Data efficient and weakly supervised computational pathology on whole slide images(CLAM)
Abstract¶
计算机辅助病理学的深度学习方法通常要求手动标注千兆像素的全幻灯片图像(WSIs) 或带有全幻灯片级别标签的大型 WSI 数据集,并且通常在域适应和可解释性方面存在问题。在这里,我们报道了一种可解释的、弱监督的深度学习方法,用于高效处理和学习 WSI,只需要全幻灯片级别的标签。该方法被命名为聚类约束注意力多实例学习(CLAM),它使用基于注意力的学习来识别具有高诊断价值的子区域,从而准确分类整个幻灯片,并在已识别的代表性区域上应用实例级聚类来约束和优化特征空间。通过将 CLAM 应用于肾细胞癌和非小细胞肺癌的亚型分型以及淋巴结转移的检测,我们展示了它可以在不需要空间标签的情况下定位已知的形态特征,优于标准的弱监督分类算法,并且适应独立的测试集、智能手机显微镜和不同的组织内容。
Main¶
数字病理学和人工智能的进展为分析千兆像素全幻灯片图像(WSIs)进行客观诊断、预后和治疗反应预测提供了潜力。除了即时的临床益处外,计算机辅助病理学在多项不同任务中展示了其潜力,包括量化组织微环境、进行整合的图像组学分析、识别与预后相关的形态特征以及将形态与治疗反应和耐药性相关联。
虽然深度学习已经通过解决许多图像分类和预测任务革新了医学成像,但全幻灯片成像是一个具有多个独特挑战的复杂领域。基于深度学习的计算机辅助病理学方法要么在全监督环境中手动标注千兆像素的 WSIs,要么在弱监督环境中使用带有全幻灯片级别标签的大型数据集。鉴于全幻灯片级别的标签可能仅对应于每个大型千兆像素图像的微小区域,大多数方法依赖于对显著定位这些“大海中的针”的像素、块或感兴趣区域(ROI)进行标注。虽然将相同的标签分配给 WSI 中的每个块的方法已经取得了有希望的结果,但该方法存在噪声训练标签的问题,并且不适用于可能具有有限肿瘤内容(例如微转移)的问题。此外,如果在 ROI 或块级别只对 WSI 中的一部分组织区域进行采样进行训练,模型在测试时可能泛化能力不强,无法提供有用的全幻灯片解释性。最近的研究工作表明,使用全幻灯片级别标签在弱监督环境中训练二元分类器进行患者分层时,可以实现出色的临床级性能,基于多实例学习(MIL)的变体。然而,据报道,为了达到完全监督和 ROI 级分类器相当的性能,这种方法需要数千个 WSIs。这样的大型数据集虽然对于捕捉组织学中存在的巨大多样性和异质性非常重要和有益,但对于只有少数示例存在的罕见诊断或对于可能从小的患者队列中预测结果有用的临床试验来说,很难策划。此外,要从 ROI 或块级别的预测中产生全幻灯片级别的预测,弱监督的全幻灯片分类方法通常需要选择一个固定的、预定义的聚合函数(例如,最大池化或对 ROI 进行平均),并且可能不适用于二元肿瘤与正常分类和多类组织亚型分型问题,其中没有正常组织幻灯片可用。此外,当使用块级监督进行训练的深度学习诊断模型在来自不同来源和成像设备的数据上进行测试时,其性能已被证明存在问题。这样的方法还需要具有可解释性,能够显著定位用于作出预测决策的区域。总之,为了在临床和研究环境中更广泛地推广计算机辅助病理学,需要不需要手动 ROI 提取、像素/块级别标记或简单采样的方法,这些方法仍然具有数据效率、可解释性、适应性和通用性,可以适用于二元分类和多类分型问题。
在本文中,我们提出了一种名为聚类约束注意力多实例学习(CLAM)的高吞吐量深度学习框架,旨在解决上述全幻灯片级计算机辅助病理学的关键挑战。在三个单独的分析中(肾细胞癌(RCC)和非小细胞肺癌(NSCLC)的亚型分型以及淋巴结转移的检测),我们使用公开可用的数据集以及独立的测试队列,展示了我们的方法在不同任务中的数据效率和高性能,同时使用逐步减少的训练标签数量。我们通过展示在组织切除 WSIs 上训练的模型可以直接应用于活检 WSIs 以及使用独立测试队列中的数据进行消费级智能手机拍摄的光学显微镜照片,展示了 CLAM 的适应性。我们还展示了 CLAM 可以推广到多类分类和亚型分型问题,而不仅仅是在弱监督环境中通常研究的二元肿瘤与正常分类任务。我们的研究提出了
一个计算机辅助病理学框架,将基于注意力的多实例聚合扩展到通用的多类弱监督 WSI 分类,无需任何像素级注释、ROI 提取或采样。我们通过首先使用迁移学习和具有预训练参数的卷积神经网络(CNN)编码器进行维度约减,从而实现这一目标,这也有助于大大提高模型训练速度。通过使用基于注意力的学习,CLAM 能够生成可解释的热图,允许临床医生可视化每张幻灯片的每个组织区域对模型预测的相对贡献和重要性,而在训练过程中不使用任何像素级标注。这些热图显示,我们的模型能够识别病理学家用于进行诊断决策的众所周知的形态特征,并且在没有使用任何正常幻灯片或 ROI 进行训练的情况下,模型能够区分肿瘤和邻近正常组织。CLAM 作为一个易于使用的 Python 包公开可用于 GitHub(https://github.com/mahmoodlab/CLAM),并且可以在我们的交互式演示(http://clam.mahmoodlab.org)中查看全幻灯片级别的注意力图。
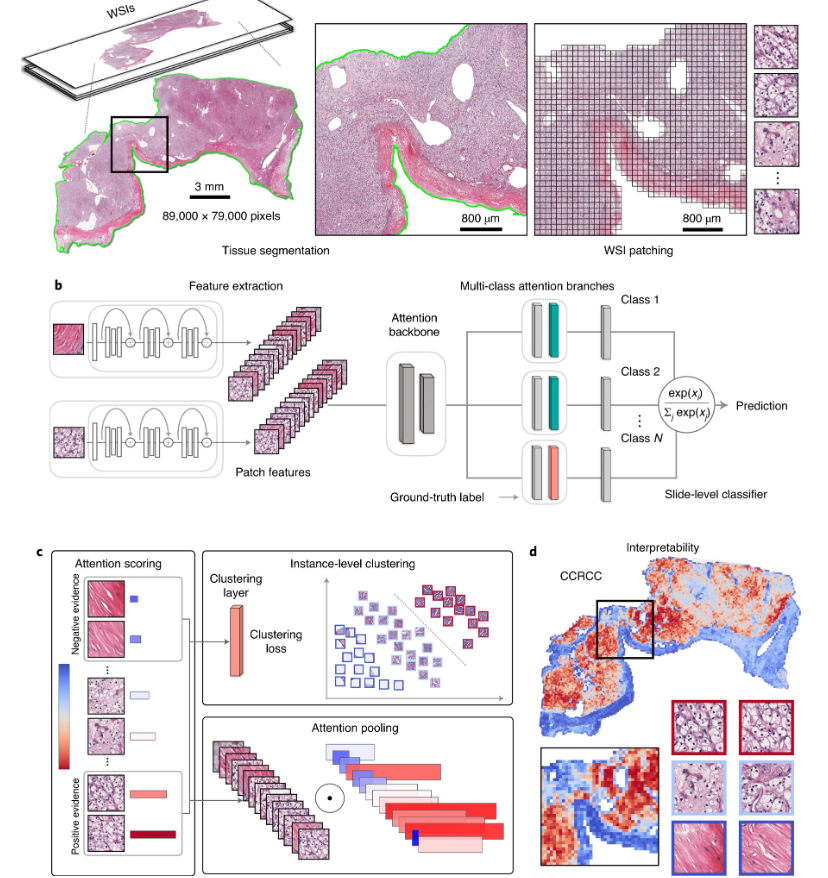
a. 在分割之后(左图),从 WSI 的组织区域提取图像块(右图)。 b. 块通过预训练的 CNN 进行编码,得到描述性的特征表示。在训练和推断过程中,每个 WSI 中提取的块被作为特征向量传递给 CLAM 模型。注意力网络用于将块级别的信息聚合成幻灯片级别的表示,这些表示用于进行最终的诊断预测。 c. 对于每个类别,注意力网络对幻灯片中的每个区域进行排名,并根据其对幻灯片级别诊断的相对重要性分配注意力分数(左图)。注意力池化根据各自的注意力分数对块进行加权,并将块级别特征汇总为幻灯片级别表示(右下方)。在训练过程中,给定地面真实标签,强烈关注的(红色)和弱关注的(蓝色)区域还可以用作代表性样本,监督聚类层学习一个丰富的、能够将正负实例的不同类别分开的块级别特征空间(右上方)。 d. 注意力分数可以可视化为热图,以识别 ROI 并解释诊断所使用的重要形态特征。
