的 range 类的实例。len(r) 语法将报告给定范围中元素的数量(在我们的例子中是 27) 。range 也支持 __ getitem__方法, r[15] 表达式返回了 range 中的第 16 个元素( r[0] 是第一个元素) 。因为这个类支持__len__ 和__getitem__ ,所以它自动支持迭代( 见 2.3.4 节) ,这就是为什么可以通过 range 执行一个 for 循环。
上面的代码展示了一个长度为 10 的 1
对此,我们准备展示一个自定义的类的版本。代码段 2-6 提供了一个类,我们将其命名为 Range (以明确区分它与内置的 range) 。这一实现的最大挑战是当构建 range 时通过调用者发送给定的参数时正确地计算属于 range 的元素个数。通过计算构造函数中的值, 并存储为 self._length, 把该值从_len_ 方法中返回就很容易了。为了正确地实现对__getitem__(k)的调用,我们只需把 range 的初始值加上 k 乘以步长(即,当 k = 0, 我们返回初始值) 。这有几个值得在代码段中检查的细节:
- 当讨论一个可工作的 range 函数版本时,为了正确地支持可选参数,我们使用了 1.5.1 节中描述的技术
- 我们通过
max(0, (stop - start + step - 1)//step)计算元素的个数,对于正数和负数的步长该公式都需要测试。 - 在计算结果之前,
__getitem__方法可通过将-k 转换为len(self) - k以正确地支持负数下标。
class Range:
"""A class that mimic's the built-in range class."""
def __init__(self, start, stop=None, step=1):
"""Initialize a Range instance.
Semantics is similar to built-in range class.
"""
if step == 0:
raise ValueError('step cannot be 0')
if stop is None: # special case of range(n)
start, stop = 0, start # should be treated as if range(0,n)
# calculate the effective length once
self._length = max(0, (stop - start + step - 1) // step)
# need knowledge of start and step (but not stop) to support __getitem__
self._start = start
self._step = step
def __len__(self):
"""Return number of entries in the range."""
return self._length
def __getitem__(self, k):
"""Return entry at index k (using standard interpretation if negative)."""
if k < 0:
k += len(self) # attempt to convert negative index
if not 0 <= k < self._length:
raise IndexError('index out of range')
return self._start + k * self._step
可以看到,上面的类 Range 并没有完整的生成一个实例,而是当用户要调用某一元素(例如 Range(a))时生成一个相应的元素
2.4 继承¶
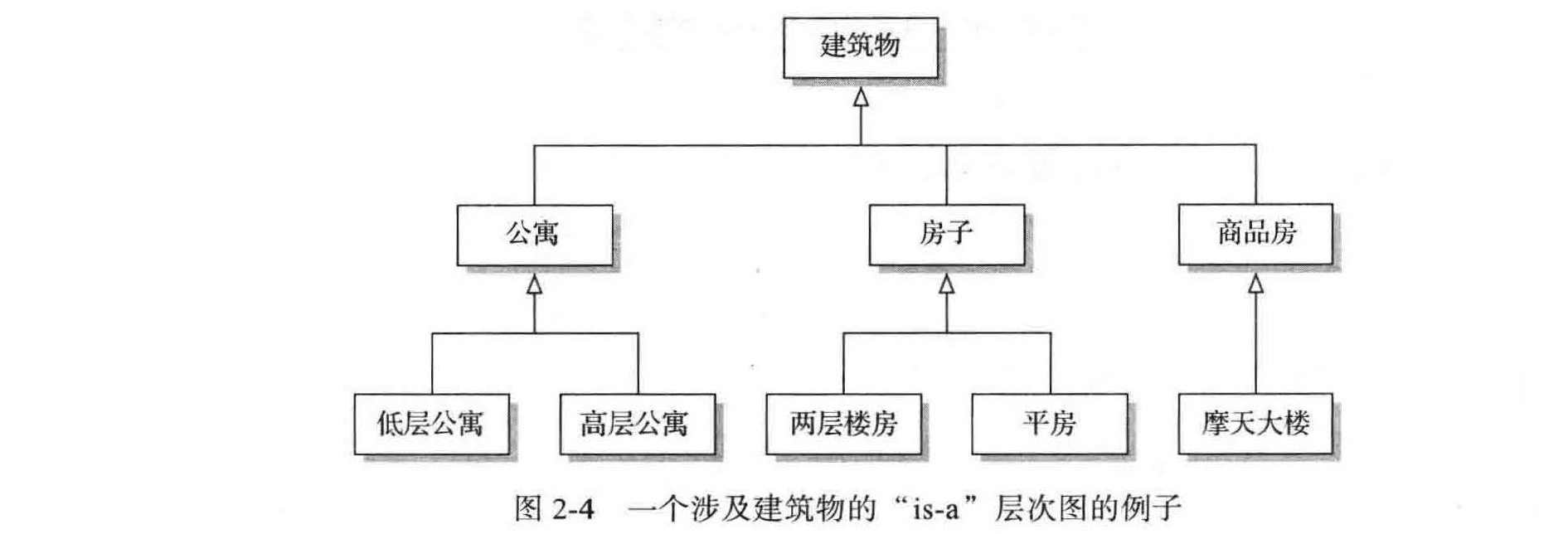
组织各种软件包的结构组件的自然方法是,在一个分层( hierarchical ) 的方式中,在水平层次上把类似的抽象定义组合在一起,下层的组件更加具体,上层的组件更加通用。图 2-4 展示了这样一个层次的例子。用数学符号表示, 一套房子是一个建筑物的子集 (subset),但它是一个牧场的超集(superset ) 。层次之间的对应关系通常被称为" is-a" 的关系,就像房子是建筑,平房是房子。
在软件开发中,层次设计是非常有用的,在最通用的层次上可以把共同的功能分组,从而促进代码的重用,进而将行为间的差别视为通用情况的扩展。在面向对象的编程中,模块化和层次化组织的机制是一种称为继承( inheritance ) 的技术。这个技术允许基于一个现有的类作为起点定义新的类。在面向对象的术语中,通常描述现有的类为基类( base class ) 、父类( parent class ) 或者超类(superclass ) ,而称新定义的类为子类(subclass 或者 child class) 。
有两种方式可以让子类有别于父类。子类可以通过提供一个新的覆盖(override) 现有方法的实现方法特化(specialize) 一个现有的行为。子类也可以通过提供一些全新的方法扩展(extend) 其父类。
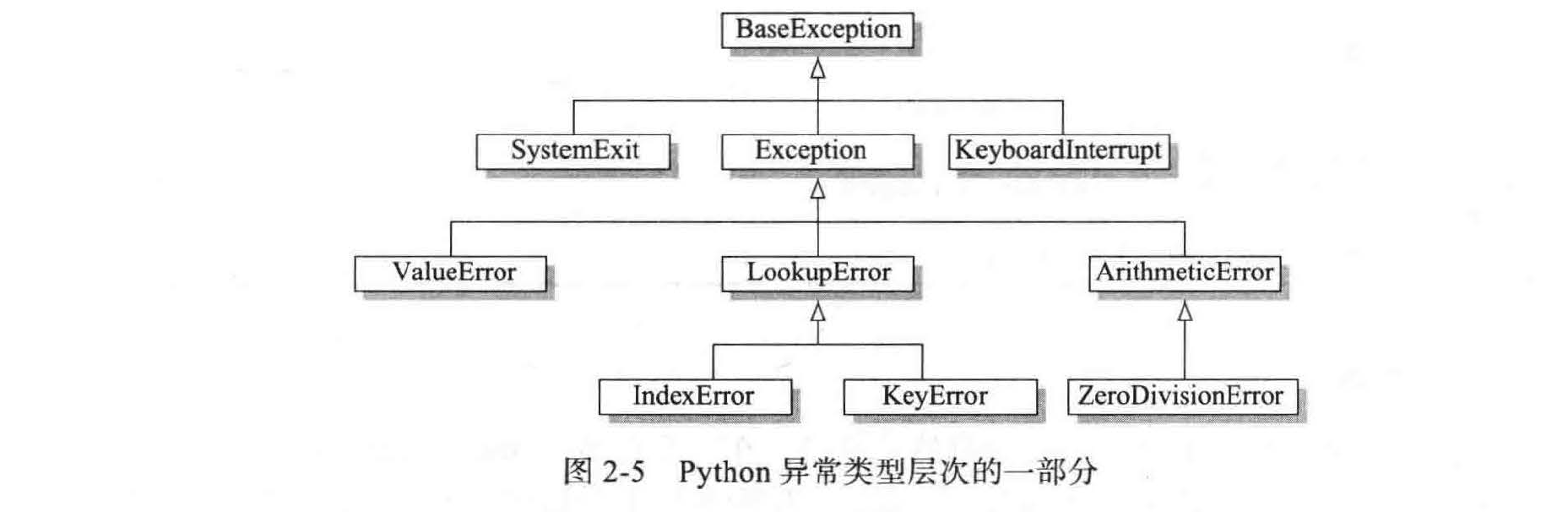
python 的异常层次结构¶
富有继承层次的另一个例子是在 python 中组织各种异常类型。我们在 1.7 节中介绍了许多类,但没有讨论它们之间的相互关系。图 2-5 说明了该层次结构中的一小部分。BaseException 类是整个层次结构的根,而更具体的 Exception 类包括了大部分我们已经讨论过的错误类型。程序设计者可以自由定义特殊的异常类,以表示在应用程序的上下文中可能出现的错误。应该声明这些用户自定义的异常类型为 Exception 的子类。
2.4.1 扩展 CreditCard 类¶
为了表示 python 中的层次机制,我们再来看 2.3 节中的信用卡类,实现子集 PredatoryCreditCard 。因为没有更好的名字,所以我们将其命名为 PredatoryCreditCard 。新类和原始的类将有两方面的不同:
- 当尝试收费由于超过信用卡额度被拒绝时,将会收取 5 美元的费用;
- 将有一个对未清余额按月收取利息的机制,即基于构造函数的一个参数年利率 (Annual Percentage Rate, APR) 。
在实现这一目标时,我们展示了特化和扩展技术。在进行无效的收费时,我们覆盖了现有的收费方法,并由此特化它以提供新的功能(虽然新的版本利用了被覆盖版本的调用) 。为了给收取利息提供支持,我们用名为 process_month 的新方法扩展
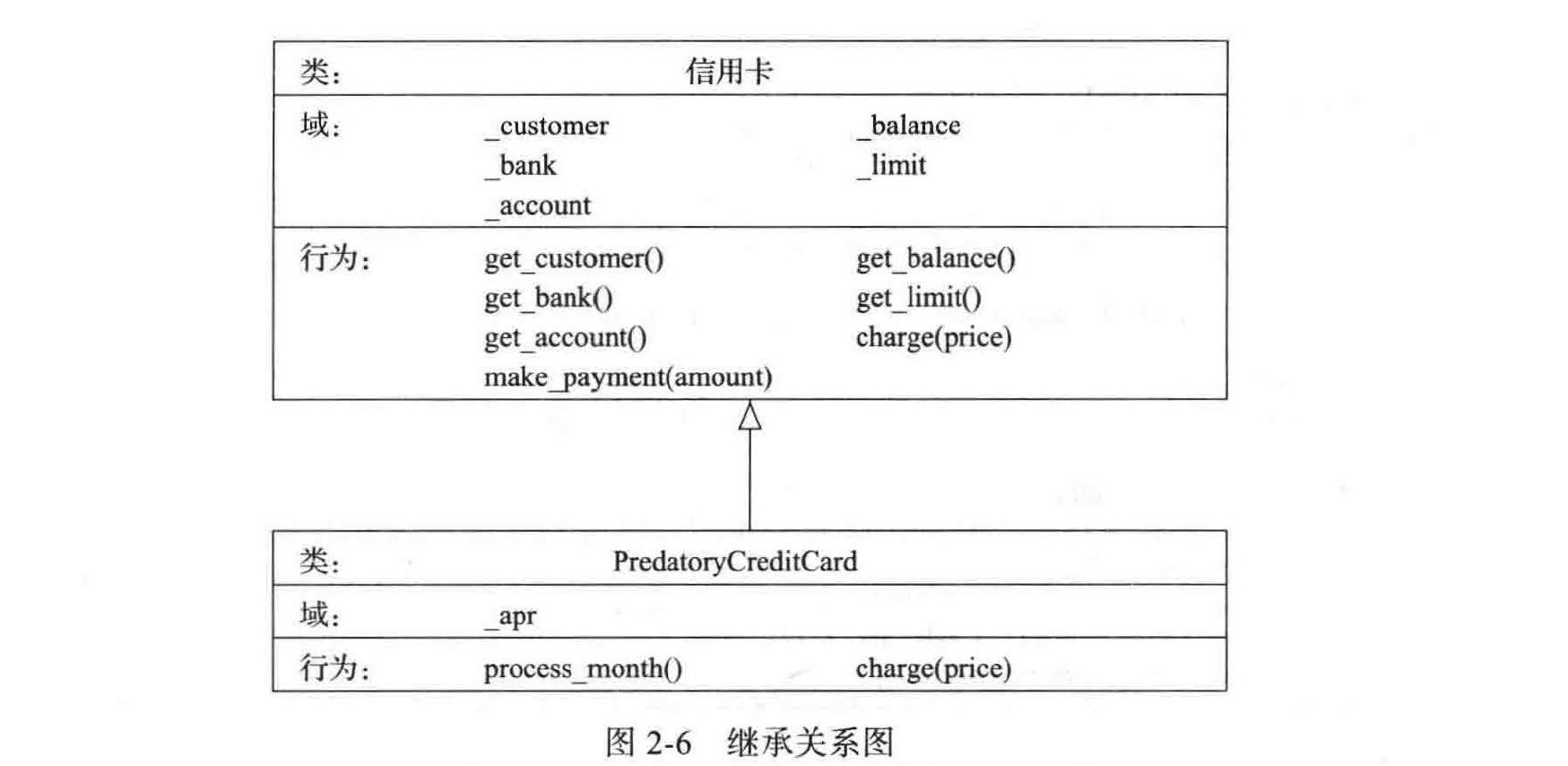
图 2-6 描述了我们在设计新 PredatoryCreditCard 类中使用的继承关系,代码段 2-7 给出了一个完整的 python 类的实现。
为了表明新类从现有的 CreditCard 类中继承,我们的定义从class PredatoryCreditCard (CreditCard) 语法开始。新类的主体提供了三个成员函数: _init_、charge 和 processmonth 。\_\_ init*_ 构造函数的作用和 CreditCard 构造函数非常类似,除新的类之外,还有一个额外的参数来指定年利率。新构造函数的主体依赖调用继承的构造函数来执行大部分的初始化处理(事实上, 除了记录百分比之外的一切) 。调用继承构造函数的机制依赖于 super()语法*。具体来讲, 即第 15 行命令
super().__init__(customer, bank, acnt, limit)
调用从 CreditCard 父类继承的__init__方法。值得注意的是,我们在名为_apr 的新域中记录 APR 的值。
同样, PredatoryCreditCard 类提供了一个新收费策略的实现方法,该方法重写了继承的方法。然而,新方法的实现取决于对继承方法的调用,用第 24 行中的语句 super().charge(price) 。调用函数的返回值表明是否收费成功
from .credit_card import CreditCard
class PredatoryCreditCard(CreditCard):
"""An extension to CreditCard that compounds interest and fees."""
def __init__(self, customer, bank, acnt, limit, apr):
"""Create a new predatory credit card instance.
The initial balance is zero.
customer the name of the customer (e.g., 'John Bowman')
bank the name of the bank (e.g., 'California Savings')
acnt the acount identifier (e.g., '5391 0375 9387 5309')
limit credit limit (measured in dollars)
apr annual percentage rate (e.g., 0.0825 for 8.25% APR)
"""
super().__init__(customer, bank, acnt, limit) # call super constructor
self._apr = apr
def charge(self, price):
"""Charge given price to the card, assuming sufficient credit limit.
Return True if charge was processed.
Return False and assess $5 fee if charge is denied.
"""
success = super().charge(price) # call inherited method
if not success:
self._balance += 5 # assess penalty
return success # caller expects return value
def process_month(self):
"""Assess monthly interest on outstanding balance."""
if self._balance > 0:
# if positive balance, convert APR to monthly multiplicative factor
monthly_factor = pow(1 + self._apr, 1/12)