除了采用基于注意力池化的聚合规则 37 代替最大池化外,我们还探索了其他方法来解决现有计算病理学弱监督学习算法中的数据效率问题。具体而言,我们利用幻灯片级地面真实标签和网络预测的注意力分数来为高度和弱关注的块生成伪标签,以增加学习可分离块级特征空间的监督信号的技术。在训练过程中,网络通过额外的监督学习任务,将每个类别中最受关注和最不受关注的块分为不同的聚类簇。此外,还可以将领域知识纳入到实例级别的聚类中,以增加进一步的监督。例如,癌症亚型通常是互斥的,或者在分类过程中被假设为互斥的。如果采用互斥假设,除了对存在地面真实类别的注意力分支进行监督外,还可以通过将高度关注的实例聚类作为其各自类别的“假阳性”(即负面)证据,来监督与其余类别相对应的注意力网络分支。在实践中,如果假设给定幻灯片中只存在与单一类别对应的形态,还可以选择使用单个注意力模块而不是多个分支的较简单框架,在计算聚类损失时,始终将来自注意力模块的高注意力块视为地面真实类别的正面证据,而将其视为其余类别的假阳性证据。
为了使 CLAM 成为研究人员可以轻松采用和利用的高吞吐量流水线,而无需专用的高性能计算集群,我们还提出并提供了一个开源的易于使用的 WSI 处理和学习工具包。我们的流水线首先自动分割每个幻灯片的组织区域,并将其分割为许多较小的块(例如 256×256 像素),以便它们可以直接作为 CNN 的输入(图 1a)。接下来,使用 CNN 进行特征提取,将所有组织块转换为低维特征嵌入集(图 1b)。在进行特征提取之后,训练和推断可以在低维特征空间而不是高维像素空间中进行。数据空间的体积减少了近 200 倍,我们可以大大减少训练监督深度学习模型所需的后续计算量。我们发现,在低维特征空间中进行训练使得可以在现代工作站上,使用消费级图形处理单元(GPU),在几小时内对数千个基于吉格像素的切除幻灯片进行模型训练。
在接下来的几节中,我们将展示 CLAM 在三个不同的计算病理学问题上的数据效率、适应性和可解释性:(1) 肾细胞癌亚型分类,(2) 非小细胞肺癌亚型分类,以及(3) 乳腺癌淋巴结转移的检测。我们还展示了在 WSI 上训练的 CLAM 模型对智能手机显微图像和活检切片的适应性。
Results¶
我们使用 10 折 Monte Carlo 交叉验证评估了 CLAM 在上述三个临床诊断任务中的幻灯片级分类性能。对于每个交叉验证折叠,我们将每个公共 WSI 数据集随机划分为训练集(80%的案例)、验证集(10%的案例)和测试集(10%的案例),并按每个类别分层。如果单个病例有多个幻灯片,则将它们一起采样到同一集合中。在每个折叠中,模型在验证集上的性能在训练过程中进行监控,并用于模型选择,而测试集则被保留,在训练完成后只使用一次来评估模型。在癌症基因组图谱(TCGA)RCC 数据集上(图 2a),模型在 20 倍放大率下对乳头状(PRCC)、颗粒性(CRCC)和透明细胞(CCRCC)RCC 的三类亚型进行了 10 倍宏平均的一对剩余曲线(AUC)的测试,结果为 0.991±0.004。有关每个亚型的一对剩余 AUC,请参见补充图 1。在合并的 TCGA 和临床蛋白质组肿瘤分析联盟(CPTAC)NSCLC 数据集上,对肺腺癌(LUAD)和鳞状细胞癌(LUSC)的两类亚型进行了 20 倍放大率下的测试,模型的平均测试 AUC 为 0.956±0.020(图 2b)。在 CAMELYON16 和 CAMELYON17 数据集上,用于检测乳腺癌在腋窝淋巴结中的转移,模型在 40 倍放大率下的平均测试 AUC 为 0.953±0.029(图 2c)。附加的性能指标见补充表 1-3。我们的所有训练数据都来自公开可用的数据源,尽管它们代表了一些最大的公共 WSI 数据集,但比起几篇最近的研究中研究的专有标记数据集,它们的规模要小 5,36 倍。然而,尽管使用的数据集规模适中(分别为 884、1,967 和 899 个总幻灯片,其中每个折叠只使用大约 80%用于训练),在所有三个任务中获得的高性能(>0.95 AUC)表明我们的方法可以有效应用于解决传统的阳性与阴性癌症检测二分类问题以及更一般的多类癌症亚型分类问题,适用于各种组织类型。
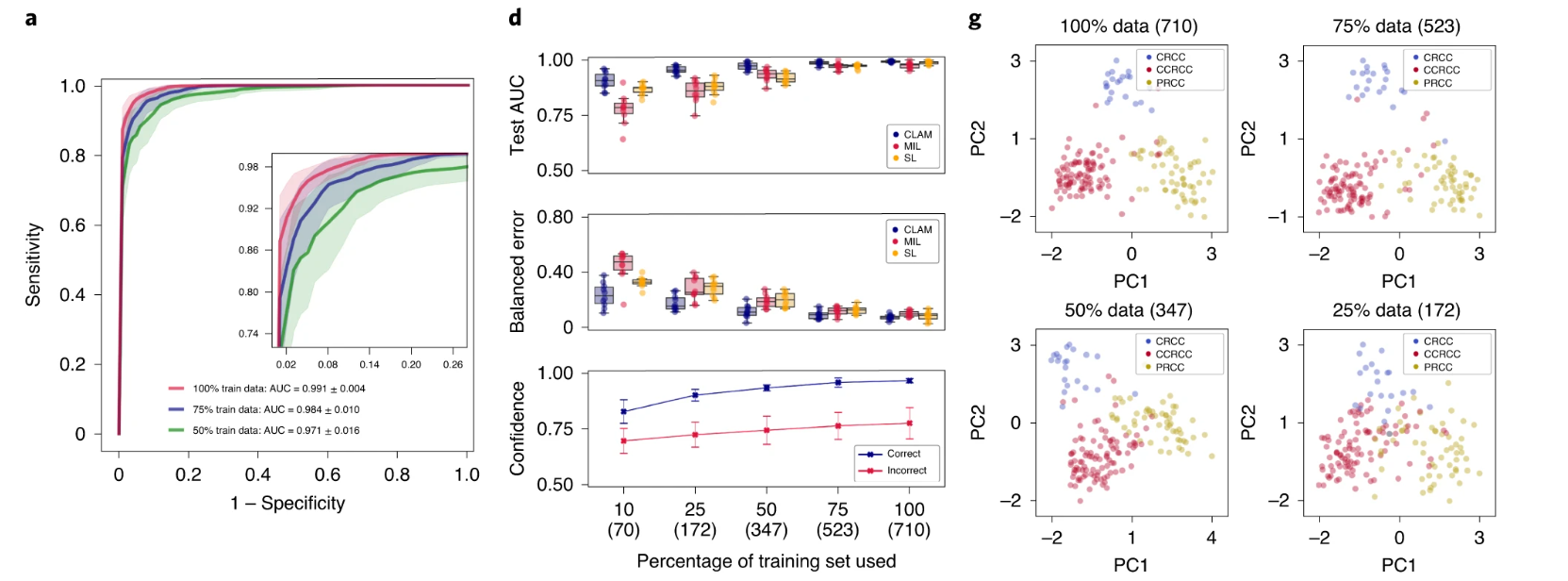
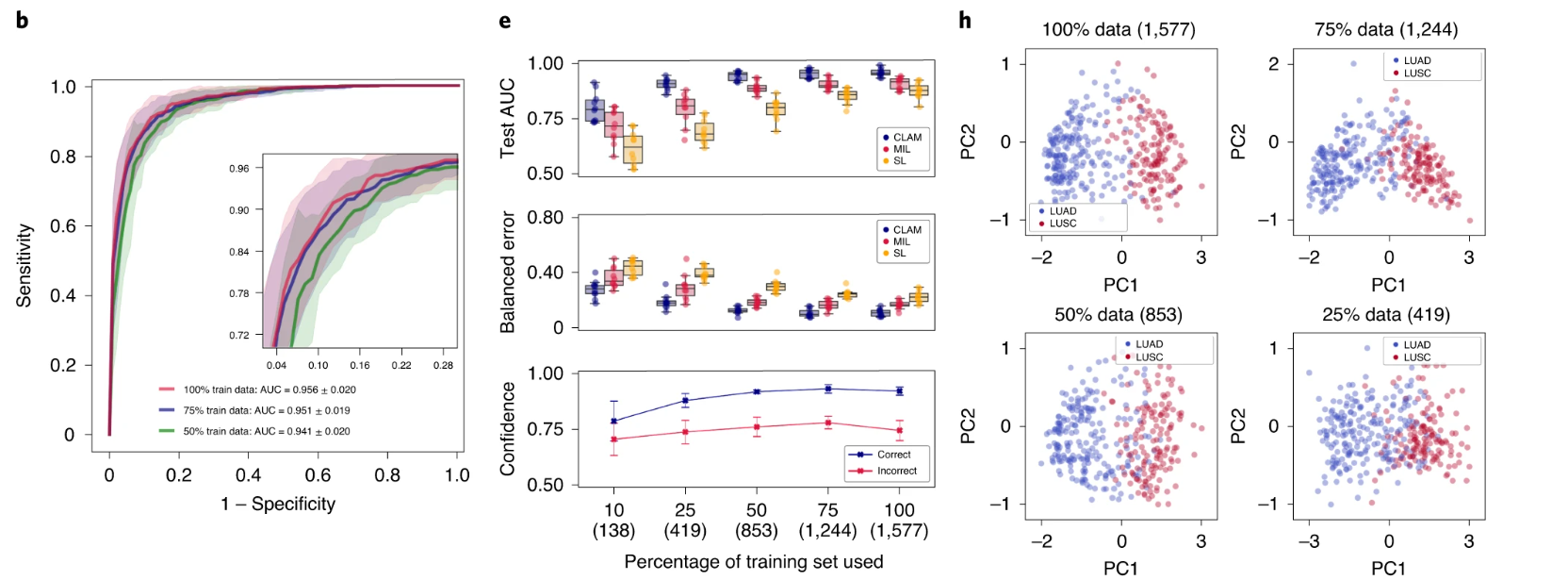
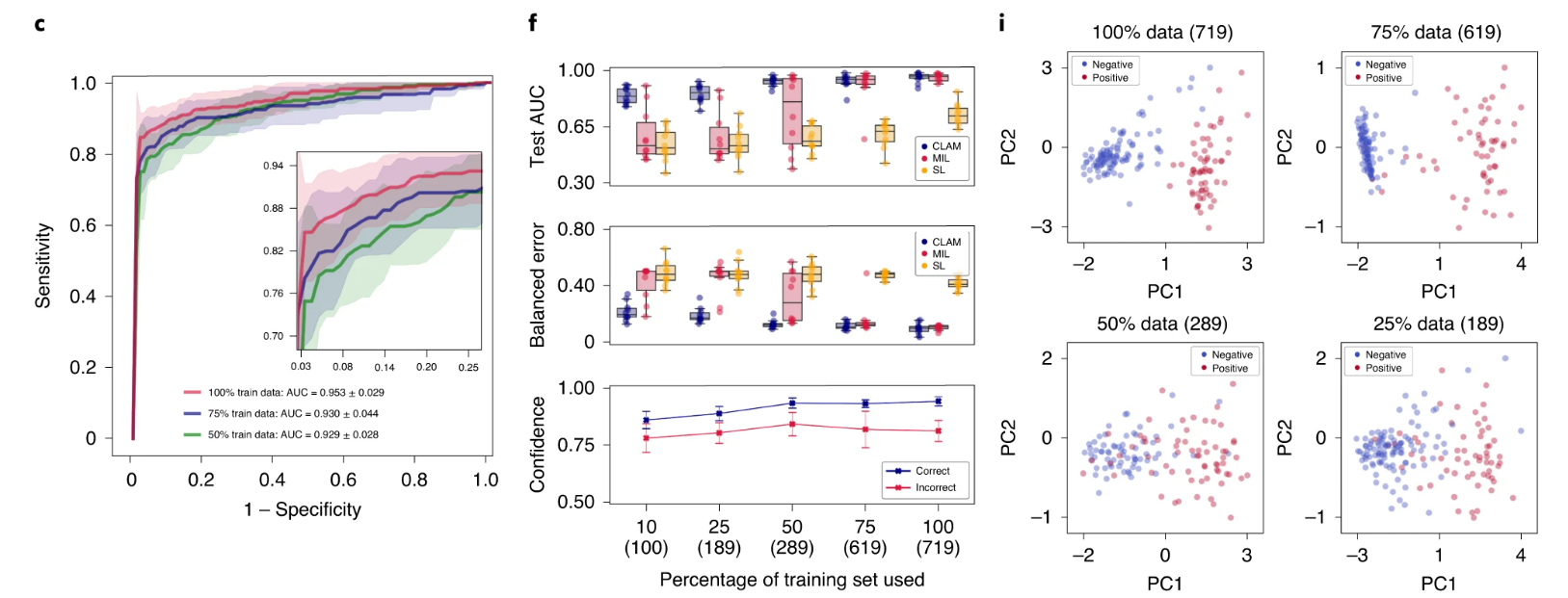
a–i. 对于 RCC 亚型分类(a,d,g;n=86)、NSCLC 亚型分类(b,e,h;n=196)和淋巴结转移检测(c,f,i;n=89),对 CLAM 模型的 10 折 Monte Carlo 交叉验证预测结果和测试性能进行了分析。a–c,CLAM 模型使用训练集中 100%、75%和 50%的案例的平均测试 AUC± 标准差。置信带显示了平均受试者工作特征曲线的 ±1 个标准差。对于多类 RCC 亚型分类,报告了宏平均曲线和 AUC。插图:曲线的放大视图。d–f,以盒形图形式显示了各种弱监督分类算法的数据集大小相关性能,包括 10 倍交叉验证的测试 AUC(顶部)和平衡错误分数(中间),每个训练集大小(100%、75%、50%、25%和 10%的案例)一个盒子表示四分位值,须延伸至内四分位距的 1.5 倍的数据点。 CLAM 模型对正确和错误分类的幻灯片进行预测的平均置信度(±1 个标准差)(底部)。g–i,对 CLAM 模型的学习幻灯片级特征空间进行可视化;在 PCA 之后,用于模型预测的最终幻灯片级特征表示在单个交叉验证折叠的验证集和测试集中绘制每个幻灯片。PC 表示主成分。d–i,括号中显示了每个训练集大小所使用的幻灯片数量。