self._balance *= monthly_factor
我们检查返回值,以决定是否评估费用。相应的,我们返回该值给方法的调用者,这样可以 使得新的收费方法与原来的方法有一个类似的外部接口。
process_montb 方法是一种新行为,所以没有依赖继承的版本。在我们的模型中, 这种方法应该每月由银行调用一次,来收取新的利息费用。实施这种方法最具挑战性的是确保我们已经有将年利率转换为月利率的知识。我们不能简单地将年利率除以 12 来得到月利率(这样太没道理,因为这将导致 APR 比实际的更高)
保护成员¶
PredatoryCreditCard 子类直接访问数据成员 self._balance, 这个数据成员是由 CreditCard 父类建立的。按照约定,名字带下划线表示它是一个非公有成员,所以我们可能会问是否可以照这种方式访问它。虽然一般类的用户不会这样做,但是我们这里的子类与父类有些特权关系。一些面向对象的语言(如 Java, C++)指出了非公有成员的区别,即允许声明的受保护(protected) 或私有( private) 的访问模式。被声明为受保护的成员可以访问子类,但是不能访问一般的公有类;被声明为私有的成员既不能访问子类,也不能访问公有类。在这方面,如果它是受保护的(但不是私有的),我们就用_balance 。
python 不支持正式的访问控制,但以一个下划线开头的名字都被看作受保护的,而以双下划线开头的名字(除了特殊的方法)是被看作私有的。在选择使用受保护的数据时,我们已经创建了一个依赖,在该依赖中,如果 CreditCard 类的作者改变了内部设计,PredatoryCreditCard 可能也会改变。要注意的是,我们可能在 process_month 方法中依赖公有的 get_balance()方法来检索当前的余额。但是 CreditCard 类的设计不能为子类提供一个有效的方式来改变余额,除了直接操作数据成员。用 charge 方法来为余额增加费用和利息可能是很有吸引力的。然而,这种方法不允许余额超过客户的信用额度,但是如果有担保的话,银行可能会让利率超出信贷限额。如果重新设计原始的 CreditCard 类,我们可以添加一个非公有的方法_set_balance, 子类可以用该方法来改变余额而不直接访问数据成员 _balance 。
2.4.2 数列的层次图¶
作为使用继承的第二个例子,我们将介绍迭代数列的类的层次。数列是指数字的序列,其中每个数字都依赖于一个或更多的前面的数字。例如, 一个等差数列(arithmetic progression)通过给前一个数值增加一个固定常量来确定下一个数字,一个等比数列(geometric progression) 通过前一个值乘以固定常量来确定下一个数字。在一般情况下,数列需要一个初始值,以及在一个或多个先前值的基础上确定新值的方法。
为了最大限度地提高代码的可重用性,我们给出了一个由通用基类产生的名为 Progression 类(见图 2-7 ) 的分层。从技术上讲, Progression 类产生全为数字的数列: 0, 1, 2, … 然而,该类被设计为其他数列类型的基类,提供尽可能多的公共函数,并由此把子类的 负担减至最小。
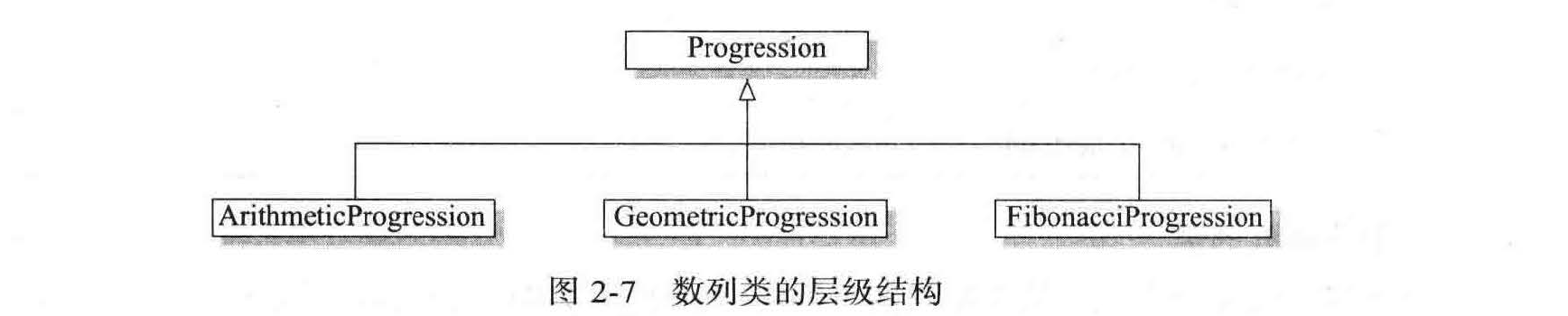
代码段 2-8 提供了基本 Progression 类的实现方法。这个类的构造函数接受数列的起始值(默认为 0),并用该值初始化self._current 数据成员。
Progression 类实现 python 迭代器(见 2.3.4 节)的公约,即特殊的_next_和__iter__ 方法。如果类的用户创建了一个 seq = Progression() 的数列序列, next(seq) 的每次调用会返回数列中的下一个值。也可以使用 for-loop 的语法 for value in seq. ,但是我们注意到,默认的数列被定义为无穷序列。
为了更好地从数列的核心逻辑中将迭代器公约的技术分离出来,我们的框架依靠一个名为 _advance 的非公有方法来更新 self._current 域的值。在默认的实现方法中,_advance 添加了一个当前值,但我们的目的是子类重写_advance 方法,以提供不同的方法来计算下一个值。
为方便起见, Progression 类还提供了一个名为 print_progression 的实体方法,该方法显示了数列接下来的 n 个值。
class Progression:
"""Iterator producing a generic progression.
Default iterator produces the whole numbers 0, 1, 2, ...
"""
def __init__(self, start=0):
"""Initialize current to the first value of the progression."""
self._current = start
def _advance(self):
"""Update self._current to a new value.
This should be overridden by a subclass to customize progression.
By convention, if current is set to None, this designates the
end of a finite progression.
"""
self._current += 1
一个等差数列类¶
特殊数列的第一个例子是等差数列。数列默认逐步增加自身的值, 等差数列通过给数列的每一项增加一个固定的常量来产生下一个值。例如,用一个初值为 0 、增量为 4 的等差数列将产生序列 0, 4, 8, 12, …
代码段 2-9 介绍了 ArithmeticProgression 类的实现方法,该类以 Progression 类作为它的基类。新类的构造函数接受增址和初值两个参数,每个参数都有默认值。我们约定, Arithmetic Progression(4) 产生序列 0, 4, 8, 12, …,ArithmeticProgression(4, 1) 产生序列 1, 5, 9, 13, …
class ArithmeticProgression(Progression): # inherit from Progression
"""Iterator producing an arithmetic progression."""
def __init__(self, increment=1, start=0):
"""Create a new arithmetic progression.
increment the fixed constant to add to each term (default 1)
start the first term of the progression (default 0)
"""
super().__init__(start) # initialize base class
self._increment = increment
def _advance(self): # override inherited version
"""Update current value by adding the fixed increment."""
self._current += self._increment
ArithmeticProgression 构造函数的主体调用超类的构造函数来初始化_current 数据成员作为所需的初值, 然后直接为等差数列建立新的_increment 数据成员。实现中唯一遗留的细节是重写_advance 方法以便给当前的值加上增量。
一个等比数列类¶
第二个特殊数列的例子是一个等比数列, 其中每个值由固定常量乘以先前的值而产生,该固定常量被称为等比数列的基数。等比数列的初值通常为 1 , 而不是 0, 因为任何因子乘以 0 其结果都是 0 。举一个例子, 一个以 2 为基数的等比数列为 1 ,2, 4, 8, 16, ···
代码段 2 - 10 介绍了 GeometricProgression 类的实现方法。构造函数以 2 作为默认基数,并用 1 作为默认的初值,但其中任意一个都可以使用可选参数。
class GeometricProgression(Progression): # inherit from Progression
"""Iterator producing a geometric progression."""
def __init__(self, base=2, start=1):
"""Create a new geometric progression.
base the fixed constant multiplied to each term (default 2)
start the first term of the progression (default 1)
"""
super().__init__(start)
self._base = base
def _advance(self): # override inherited version
"""Update current value by multiplying it by the base value."""
self._current *= self._base
一个斐波那契数列类¶
作为最后一个例子,我们介绍如何使用数列框架来产生一个斐波那契数列( Fibonacci progression ) 。我们在 1.8 节的“生成器”部分讨论过斐波纳契数列。斐波那契数列的每一个值是最近的两个值之和。为了产生序列,通常以 0 和 1 作为最前面的两个值,从而产生斐波那契数列: 0, 1 , 1, 2 , 3 , 5 , 8 , … 一般而言,这样的数列可以从任意两个初值中生成。例如,如果从 4 和 6 开始,则产生的数列为 4, 6, 10, 16, 26, 42, …
在代码段 2-11 中,我们用数列框架来定义一个新的 FibonacciProgression 类。这个类与等差、等比数列有显著不同,因为我们不能独立地从当前值产生斐波那契数列的下一个值。我们必须得到两个最新的值。基础的 Progression 类已经提供了用以存储最新值的_current 数据成员。FibonacciProgression 类则介绍了一个名为_prev 的新成员来存储当前生成的值。
class FibonacciProgression(Progression):
"""Iterator producing a generalized Fibonacci progression."""