标记的 WSI 数据通常难以获取,并且在罕见疾病(例如 CRCC)、异常发现或临床试验的情况下,收集数千张幻灯片可能是不可行的。鉴于这些限制,为了研究我们模型的数据效率,我们顺序抽取训练数据的子集,分别相当于每个交叉验证期间训练集中总病例数的 75%、50%、25%和 10%。对于每个子采样的训练集,相应的测试集保持不变,以研究模型性能与可用训练数据量的依赖关系。我们还保持了每个对应的验证集不变,以避免将模型选择标准引入作为对模型测试性能的额外混淆变量。当使用较小的样本训练集对 CLAM 模型进行监督时,我们观察到实现满意性能(AUC> 0.9)所需的幻灯片数量因分类任务而异。例如,对于 RCC 亚型分类,仅使用总可用训练案例的 25%(每个交叉验证折叠平均约 170 张幻灯片)就足以实现平均测试 AUC 超过 0.94;而对于 NSLCC 亚型分类和淋巴结转移检测,可能需要 lung 训练集的 25%(419 张幻灯片)和淋巴结转移数据集的 50%(289 张幻灯片)。最后,为了研究注意池化相对于最大池化的价值,我们将 CLAM 与 MIL 和其他流行的弱监督方法进行了性能比较,其中其他方法假设每个 patch 具有相同的幻灯片级标签,标记为“same label”(SL)。我们为三类 RCC 亚型分类实现了多类 MIL 的变体,标记为 mMIL(有关技术细节,请参见方法部分)。在我们的比较研究中,我们发现对于所有任务和训练集大小,CLAM 始终优于基于最大池化的算法(图 2d–f)。当使用较少的幻灯片进行训练时,CLAM、基于最大池化的算法和 SL 之间的 AUC 差异更为明显。例如,SL 在 RCC 亚型分类的 100%和 75%训练数据上表现出合理的性能,可能是因为 TCGA RCC 数据集中存在较高的肿瘤内容,这意味着当将幻灯片级诊断分配给每个 WSI 中的所有区域时,SL 使用的大多数训练标签将是正确的。另一方面,对于淋巴结转移检测,SL 表现较差,因为转移灶的面积可能很小且稀疏,这导致在将幻灯片级标签朴素地分配给每个幻灯片中的每个组织位置时存在大量标签噪声。总体而言,我们注意到 CLAM 具有高效的数据性能,通常只需几百张幻灯片即可实现测试 AUC> 0.9。为了研究 CLAM 中的实例级聚类任务是否有助于提高数据效率,我们在不同大小的训练集上进行了消融研究,并观察到在训练集大小较小时,额外的实例级监督可以提高模型性能(见补充表 4)。
我们还进行了实验,使用 60/10/30 和 40/10/50 的分区(而不是 80/10/10 的训练/验证/测试分区)来评估不同算法在数据约束条件下的性能,从而可以在更大的测试集上评估模型(补充表 5)。为了与未来的研究进行比较,我们还使用了公开可用的 TCGA、CPTAC 和 CAMELYON 数据集进行了额外的实验(有关详细信息,请参见补充表 6)。
此外,我们还分析了 CLAM 在更大相关研究范畴中的表现(补充表 7),并对我们用于三种不同诊断任务的公开数据集进行了评估。首先,我们将 CLAM 应用于公开的 CAMELYON16 淋巴结转移检测挑战赛。我们在官方的训练集上进行了训练(在训练期间没有使用任何像素级别的注释),将 270 个 WSI 划分为约 85%的训练集和 15%的验证集。我们最好的模型在 129 个 WSI 的官方测试集上实现了 0.936 的测试 AUC(95%置信区间(CI):0.890–0.983)。考虑到训练过程中没有使用像素级别的标签,这是一个令人鼓舞的结果。类似地,我们训练了一个 CLAM 模型,以在仅使用 TCGA 诊断 WSI 的情况下进行 NSCLC 亚型分类,在该情况下,15%的病例(80 个 LUAD 和 81 个 LUSC WSI)作为测试集,其余数据划分为 85%的训练集和 15%的验证集。该模型实现了 0.963 的测试 AUC(95% CI:0.937–0.990)。
Generalization to independent test cohorts¶
由于组织处理、幻灯片制备和数字化方面的机构标准和协议存在差异,WSI 的图像外观可能存在很大的差异。因此,验证在 CLAM 弱监督框架下使用公开可用的数据源训练的模型是否对数据特定变量具有鲁棒性,并且是否能够推广到在训练过程中未遇到的扫描仪和染色协议的真实临床数据非常重要。为了评估我们训练的模型的泛化性能,我们在 Brigham and Women's Hospital(BWH)收集和扫描了总共 135 张 RCC(CRCC,43 张;CCRCC,46 张;PRCC,46 张)、131 张 NSCLC(LUAD,63 张;LUSC,68 张)和 133 张淋巴结(阴性,66 张;阳性,67 张)幻灯片作为独立的测试队列(在方法和补充表 8 中进一步解释)。对于每个任务和训练集大小,在我们的公开数据集上进行交叉验证训练的十个模型直接在完全保留的独立测试集上进行评估。我们观察到,在较小的训练集分组中,不同模型的交叉验证性能差异往往更大。在这种情况下,使用单个表现最佳的模型进行测试可能会产生数据效率的错觉,尽管算法在独立测试集上的性能会不一致,并且在使用不同随机训练数据分割开发的模型之间会高度变化。为了适应这一点,我们使用了所有十个模型的平均性能(而不是单个选定的模型)来估计我们算法在每个训练集大小上的性能。在独立测试队列上进行测试时,使用 10 倍交叉验证的 CLAM 模型在使用 100%的训练集进行训练后,在 RCC 亚型分类上实现了平均的一对多 AUC(宏平均)为 0.972 ± 0.008,在 NSCLC 亚型分类上实现了平均 AUC 为 0.975 ± 0.007,在腋窝淋巴结转移检测上实现了平均 AUC 为 0.940 ± 0.015(图 3a–c)。此外,我们观察到,即使 CLAM 模型只是在完整训练集的较小子集上进行训练,它们也可以在来自独立来源的数据上实现可观的性能(测试 AUC>0.9)(图 3d–f)。与 mMIL/MIL 和 SL 相比,CLAM 在所有任务和训练集大小上都提供了改进的性能(图 3d–f,顶部和中部),尤其是在受限的训练数据情况下。例如,当使用完整训练集的 25%进行训练时,CLAM 在 RCC 亚型分类、NSCLC 亚型分类和淋巴结转移检测的平均测试 AUC 上分别比 MIL/mMIL 高出 14.2%、5.77%和 29.2%,在相同的实验中,比 SL 分别高出 7.32%、16.6%和 29.7%(有关其他分类指标的比较,请参见补充表 9–11)。此外,我们观察到,随着训练集大小的减小,CLAM 模型的平均置信度降低(图 3d–f,底部),这通常比在小训练集上具有不准确但过于自信的模型更为可取,后者会严重并错误地过拟合所观察到的小训练集。
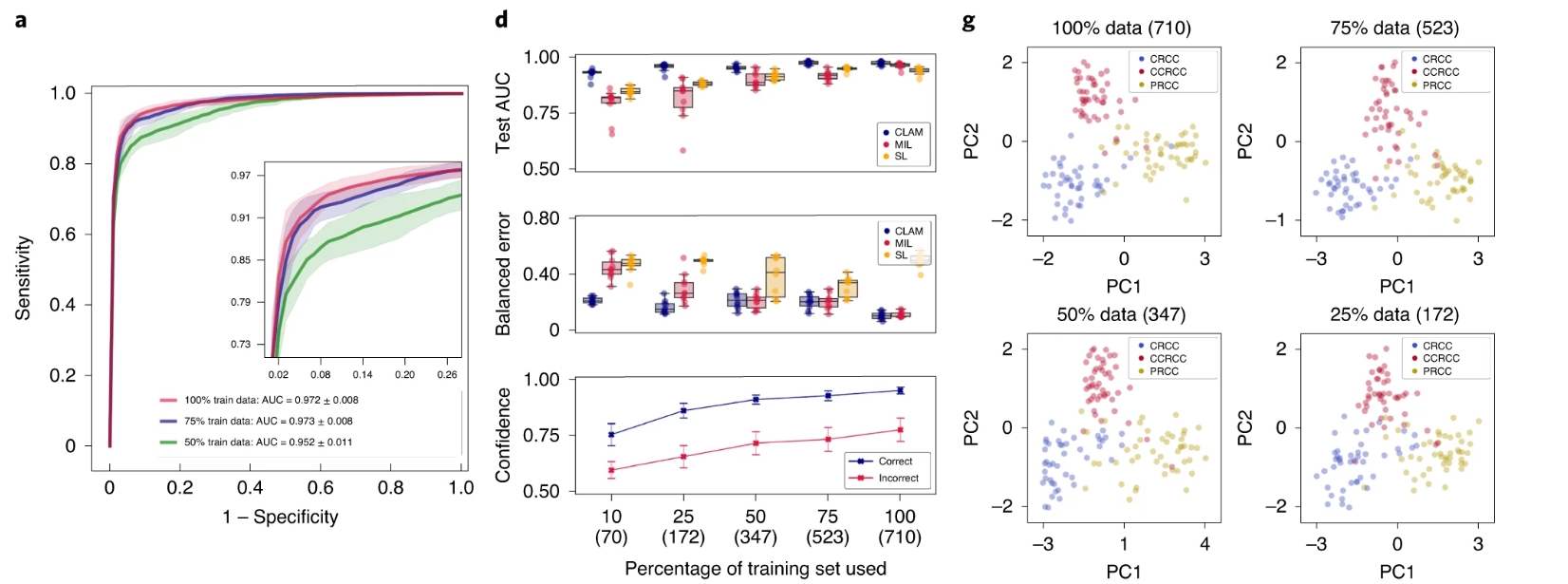
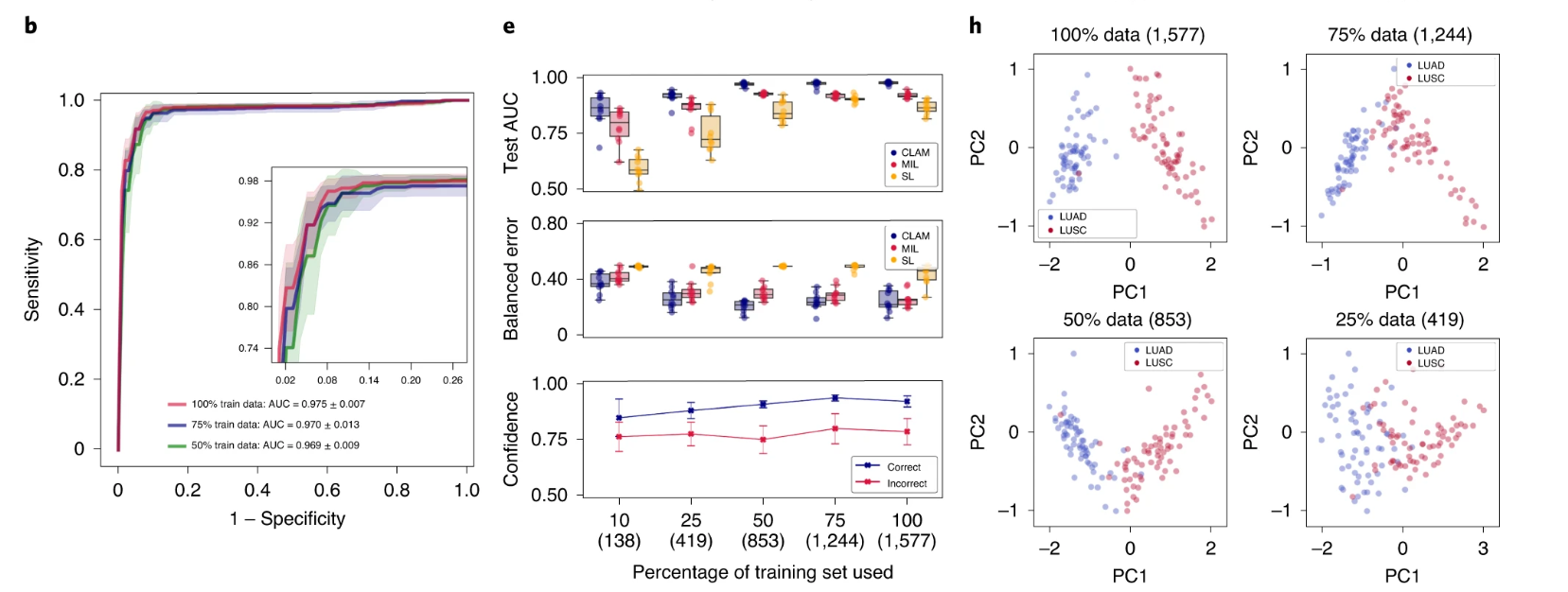
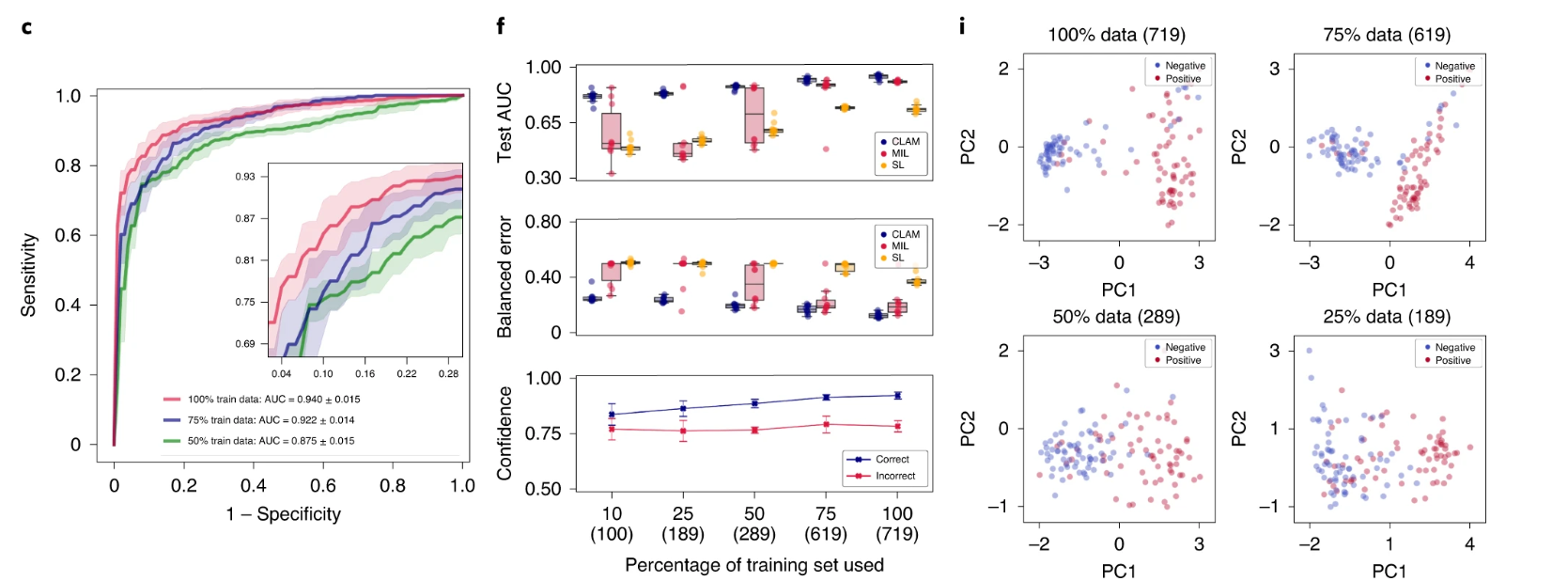