def __init__(self, first=0, second=1):
"""Create a new fibonacci progression.
first the first term of the progression (default 0)
second the second term of the progression (default 1)
"""
super().__init__(first) # start progression at first
self._prev = second - first # fictitious value preceding the first
def _advance(self):
"""Update current value by taking sum of previous two."""
self._prev, self._current = self._current, self._prev + self._current
先前存储的值和 _advance 的实现是直接相关的(我们使用了一个类似于 1.9 节中的同时赋值的方法) 。然而,问题是如何在构造函数中初始化先前的值。需要提供第一个和第二个值作为构造函数的参数。第一个值被存储为_current , 这样它就变为第一个被访问的值。继续计算, 一旦第一个值被访问,我们将通过赋值来设置新的当前值(第二个值将访问该值), 等于第一值加上“先前的值” 。通过 (second - first) 来初始化先前的值,初始时将 first + (second - first) = second 设置为所需的当前值
并且我们也进行了一个简单的验证
if __name__ == '__main__':
print('Default progression:')
Progression().print_progression(10)
print('Arithmetic progression with increment 5:')
ArithmeticProgression(5).print_progression(10)
print('Arithmetic progression with increment 5 and start 2:')
ArithmeticProgression(5, 2).print_progression(10)
print('Geometric progression with default base:')
GeometricProgression().print_progression(10)
print('Geometric progression with base 3:')
GeometricProgression(3).print_progression(10)
print('Fibonacci progression with default start values:')
FibonacciProgression().print_progression(10)
print('Fibonacci progression with start values 4 and 6:')
FibonacciProgression(4, 6).print_progression(10)
2.4.3 抽象基类¶
在定义一组类的继承层次结构时,避免重复代码的技术之一是设计一个基类,该基类可以被需要它的其他类所继承。例如, 2.4.2 节的层次结构中包含一个 Progression 类,它是三个不同的子类(ArithmeticProgression 类、GeometricProgression 类和 FibonacciProgression 类)的基类。虽然可以创建 Progression 基类的实例,但这样做没有价值,因为这只是一个增量为 1 的 ArithmeticProgression 类的特例。Progression 类的真正目的是集中实现其他数列需要的行为,以简化这些子类的代码。
在经典的面向对象的术语中, 如一个类的唯一目的是作为继承的基类,那么这个类就是一个抽象基类。更正式地说,一个抽象类不能直接实例化,而具体的类可以被实例化。根据这个定义, Progression 类严格来说是具体的类,尽管我们实质上把它设计为一个抽象基类。
在静态类型的语言中,如 Java 和 C++ ,抽象基类作为一个正式的类型, 可以确保一个或多个抽象方法。这就为多态性提供了支持,因为变量可以有一个抽象基类作为其声明的类型,即使它是一个具体子类的实例。因为在 python 中没有声明类型,这种多态性不需要一个统一的抽象基类就可以实现。出于这个原因, python 中没有那么强烈地要求定义正式的抽象基类,尽管 python 的 abc 模块提供了正式的抽象基类的定义。
我们之所以在研究数据结构时专注于抽象基类,是因为 python 的 collections 模块提供了几个抽象基类,来协助自定义的数据结构与一些 python 的内置数据结构共享一个共同的接口。这些抽象基类依赖于一个面向对象的软件设计模式,即模板方法模式。模板方法模式是一个抽象基类在提供依赖于调用其他抽象行为时的具体行为。在这种方式中,只要一个子类提供定义了缺失的抽象行为,继承的具体行为也就被定义了。
下面给出一个完整的例子,抽象基类 collections.Sequence 定义了 python 的 list 、str 和 tuple 类的共同行为,即通过一个整数索引访问序列中的元素。而且 collections. Sequence 类提供了 count 、index 和 _contain _方法的具体实现,可以被其他提供了_len_和_getitem _ 方法的具体实现的类所继承。出于演示的目的,我们提供了代码段 2- 14 的实现样例。
from abc import ABCMeta, abstractmethod # need these definitions
class Sequence(metaclass=ABCMeta):
"""Our own version of collections.Sequence abstract base class."""
@abstractmethod
def __len__(self):
"""Return the length of the sequence."""
@abstractmethod
def __getitem__(self, j):
"""Return the element at index j of the sequence."""
def __contains__(self, val):
"""Return True if val found in the sequence; False otherwise."""
for j in range(len(self)):
if self[j] == val: # found match
return True
return False
def index(self, val):
"""Return leftmost index at which val is found (or raise ValueError)."""
for j in range(len(self)):
if self[j] == val: # leftmost match
return j
raise ValueError('value not in sequence') # never found a match
def count(self, val):
"""Return the number of elements equal to given value."""
k = 0
for j in range(len(self)):
if self[j] == val: # found a match
k += 1
return k
这个实现依赖于 python 的两个高级技术。第一个技术是声明 abc 模块中的 ABCMeta 类作为 Sequence 类的元类。元类不同于超类,它为类定义本身提供了一个模板。具体来说,ABCMeta 声明确保类的构造函数引发异常。
第二个先进技术是在__len_ _ 和_getitem__方法声明前立即使用 @abstractmethod 声明。这就声明了这两种特定的方法是抽象的,也意味着不需要在 Sequence base 类中提供实现,但我们期望任何具体的子类来实现这两种方法。python 通过禁止没有重载抽象方法的具体实现的任何子类实例化来强制执行这个期望。
在__len__ 和__getitem__方法将存在于具体子类的假设下, Sequence 类定义的其余部分提供了其他行为的完整实现。如果你仔细检查源代码,会发现除了语法 len(self) 和 self[j] 分别通过特殊方法__len__和__getitem__支持外,__contains_和 index 的具体实现不依赖于实例本身的一切假设,迭代支持也是自动的,正如 2.3.4 节所描述的那样。
在本书的其余部分,我们省略使用 abc 模块的形式。如果需要一个抽象基类,我们只是简单地在文档中记录对子类提供的功能的期望,而不需要正式声明抽象类。但是我们将使用的抽象基类是在 collection 模块(如 Sequence) 中定义好的。使用这样的一个类,我们只需要依靠标准的继承技术。
例如, 2.3.5 节的代码段 2-6 中的 Range 类就是一个支持_len__和 _getitem__方法的类,但该类不支持方法 count 和 index 。我们最初将 Sequence 类声明为一个超类,那么它也将继承 count 和 index 方法。声明语法如下:
class Range(collections.Sequence)
最后,需要强调的是,如果一个子类对从基类继承的行为提供自己的实现,那么新的定义会覆盖之前继承的。当我们有能力自己实现一个比通用方法更有效率的方法时,这种技术就可以被使用。例如, Sequence 类中的__contains__方法的通用实现是基于在循环中搜索想要的值。但对于 Range 类,这里有一个更有效的方法。如,表达式 100000 in Range ( 0,2000000,100 ) 很明显计算为真,甚至不用去检测范围中的元素, 因为范围是从 0 开始,以 100 递增,直至数字达到 2 000 000 。它一定包括 100 000, 因为它是 100 的倍数,也在 0 ~ 2 000 000 之间。练习 C-2 . 27 提出的目标是实现 Range.__ contain__方法,并且不使用(超时)循环。
2.5 命名空间和面向对象¶
命名空间是一个抽象名词,它管理着特定范围内定义的所有标识符,将每个名称映射到相应的值。在 python 中, 函数、类和模块都是第一类对象,所以命名空间内与标识符相关的"值"可能实际上是一个函数、类或模块。
我们在 1.10 节探讨了 python 使用命名空间来管理全局范围内定义的标识符,以及在函数调用时局部范围中定义的标识符。在这一节,我们将讨论面向对象管理中命名空间的重要作用。
2.5.1 实例和类命名空间¶
首先,我们开始探讨所谓的实例命名空间,就是管理单个对象的特定属性。例如,CreditCard 类的每个实例都包含不同的余额、不同的账号、不同的信用额度等(虽然某些情况下巧合地有着相同的余额或信用额度) 。每张信用卡将有一个专用的实例命名空间来管理这些值。
每个已定义的类都有一个单独的类命名空间。这个命名空间用于管理一个类的所有实例所共享的成员或没有引用任何特定实例的成员。例如, 2.3 节的 CreditCard 类中的 make_payment 方法不是被该类中的每个实例单独存储,该成员函数存储在 CreditCard 类的命名空间中。基于代码段 2-1 和 2-2 中的定义, CreditCard 类的命名空间包含的函数有__init__、__ get customer_ _、get_bank ,get_account 、get_balance 、get_ limit 、charge 和 make_payment。PredatoryCreditCard 类有自己的命名空间,其中包含了我们为该子类定义的三种方法.__init__、charge 和 process_month 。
图 2-8 提供了三个命名空间: 第一个类命名空间包含 CreditCard 类的方法,第二个类命名空间包含 PredatoryCreditCard 类的方法,最后一个是 PredatoryCreditCard 类的实例命名空间。我们注意到名为 charge 的函数有两种不同的定义: 一个是在 CreditCard 类,另一个是在 PredatoryCreditCard 类中重写了该方法。类似的,也有两种不同的__init__实现。但 process_ month 是仅在 PredatoryCreditCard 类的范围内定义的名字。实例命名空间包含了该实例的所有数据成员( 包括 PredatoryCreditCard 类构造方法中定义的_apr 成员)

条目是怎样在命名空间中建立的¶
为什么有的成员(如_balance ) 驻留在 Credit Card 类的实例命名空间,而有的成员(如 make_payment ) 驻留在类命名空间?理解这一问题是非常重要的。当新的信用卡实例构造好后, balance 成员就在__init__建立起来了。原始的赋值使用语法 self.balance = 0, 其中 self 是新创建实例中的标识符。在这种赋值中, self._balance 中 self 作为限定符使用,这使得_balance 标识符直接被添加到实例命名空间中。
当使用继承时,每个对象仍有单一的实例命名空间。例如, 当构造 PredatoryCreditCard 类的一个实例后, _apr 属性以及如_balance 和_limit 等属性都驻留在该实例的命名空间,因为所有赋值都使用一个特定的语法,如 self._apr。
一个类命名空间包含所有直接在类定义体内的声明。例如, CreditCard 类定义有以下结构:
class CreditCard:
def make_payment(self, amount)
...
因为 make_payment 函数是在 CreditCard 类中声明的,所以它也与 CreditCard 类命名空间中的名字 make_payment 相关联。尽管成员函数是最典型的在类命名空间中声明的条目类型,但我们接下来还会讨论其他数据值的类型,甚至讨论其他类是怎样在类命名空间中声明的。
类数据成员¶
当有一些值(如常量),被一个类的所有实例共享时,我们就会经常用到类级的数据成员。在这种情况下,在每个实例的命名空间中存储这个值就会造成不必要的浪费。例如,我们回顾一下 2.4.1 节中介绍的 PredatoryCreditCard 类,在该类中会因为信用卡额度限制而使试图支付 5 美元费用的操作失败。我们选择 5 美元的费用是有点随意的,如果使用命名变量,而不是将文字值嵌入代码中,我们的编码风格会更好。通常,这些费用的数额是由银行的政策决定的,对每个客户都一样。这种情况下,我们可像如下样式定义和使用类数据成员:
class PredatoryCreditCard(CreditCard):
OVERLIMIT_FEE = 5 #this 1s a class-level member
def charge(self, price):
success = super().charge(price)
if not success:
self._ balance += PredatoryCreditCard.OVERLIMIT_FEE
return success
数据成员 OVERLIMIT_FEE 直接进入 PredatoryCreditCard 类命名空间,因为赋值在类定义的直接范围内发生,并且没有任何限定标识符。
嵌套类¶
在另一个类的范围内嵌套一个类定义也是可行的。这是一个有用的结构,我们在本书的数据结构实现中多次予以探讨。可以使用如下语法完成:
class A: # the outer class
class B: # the nested class
...