a–i,对于 RCC 亚型分类(a,d,g;n = 86),NSCLC 亚型分类(b,e,h;n = 196)和淋巴结转移检测(c,f,i;n = 89),分析了 CLAM 模型的 10 倍 Monte Carlo 交叉验证预测结果和测试性能。a–c,使用训练集中 100%、75%和 50%的病例的 CLAM 模型的平均测试 AUC ± s.d.。置信带显示平均受试者工作特征曲线的 ±1 s.d。对于多类 RCC 亚型分类,报告了宏平均曲线和 AUC。插图:曲线的放大视图。d–f,以箱线图的形式显示了各种弱监督分类算法的依赖于数据集大小的性能,包括 10 倍交叉验证的测试 AUC(顶部)和平衡误差得分(中部),每个训练集大小(100%,75%,50%,25%和 10%的病例)显示了四分位数值,须延伸到在 1.5 倍四分位距范围内的数据点。CLAM 模型对正确和错误分类幻灯片的预测的均值置信度(± 1 s.d.)(底部)。g–i,CLAM 模型学习到的幻灯片级特征空间的可视化;在进行 PCA 之后,绘制了用于模型预测的最终幻灯片级特征表示,对于单个交叉验证折叠中的验证集和测试集中的每张幻灯片。PC 代表主成分。d–i,显示了每个训练集大小使用的幻灯片数(括号内)。
对于 NSCLC 和 RCC 亚型分类,使用 TCGA 和 CPTAC 的公共数据集训练的模型还必须适应与用于数字化训练数据的 Aperio 扫描仪相比,内部使用的 Hamamatsu 扫描仪产生的每微米像素(m.p.p.)分辨率的差异。虽然大多数来自 TCGA RCC、NSCLC 和 CPTAC NSCLC 的 WSI 的 ×20 等效 m.p.p.接近 0.5,但内部 WSI 的 ×20 等效 m.p.p.为 0.44。在内部 NSCLC 肺数据集上,我们还测试了在测试时通过将图像块降低到大约 0.5 的近似 m.p.p.来标准化分辨率的机制,然后在数据处理过程中由 CNN 编码器嵌入。然而,使用此技术时,我们只观察到平均测试 AUC 略微提高至 0.979 ± 0.005。为了进一步研究不同扫描仪硬件引入的变异性的影响,我们使用额外的 3DHistech MiraxScan 150 扫描仪对所有内部肺切除片进行了数字化,其产生的 m.p.p.为 0.328。尽管 3DHistech 扫描仪的 m.p.p.分辨率与用于数字化公共训练数据的 Aperio 扫描仪存在显著差异,但我们发现我们的模型能够在新扫描仪的本机扫描分辨率上实现平均测试 AUC 为 0.910 ± 0.022。另一方面,通过将 3DHistech 扫描的图像块标准化为 0.5 的 m.p.p.,我们将测试 AUC 提高到 0.965 ± 0.006。这些结果合理地表明,我们提出的弱监督学习框架对扫描仪硬件的变化具有相当强的鲁棒性,但也说明了在评估来自新数据源的幻灯片时,m.p.p.标准化的重要性,特别是在训练数据和测试数据之间的 m.p.p.差异很大时。
总体而言,我们的研究结果非常令人鼓舞,并作为支持证据,使用 CLAM,从多个机构策划的中等规模数据集(具有源特定的变异性)和多样化的患者分布(例如 TCGA)足以开发能够进行泛化的准确的弱监督计算机辅助诊断模型。为了在真实世界的临床部署中获得最佳性能,我们还建议对多个模型的诊断预测进行集成,而不是选择单个模型。这在计算上不昂贵,因为我们只需要对我们的数据进行一次特征提取,而不像其他方法那样需要为每个模型调整特征编码器。在所有独立测试集上,经过训练的 CLAM 模型的集成性能(带有 95%置信区间)见附录图 3 和附录表 12-14。
Interpretability and whole-slide attention visualization¶
经过训练的弱监督深度学习分类器的可解释性可以用于验证模型的预测基础与病理学家使用的众所周知的形态学一致,并且可以用于分析失败案例。此外,整个切片级别的图可以用于人工智能辅助人在环路临床诊断。CLAM 模型通过首先识别和聚合 WSI 中有高诊断重要性(高关注度分数)的区域,同时忽略低诊断相关性(低关注度分数)区域来进行切片级别的预测。为了可视化和解释 WSI 中每个区域的相对重要性,我们以将模型对预测类别的关注度分数转换为百分位,并将标准化的分数映射到原始切片中的相应空间位置。可以使用重叠的图块(例如,95%的重叠)创建细粒度的关注度热图,并对重叠区域中的关注度分数进行平均(有关不同重叠程度的热图的视觉质量的讨论,请参见补充图 4)。尽管在训练过程中从未使用像素级或图块级注释明确告知模型每个区域是否为肿瘤组织(如果是,则是哪种亚型的肿瘤),但我们观察到通过仅使用切片级标签进行弱监督学习,训练的 CLAM 模型通常能够划定肿瘤和正常组织之间的边界(图 4a–c;请参见 http://clam.mahmoodlab.org 的交互式演示以获取高分辨率热图)。对于 RCC 和 NSCLC 亚型分型,这一发现尤为重要,因为 TCGA 收集的所有训练数据都是阳性病例并包含肿瘤区域。这一发现证明了 CLAM 在癌症分型问题中具有潜力,可以用于临床或研究目的的有意义的整个切片级可解释性和可视化,而无需在训练过程中观察负性病例(这将需要收集相邻正常组织的切片或在阳性切片中手动注释负性区域)。同样重要的是,高关注度区域通常与病理学家已经建立和认可的形态学特征相对应,适用于所研究的三个分类任务(图 4a–c)。例如,针对 NSCLC 分型训练的 CLAM 模型突出显示了显著的细胞间桥和角化,并将它们作为鳞状细胞癌(LUSC)的强有力证据(高关注度),与人类病理学专业知识一致(图 4b)。此外,我们还检查了模型在相应细胞角蛋白(AE1/AE3)免疫组织化学染色中的关注度热图,以进一步验证其对淋巴结转移的代表性案例的预测基础(补充图 5)。这些热图还可以用于分析和研究分类错误的切片。我们在自有独立测试数据中观察到具有挑战性的案例,其中模型选择用于预测的高关注度图块未能清晰指示正确的类别,原因是肿瘤细胞分化差或存在有限的上下文线索来描绘肿瘤结构(补充图 6)。对于淋巴结转移的检测,假阳性预测通常突出显示类似肿瘤细胞的大型上皮样组织细胞,而假阴性则往往是由微转移和孤立肿瘤细胞中的小团簇引起的。尽管这些热图在实践中非常有用,但应谨慎过度依赖热图以期望它们可以作为像素级完美的分割掩模;直观上,切片中每个区域的关注度分数是相对的,只是表示模型根据其他区域来确定切片级预测中哪些区域更重要(相对于其他区域)。尽管如此,这种简单而直观的可解释性和可视化技术可以为研究人员提供有关驱动模型预测的形态学模式的见解;经过进一步的定量调查,我们还发现在我们自己的切除切片上评估时,关注度热图与病理学家对肿瘤区域的注释之间存在很高的一致性(补充图 7)。
a、b,对于 RCC(a)和 NSCLC(b)的亚型分型,病理学家标注了每个亚型的代表性切片(左图),大致标出了肿瘤组织区域。c,同样地,对于淋巴结转移的案例,突出显示了转移灶的区域(左图)。a–c,通过计算模型对预测类别的关注度分数,为每个切片生成了整个切片的关注度热图,使用空间重叠率为 25%的图块平铺(第二列);使用 95%重叠生成细粒度的 ROI 热图,突出显示了肿瘤与正常组织之间的边界,并覆盖在原始的 H&E 图像上(第三列;图像左侧黑色方框中区域的放大视图)。最高关注度区域的图块(红色边框)通常展示了众所周知的肿瘤形态学,低关注度区域的图块(蓝色边框)包括不同的背景伪影以及正常组织(右图)。绿色箭头突出显示了与文本描述相对应的特定形态学特征。您可以在我们的交互演示中查看这些切片和热图的高分辨率版本(http://clam.mahmoodlab.org)。
为了增强解释性,我们进一步研究了 CLAM 模型学习到的图块级特征空间。我们从独立测试集的每个切片中随机抽取了一部分图块,使用主成分分析(PCA)将它们的实例级 512 维特征表示降维为两维,并检查网络的聚类层分配的类别预测(附图 8)。对于 RCC 和 NSCLC 切片,不同预测类别的图块在特征空间中被分离成不同的聚类,并展示出各自亚型特有的形态学特征。对于腋窝淋巴结转移的检测,被预测为阳性聚类的抽样图块包括肿瘤组织,而阴性(不可知)图块涵盖了各种形态学特征,包括正常组织和密集的免疫细胞群体。
Adaptability to smartphone microscopy images¶
我们还探索了我们的模型(仅在 WSI 上训练)直接适应使用智能手机相机拍摄的显微镜图像(通常称为光镜照片)的能力。在资源有限、难以获得病理专家知识的地区,会使用附着在传统显微镜上的智能手机拍摄咨询案例 39。针对智能手机显微镜图像专门训练深度学习分类器可能需要耗时且费力的过程,需要手动筛选一大批带标签的感兴趣区域(ROI)。这些 ROI 不仅应该代表潜在的病理情况,还应该捕捉到广泛的组织区域和患者特定的外观和伪影,以确保模型能够适应组织学切片和 WSI 中固有的异质性。因此,能够直接适应手机图像(CPIs)并提供准确的自动诊断的在 WSI 上训练的强大模型对于推广远程病理学具有巨大价值。作为我们模型适应性研究的一部分,在独立测试集中的每个切片中使用消费级 iPhone X 智能手机相机拍摄了 4-8 个视野(FOVs),并使用所有 FOV 的 ROI 图块共同用于模型预测切片级标签。从每个切片中选择了可覆盖诊断所需组织区域的不同数量的 FOVs。CLAM 在 NSCLC CPI 数据集上实现了平均测试 AUC 为 0.873 ± 0.025,在 RCC CPI 数据集上实现了平均的一对其余宏平均 AUC 为 0.921 ± 0.023(图 5b、c 和附表 15、16)。与在 WSIs 上进行测试相比(图 5d),性能下降可能归因于拍摄 CPI 时的不完善条件(对焦不良、光照不均匀、噪声伪影、暗角、色偏、放大倍数变化等)。虽然一些不良因素可能通过传统和基于深度学习的图像处理技术来减少(例如,基于深度卷积对抗生成建模的染色标准化 40),但我们没有尝试纠正或标准化图像,以测试我们的模型的鲁棒性和适应性,并保持处理时间和计算成本的低廉,以便可能直接在智能手机硬件上进行推理。尽管面临这些具有挑战性的变量,我们发现在大多数情况下,模型仍然准确关注 FOV 中展现出每种癌症亚型已知形态学特征的区域(图 5e、f)。此外,不同类别在模型从 WSIs 学到的特征空间中仍然可见地分离为不同的聚类(图 5g、h)。这些结果对于我们的弱监督学习框架在远程病理学领域的潜在广泛适用性提供了信心。
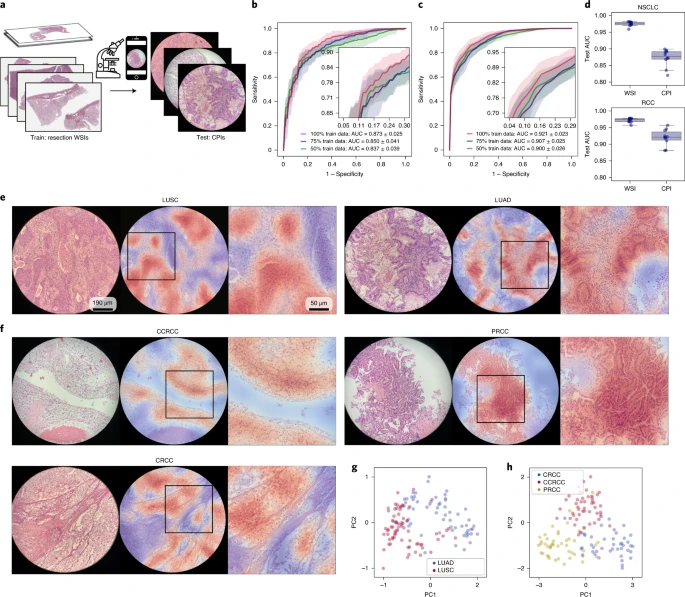
a, 在没有进行领域适应、染色标准化或进一步微调的情况下,WSI 上训练的 CLAM 模型可以适应使用消费级智能手机相机拍摄的 CPIs。 b、c,BWH NSCLC(b; n = 131)和 BWH RCC(c; n = 135)独立测试集的平均测试 AUC 分别为 0.873 ± 0.025 和 0.921 ± 0.023。对于每个 WSI,从所有 FOV 提取的图块被 CLAM 模型集体用于确定切片级诊断。插图:放大的曲线视图。 d,在将从一个成像模态(WSIs)训练的模型直接适应到另一个模态(CPIs)时,性能会下降。我们注意到,当在我们的 CPI 数据集上评估 CLAM 模型(使用 100%的训练集)时,相对于相应的 WSI 独立数据集的性能,NSCLC(顶部)和 RCC(底部)亚型的平均测试 AUC 分别下降了 0.102 和 0.051。箱子表示四分位数,触须延伸到 1.5 倍四分位距内的数据点。 e、f,关注热图(显示了 NSCLC(e)和 RCC(f)亚型)有助于通过突出模型用于进行切片级诊断预测的每个 FOV 中的区域来使模型预测可解释。我们观察到,模型强烈关注肿瘤区域,而几乎忽略正常组织和背景伪影,符合预期。然而,由于每个 FOV 的圆形裁剪,边界附近的图块不可避免地包含不同程度的黑色空间,这可能导致模型对这些区域的关注程度较弱。右侧显示了方框区域的放大视图。 g、h,为了进一步验证在 WSIs 上训练的 CLAM 模型直接适用于 CPIs 的分类,我们可视化了每组 CPIs 的关注汇聚特征表示,并观察到在 NSCLC(g)和 RCC(h)智能手机数据集中存在明显的类别分离。
Adapting networks trained on resections to biopsies¶