在这种情况下, B 类是嵌套类。标识符 B 是进入了 A 类的命名空间相关联的一个新定义的类。我们注意到这种技术与继承的概念无关,因为 B 类不继承 A 类。
在一个类中嵌套另一个类,这表明嵌套类的存在需要外部类的支持。此外,它有助于减少潜在的命名冲突,因为它允许类似的命名类存在于另一个上下文中。例如,我们稍后将介绍链表的数据结构,它通过定义一个嵌套节点类来存储列表的各个组件。我们还介绍树的数据结构,这取决于其自身的嵌套节点类。这两个结构根据不同的节点定义,我们可以通过在各自的容器类中嵌套各自的节点定义来避免歧义。
将一个类嵌套为另一个类的成员还有一个优点,就是它允许更高级形式的继承,使外部类的子类重载嵌套类的定义。我们将在 11.2 节中实现树结构的节点时使用这种技术。
字典和 __slots__声明¶
默认情况下, python 中的每个命名空间均代表内置 diet 类的一个实例(参见 1.2.3 节),即将范围内识别的名称与相关联的对象映射起来。虽然字典结构支持相对有效的名称查找,但它需要的额外内存使用量超出了它存储原始数据的内存(我们将在第 10 章探讨实现字典的数据结构) 。
python 提供了一种更直接的机制来表示实例命名空间,以避免使用一个辅助字典。使用流表示一个类的所有实例,类定义必须提供一个名为_slots_的类级别的成员分配给一个固定的字符串序列以此服务于变量。例如,在 CreditCard 类中,声明如下:
class Credit Card:
__slots__ = '_customer','_bank','_account', '_balance' , '_limit'
在这个例子中,赋值的右边是一组元组(见 1.9.3 节元组的自动打包) 。
如果使用继承时, 基类声明了__slots__ ,那么为了避免字典实例的创建,子类也必须声明 __slots 。子类的声明只需包含新创建的补充方法的名称。例如, PredatoryCreditCard 的声明如下:
class PredatoryCreditCard (CreditCard)
__ slots __ = '_apr' # in addition to the inherited members
我们可以选择使用__slots__简化本书中每个类的声明, 但并不会这样做,因为这样将使 python 程序非典型。也就是说, 这本书里有几个类, 我们希望有大量的实例, 每个代表一个轻量级构造。例如,当讨论嵌套类, 我们建议链表和树作为数据结构通常来组成大量的个体节点。为了更好地提升内存使用效率,我们将在所有期望有很多实例的嵌套类中使用显式的_slots__声明。
下面是用以辅助理解的外部资料
正常情况下,当我们定义了一个 class,创建了一个 class 的实例后,我们可以给该实例绑定任何属性和方法,这就是动态语言的灵活性。先定义 class:
class Student(object): pass然后,尝试给实例绑定一个属性:
>>> s = Student() >>> s.name = 'Michael' # 动态给实例绑定一个属性 >>> print(s.name) Michael还可以尝试给实例绑定一个方法:
>>> def set_age(self, age): # 定义一个函数作为实例方法 ... self.age = age ... >>> from types import MethodType >>> s.set_age = MethodType(set_age, s) # 给实例绑定一个方法 >>> s.set_age(25) # 调用实例方法 >>> s.age # 测试结果 25但是,给一个实例绑定的方法,对另一个实例是不起作用的:
>>> s2 = Student() # 创建新的实例 >>> s2.set_age(25) # 尝试调用方法 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Student' object has no attribute 'set_age'为了给所有实例都绑定方法,可以给 class 绑定方法:
>>> def set_score(self, score): ... self.score = score ... >>> Student.set_score = set_score给 class 绑定方法后,所有实例均可调用:
>>> s.set_score(100) >>> s.score 100 >>> s2.set_score(99) >>> s2.score 99通常情况下,上面的
set_score方法可以直接定义在 class 中,但动态绑定允许我们在程序运行的过程中动态给 class 加上功能,这在静态语言中很难实现。使用slots¶
但是,如果我们想要限制实例的属性怎么办?比如,只允许对 Student 实例添加
name和age属性。为了达到限制的目的,python 允许在定义 class 的时候,定义一个特殊的
__slots__变量,来限制该 class 实例能添加的属性:class Student(object): __slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称然后,我们试试:
>>> s = Student() # 创建新的实例 >>> s.name = 'Michael' # 绑定属性'name' >>> s.age = 25 # 绑定属性'age' >>> s.score = 99 # 绑定属性'score' Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Student' object has no attribute 'score'由于
'score'没有被放到__slots__中,所以不能绑定score属性,试图绑定score将得到AttributeError的错误。使用