我们在研究中使用的公开可用的 WSIs 都是切除标本。与切除组织相比,核心针活检组织通常体积要小得多。有限的组织内容以及由于挤压伪影引起的细胞变形可能会对模型的诊断能力构成挑战。因此,考虑到我们在训练过程中没有使用活检切片,重要的是要调查仅在切除标本上训练的模型是否能够直接适应活检切片并进行准确的诊断预测。我们在 BWH 收集了 110 个肺活检切片(55 个 LUAD 和 55 个 LUSC)和 92 个肾脏活检切片(53 个 CCRCC、26 个 PRCC 和 13 个 CRCC)作为我们的独立测试集,并直接测试了在公开可用的切除数据上训练的模型。每个切片包含多个嵌入的活检标本,肺活检 WSIs 的范围为 1 至 6 个,肾脏活检 WSIs 的范围为 1 至 5 个(附录表 17)。对于每个 WSI,将嵌入在切片中的所有活检标本的组织区域提供给模型作为输入,以便在 WSI 级别上进行单个预测的评估。在肺活检测试集上,CLAM 模型实现了 0.902 ± 0.016 的平均 AUC,在肾脏活检测试集上,平均的宏平均测试 AUC 为 0.951 ± 0.011(图 6b、c 和附录表 18、19)。这些结果非常令人鼓舞,因为许多活检切片,尤其是肺活检数据集,包含了分化差的肿瘤,使得病理学家仅根据溴鸟啶和噻唑染色(不使用免疫组化)难以或无法准确诊断。此外,为了评估我们的模型对潜在的真实世界完全自动化的计算机辅助诊断的适用性,当对活检切片进行测试时,我们没有手动选择包含高肿瘤含量的 ROI,以避免将模型暴露于可能导致错误分类的非肿瘤特征(血管、炎症、坏死区等)35。我们也没有对测试集进行任何预处理技术,如染色标准化,并在评估过程中使用了每个切片的整个组织区域。使用与之前相同的可视化和可解释性技术,我们为每个亚型生成了关注热图(图 6d、e)。尽管肿瘤通常占据的组织区域较小且更稀疏,但我们仍然观察到训练的 CLAM 模型所关注的区域与病理学家标注的肿瘤区域之间存在高度相似性。
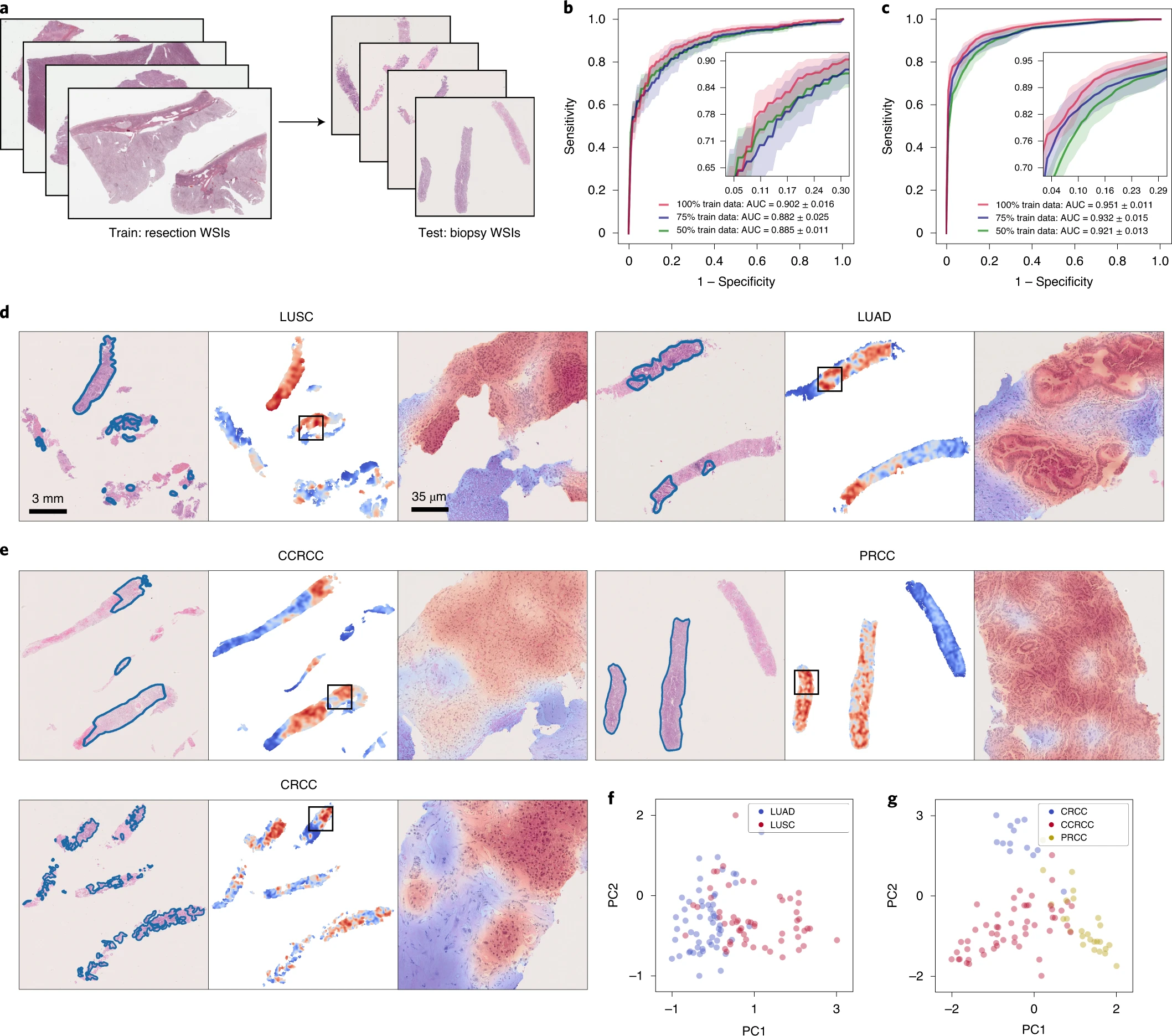
a, 与切除标本 WSIs 相比,活检切片 WSIs 通常包含较少的组织内容(例如,与肺切除数据集中提取的每个切片的组织区域的平均补丁数为 24,714 相比,我们的 BWH 肺活检数据集中提取的平均补丁数为 820)。挤压伪影以及分化差和稀疏分布的肿瘤细胞的存在进一步挑战了准确的诊断。b,c, 我们观察到在切除标本上训练的 CLAM 模型能够直接适应活检切片 WSIs,在我们的 NSCLC(b; n = 110)和 RCC(c; n = 92)活检独立测试集上取得了可观的平均测试 AUC,分别为 0.902 ± 0.016 和 0.951 ± 0.011,无需进一步的微调或 ROI 提取。插图:曲线的放大视图。d,e, NSCLC(d)和 RCC(e)活检切片的关注热图可视化。病理学家注释的肿瘤区域的 H&E 切片(左)。覆盖率为 95%的补丁的热图(中)。CLAM 模型关注的肿瘤区域的放大视图(右)。与我们在切除标本和智能手机数据集上的发现一致,模型最关注的区域始终对应于肿瘤组织。尽管在训练过程中不需要或使用补丁级别或像素级别的注释,关注热图往往清晰地突出显示肿瘤-正常组织的边界。f,g, 使用 PCA 在二维空间中可视化了活检数据集的切片级特征表示。我们观察到,在将 CLAM 模型从切除标本适应到活检切片时,学到的特征空间仍然在 NSCLC(f)和 RCC(g)的不同亚型之间可见地可分离。这些活检切片和热图的高分辨率版本可以在我们的交互式演示中查看(http://clam.mahmoodlab.org)。
Discussion¶
总的来说,我们展示了 CLAM 在计算病理学中解决了几个关键挑战。具体而言,我们的分析表明,CLAM 可以使用仅具有切片级标签且不需要额外注释的方法训练解释性高、性能优良的深度学习模型,用于二元和多类别 WSI 分类。我们非常鼓舞人心地发现,我们的方法克服了耗时的注释障碍,同时更加高效地利用数据;我们展示了它在强大的性能和在独立测试集、智能手机显微镜和不同组织内容上的泛化能力方面的表现,只使用了适量的训练切片。通过 CLAM,我们还能够展示整个 WSI 的高分辨率可解释性热图,这可以作为研究应用中的解释性工具,用于识别与治疗反应和耐药性相关的形态学特征,或作为解剖病理学的二次意见的可视化工具,突出显示 ROI。尽管 CLAM 中的基于注意力的汇聚提供了模型从多个相关 ROI 选择性地聚合信息以提供切片级诊断的灵活性,但 CLAM 和 MIL 方法在弱监督分类中的一个局限性是它们通常将切片中的不同位置视为独立区域,并且不学习实例之间的潜在非线性交互作用,这可能有助于使模型更具上下文感知能力。未来的研究方向之一将专注于将所提出的弱监督框架扩展到计算病理学中的其他问题,并开发更具上下文感知性的方法。此外,虽然通过对特征编码器进行端到端微调和使用广泛的数据增强技术可能会进一步提高性能,但预期通过涉及原始像素数据空间的端到端训练,训练时间和计算资源需求将大幅增加。与这种资源密集型的方法相比,使用低维特征表示可以进行大规模实验,并允许我们对不同弱监督学习算法的数据效率进行详细分析,使用广泛的 10 折交叉验证方法在各种任务中进行评估。然而,这也为未来的方法留下了空间,未来的方法将能够在最大程度上实现端到端训练,以寻求最大限度地发挥模型的表达能力(特别是当有大量多样的数据集可用以避免过拟合),并在对几个吉比像素 WSIs 进行弱监督学习时以高效利用计算资源。最后,未来研究中需要解决和研究的其他挑战包括开发对生存预测具有高效利用数据的弱监督方法、在存在噪声标签、分化差的病例、混合癌亚型和非常有限的标记数据(例如少于十个病例)的情况下进行学习,以及具有不确定性估计的预测和人在环路决策。
弱监督计算病理学更接近临床应用,因为它只需要用于临床目的收集的切片或患者级别标签。我们的方法提高了数据效率,有助于减少弱监督和训练所需的标记整个切片数量之间的权衡。尽管大型多样的数据集对于尽可能捕获数据分布中的异质性非常有价值,但数据高效的整个切片训练对于使计算病理学在分类罕见疾病和临床试验中的患者分层方面具有重要意义,从小型已有患者队列中预测治疗反应或耐药性至关重要。在我们的研究背景下,我们发现 CLAM 确实能够将患者分层为主导和相对罕见的类别(例如 CCRCC 与 CRCC)。随着我们期待在更广泛的问题上验证 CLAM,我们对 CLAM 在切除切片以外的应用潜力也持乐观态度。例如,我们发现使用 CLAM 和弱监督训练的模型对独立数据源、活检切片、不同的扫描设备和智能手机显微镜
图像具有高度的适应性,而无需使用任何形式的领域适应或微调。这些重要特性使得研究人员能够使用切除切片进行模型训练(平均组织覆盖面积:142 mm2,11,182 个补丁),最大程度地增加训练过程中遇到的组织内容的多样性,并具备灵活性,以后可以适应活检切片(平均组织覆盖面积:15.6 mm2,1,225 个补丁)。类似地,经过训练的 CLAM 模型可以适应具有有限视野的 CPIs,并有潜力在资源有限的偏远地区应用远程病理学,其中咨询案例通常通过连接到常规显微镜的消费级智能手机进行成像。总的来说,我们希望我们的研究和方法能够为研究人员提供使用常规组织学标本的整个切片图像解决诊断和研究问题的新方法,从而改善临床护理并促进计算病理学中的知识发现。
Methods¶
CLAM¶
CLAM是一个高吞吐量的深度学习工具,旨在解决计算病理学中的弱监督分类任务,其中训练集中的每个WSI都是一个具有已知幻灯片级别诊断的单个数据点,但对幻灯片中的任何像素或区域都没有类别特定的信息或注释。 CLAM建立在MIL框架的基础上,该框架将每个WSI(称为袋)视为由许多(多达数十万)较小的区域或补丁(称为实例)组成的集合。 MIL框架通常限制其范围,仅针对基于以下假设的正类和负类的二元分类问题,即如果至少有一个补丁属于正类,那么整个幻灯片应该被分类为正类,而如果所有补丁都属于负类,那么幻灯片应该被分类为负类。这一假设体现在刚性的不可训练的最大池聚合函数中,它仅使用具有最高预测概率的正类的补丁进行幻灯片级别的预测,因此MIL不适用于既多类分类问题又不适用于既多类分类问题,也不适用于不能做出固有的正/负假设的二元分类问题。除了最大池之外,尽管还可以使用其他聚合函数,例如均值运算符、广义均值、对数和指数、分位数函数、嘈杂或和嘈杂与\(\mathrm{d}^{41-43} \mathrm{can}\),但它们在问题和数据特定调整方面受到限制,并且不提供用于模型可解释性的简单直观机制。相比之下,CLAM通常适用于多类分类,并围绕可训练和可解释的基于注意力的池化函数\({ }^{37}\)来构建,以从每个类的补丁级表示中聚合幻灯片级表示。在我们的多类注意力池设计中,注意网络预测了与多类分类问题中的\(N\)个类相对应的\(N\)个不同的注意力分数集。这使网络能够明确学习哪些形态特征应被视为正证据(类的特征)与负证据(无信息,不包含类定义特征)的每个类,总结\(N\)个独特的幻灯片级表示。具体来说,对于表示为\(K\)个实例(补丁)的WSI,我们将与第\(k\)个补丁对应的实例级嵌入表示为\(\mathbf{z}_k\)。在CLAM中,第一个完全连接的层\(W_1 \in \mathbb{R}^{512 \times 1,024}\)进一步将每个固定的补丁级表示\(\mathbf{z}_k \in \mathbb{R}^{1,024}\)压缩为一个512维向量\(\mathbf{h}_k=W_1 \mathbf{z}_k\)(为简单起见,所有偏置项都是隐含的,没有明确写出)。注意网络由若干堆叠的完全连接层组成;如果我们将注意网络的前两层\(U_{\mathrm{a}} \in \mathbb{R}^{256 \times 512}\)和\(V_{\mathrm{a}} \in \mathbb{R}^{256 \times 512}\)以及\(W_1\)一起视为所有类共享的注意力骨干的一部分,那么注意网络将分为\(N\)个并行的注意力分支\(W_{\mathrm{a}, 1}, \ldots, W_{\mathrm{a}, \mathrm{N}} \in \mathbb{R}^{1 \times 256}\)。类似地,构建了\(N\)个并行的独立分类器\(\left(W_{c, 1}, \ldots, W_{c, N}\right)\)以评分每个类特定的幻灯片级表示。因此,第\(i\)个类的第\(k\)个补丁的注意力分数,表示为\(a_{l, k}\),由方程(1 \()^{37}\)给出,第\(i\)个类的幻灯片级表示根据方程(2)的注意力分数分布进行汇总,表示为\(\mathbf{h}_{\text {slide, }} \in \mathbb{R}^{512}\),给出如下: $$ \begin{gathered} a_i, k=\frac{\exp \left{W_{\mathrm{a}, i}\left(\tanh \left(V_{\mathrm{a}} \mathbf{h}k\right) \odot \operatorname{sigm}\left(U}} \mathbf{hk\right)\right)\right}}{\sum}^K \exp \left{W_{\mathrm{a}, i}\left(\tanh \left(V_{\mathrm{a}} \mathbf{hj\right) \odot \operatorname{sigm}\left(U}} \mathbf{hj\right)\right)\right}} \ \mathbf{h}_k \end{gathered} $$}, i}=\sum_{k=1}^K a_{i, k} \mathbf{h
相应的未标准化的幻灯片级分数\(s_{\text {slide }, i}\)是通过分类器层\(W_{c, i} \in \mathbb{R}^{1 \times 512}\)给出的,由\(s_{\text {slide }, i}=W_{c, i} \mathbf{h}_{\text {slide }, i}\)。我们在模型的注意力骨干的每一层之后使用dropout(P=0.25)进行正则化。对于推理,通过将softmax函数应用于幻灯片级预测分数\(\mathbf{s}_{\text {slide }}\)来计算每个类的预测概率分布。