__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的:>>> class GraduateStudent(Student): ... pass ... >>> g = GraduateStudent() >>> g.score = 9999除非在子类中也定义
__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。
2.5.2 名称解析和动态调度¶
在上一节中,我们讨论了各种命名空间以及建立访问命名空间的机制。在本节中,我们将研究在 python 的面向对象框架中检索名称时的过程。当用点运算符语法访问现有的成员(如 obj.foo ) 时, python 解释器将开始一个名称解析的过程,描述如下:
- 在实例命名空间中搜索,如果找到所需的名称,关联值就可以使用。
- 否则在该实例所属的类的命名空间中搜索,如果找到名称, 关联值可以使用。
- 如果在直接的类的命名空间中没有,搜索仍在继续,通过继承层次结构向上,检查每一个父类的类名称空间(通常通过检查超类,接着是超类的超类, 等等) 。第一次找到这个名字,它的关联值可以使用。
- 如果还没有找到该名称,就会引发一个 AttributeError 异常。
举一个实际的例子,假设 mycard 标识的 PredatoryCreditCard 类的一个实例。考虑以下可能的使用模式:
mycard._balance( 等价于内部方法体中的self._balance) : 在 mycard 实例命名空间中找到_balance 方法。mycard.process_month(): 开始搜索实例命名空间,但是在这个名称空间没有找到 process_month() 。因此,在 PredatoryCreditCard 类命名空间搜索; 在本例中,这个名字找到了,方法也调用了。mycard.make_Payment(200): 没有在实例命名空间和 PredatoryCreditCard 类命名空间中找到 make__payment , 该名称是在超类 CreditCard 中解析出来的,继承方法也被调用了。mycard.charge(50): 在实例命名空间中搜索 charge 名称失败。接着检查 PredatoryCreditCard 类的命名空间,因为这是实例的真实类型。在该类中有一个 charge 函数的定义, 该方法也可以调用
最后一个案例显示, PredatoryCreditCard 类的 charge 函数重载了 CreditCard 命名空间中 charge 函数的版本。在传统的面向对象术语中, python 使用动态调度( 或动态绑定)来确定运行时基于调用其对象的类型实现函数的调用,这与一些使用静态调度的语言相似,即在编译时基于变量声明的类型来决定调用函数的版本。
2.6 深拷贝和浅拷贝¶
在第 1 章中,我们曾强调,一个赋值语句 foo = bar 使对象 bar 有一个别名 foo 。在本节中,我们考虑的是拷贝对象的一个副本,而不是一个别名。在应用程序中,当我们想以一种独立的方式修改原始的或拷贝的内容时,这是非常必要的。
考虑这样一个场景:在该场景中,每个颜色代表假定颜色类的一个实例。我们让标识符 warmtones 表示现有的颜色(如橙色、棕色)列表。在这个应用程序中,我们希望创建一个名为 palette 的新列表,复制一份 warmtones 列表。不过,我们想随后可以在 palette 中添加额外的颜色,或修改、删除一些现有的颜色,而不影响 warmtones 的内容。如果执行命令
palette = warmtones
就创建了一个别名,如图 2-9 所示,没有创建新的列表。相反,新的标识符 palette 参考原先的列表。
不幸的是,这不符合我们的期望,因为如果随后在 palette 中添加或删除颜色,我 palette = list(warmtones)们同时也会修改列表 warmtones 。
我们可以用以下语法创建一个新的列表实例:
palette = list(warmtones)
在这种情况下,我们显式调用列表构造函数,将第一个列表作为参数,这将导致一个新的列表被创建,如图 2-10 所示,这被称为浅拷贝。新的列表被初始化,以便其内容与原来的序列相同。然而, python 的列表是用作参考的(见 1.2.3 节),所以新列表与原列表代表了引用相同元素的顺序。
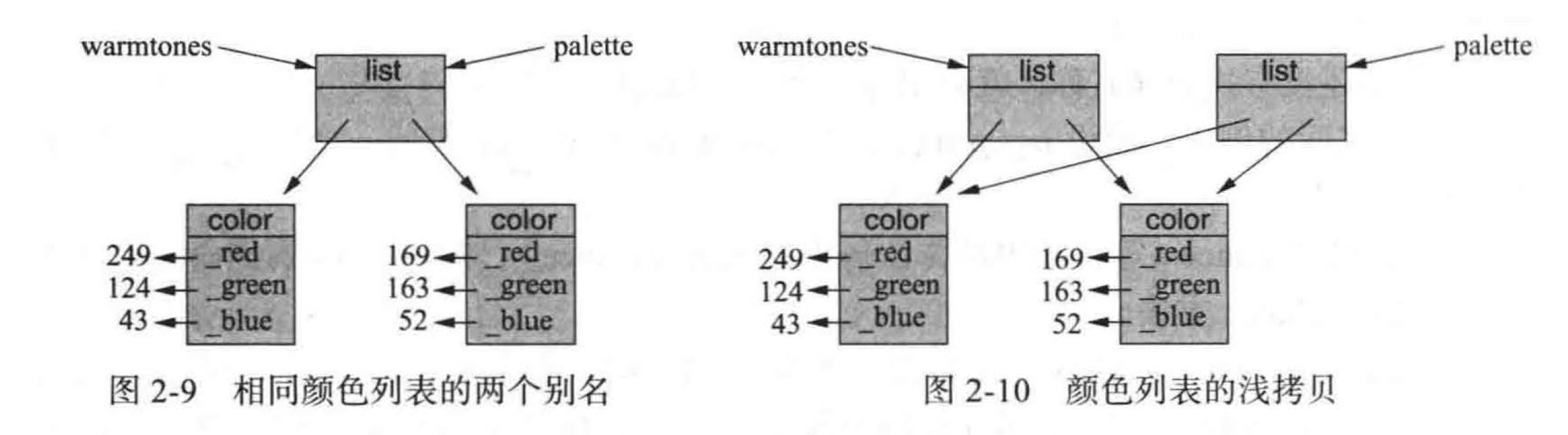
这比第一次尝试的情况更好,我们可以合理地从 palette 添加或删除元素而不影响 warmtones 。然而,如果编辑 palette 中的颜色实例列表,则相对改变了 warmtones 的内容。尽管 palette 和 warmtones 是不同的列表,但仍有间接的混叠,例如, palette[0] 和warmtones[0] 为相同颜色实例的别名。
可以如此理解,浅拷贝虽然建立了两个不同的列表,但在两个不同列表中的元素仍然指向同一变量,即仍然是同一变量的别名,因此虽然删去元素不会影响到原列表(仅仅只是删去了一指针),但是修改变量仍会影响到原列表中变量的值
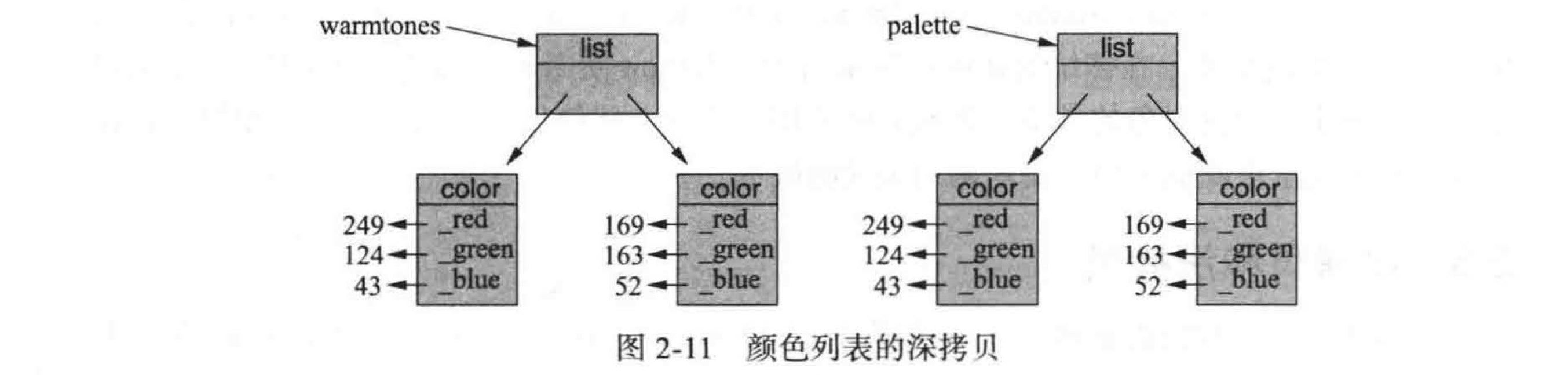
我们更希望 palette 是 warmtones 的深拷贝。在深拷贝中,新副本引用的对象也是从原始版本中复制过来的(见图 2-11 ) 。
python 的 copython 模块¶
要创建一个深拷贝,可以通过显式复制原始颜色实例来填充列表,但这需要知道如何复制颜色(而不是别名) 。python 提供了一个很方便的模块,即 copython, 它能产生任意对象的浅拷贝和深拷贝。
该模块提供两个函数: copython 函数和 deepcopython 函数。copython 函数创建对象的浅拷贝,deepcopython 函数创建对象的深拷贝。引入模块后,我们可以为例子创建一个深拷贝,如图 2-11 所示,所使用的命令如下:
palette = copython.deepcopython(warmtones)