实例级别聚类。为了进一步鼓励学习特定于类的特征,我们在训练过程中引入了额外的二元聚类目标。对于\(N\)个类中的每一个,我们在第一层\(W_1\)之后放置一个完全连接的层。如果我们将与第\(i\)个类对应的聚类层的权重表示为\(W_{\text {inst }, i} \in \mathbb{R}^{2 \times 512}\),则对于第\(k\)个补丁,表示为\(\mathbf{p}_{t, k}\)的聚类分配分数给出如下: $$ \mathbf{p}{i, k}=W_k $$ 鉴于我们无法访问补丁级别的标签,我们使用注意网络的输出来生成每次训练迭代中每个幻灯片的伪标签以监督聚类。我们不是对幻灯片中的所有补丁进行聚类,而是仅在最受关注和最不受关注的区域的子集上优化目标。让整个标签集为}, i} \mathbf{h\(\mathcal{Y}=\{1, \ldots, N\}\),为了避免混淆,对于给定的幻灯片,具有地面实况类标签\(Y \in \mathcal{Y}\),我们将与这个地面实况类对应的注意分支(\(W_{\mathrm{a}, Y}\))称为'在类内',其余\(N-1\)个注意分支称为'在类外'。如果我们将在类内注意分数的排序列表(按升序排列)表示为\(\tilde{a}_{Y, 1}, \ldots, \tilde{a}_{Y, K}\),我们将具有最低注意分数的\(B\)个补丁分配为负的聚类标签(\(y_{Y, b}=0, 1 \leq b \leq B\)),而具有最高在类内注意分数的\(B\)个补丁将接收正的聚类标签(\(y_{Y, b}=1, B+1 \leq b \leq 2 B\))。直观地说,因为每个注意分支在训练过程中由幻灯片级标签监督,具有高注意分数的\(B\)个补丁(因此是正的聚类)预计会对类\(Y\)产生强烈的正证据,而低注意分数的\(B\)个补丁(因此是负的聚类)预计会对类\(Y\)产生强烈的负证据。因此,聚类任务可以直观地解释为约束补丁级特征空间\(\mathbf{h}_k\),使得每个类的强特征证据与其负证据线性可分。对于癌症亚型问题,通常假定所有类别是互斥的(即它们不能同时出现在同一幻灯片中),因此我们将在类内注意分支的最受关注和最不受关注的补丁进行聚类,分为正和负证据,对\(\mathrm{N}-1\)个在类外注意分支也进行额外的监督。也就是说,给定地面实况幻灯片标签\(Y\),\(\forall i \in \mathcal{Y} \backslash\{Y\}\),具有最高注意分数的\(B\)个补丁不能成为类\(i\)的正证据,假定幻灯片上没有类\(i\)的补丁(由于互斥性)。因此,除了对从类内注意分支选择的\(2 B\)个补丁进行聚类,我们还将负的聚类标签分配给所有在类外注意分支中具有最高关注分数的\(B\)个补丁,因为它们被假定为虚假的正证据。另一方面,如果互斥性假设不成立(例如,癌症与无癌症问题,其中一张幻灯片可能包含来自肿瘤组织和正常组织的补丁),那么我们不会监督类外分支的高度关注的补丁的聚类,因为我们不知道它们是否是假阳性还是否。使用上述符号,完整的实例级别聚类算法如下概括在算法1中。
WSI datasets¶
详细说明了使用的所有数据集的摘要信息,详见附表 8。对于内部测试数据,我们查询了 BWH 病理档案,并随机从内部病理档案(2016-2019 年)中抽取和请求案例。我们对每个问题请求了 150 个切除病例,并对 NSCLC 和 RCC 亚型鉴定分别请求了 110 个活检病例。我们根据研究时的现场可用性收到了标记覆盖组织区域的幻灯片,并排除了损坏的幻灯片以及不含肿瘤(对于 RCC 和 NSCLC)的幻灯片,然后再在我们的模型上测试性能;没有排除其他幻灯片。关于每个队列的进一步细节将在下面的子部分中给出。对于在公共数据集上使用 10 倍蒙特卡洛交叉验证进行模型开发和评估,我们创建了随机的训练/验证/测试数据集分区,其中来自同一患者病例的幻灯片被一起抽样,以确保例如,同一病例的不同幻灯片不会同时抽样到训练集和测试集。每个患者病例可用的幻灯片数量可能不同,这意味着尽管所有十个折叠在其训练/验证/测试集中始终具有相同数量的病例,但确切的幻灯片数量可能不同。为简洁起见,当我们提到交叉验证折叠的训练集或测试集中的幻灯片数量时,我们指的是所有折叠中幻灯片数量的平均值。
Public RCC WSI dataset¶
我们的公共 RCC 数据集总共包含来自 TCGA RCC 数据库的 884 个诊断 WSI。这些 WSI 属于肾嗜酸细胞瘤(TCGA-KICH)、肾透明细胞癌(TCGA-KIRC)和肾乳头状细胞癌(TCGA-KIRP)项目。其中,有 111 个 CRCC 幻灯片来自 99 个病例,489 个 CCRCC 幻灯片来自 483 个病例,284 个 PRCC 幻灯片来自 264 个病例。在 20 倍放大倍数下,每张幻灯片提取的平均补丁数量为 13,907 个。
Independent BWH RCC WSI dataset¶
我们的内部 RCC 数据集总共包含来自 133 个病例的 135 个 WSI,其中包括 43 个 CRCC 幻灯片、46 个 CCRCC 幻灯片和 46 个 PRCC 幻灯片。在 20 倍放大倍数下,每张幻灯片提取的平均补丁数量为 20,394 个。我们的 RCC 活检数据集总共包含来自 79 个病例的 92 个 WSI,其中包括 13 个 CRCC 幻灯片、53 个 CCRCC 幻灯片和 26 个 PRCC 幻灯片。由于 CRCC 活检病例的可用性受限(仅占所有 RCC 病例的约 5%,只有少数活检病例),因此 CRCC 活检样本的数量较小。在 20 倍放大倍数下,每张幻灯片提取的平均补丁数量为 1,709 个。我们的 RCC 智能手机数据集包括每张幻灯片的 4-8 个视野(FOV)。每个 FOV 的补丁提取数量的平均值为 419 个。所有幻灯片均在 2016 年至 2019 年期间收集和处理于 BWH。
Public NSCLC WSI dataset¶
我们的公开 NSCLC 数据集包括来自 TCGA NSCLC 库的 993 个诊断性 WSI。这些数据集涵盖了 TCGA-LUSC 和 TCGA-LUAD 项目下的肺腺癌(Lung Adenocarcinoma,LUAD)和肺鳞癌(Lung Squamous Cell Carcinoma,LUSC)两种亚型。具体而言,LUAD 数据集包含来自 444 个病例的 507 个幻灯片,LUSC 数据集包含来自 452 个病例的 486 个幻灯片。此外,我们在研究期间还收集了来自 TCIA CPTAC 病理门户的 1526 个具有肺为拓扑位置的 WSI。其中,668 个幻灯片来自 223 个病例,标记为 LUAD;306 个幻灯片来自 108 个病例,标记为 LUSC。剩下的 552 个幻灯片被标记为正常组织并被排除在外。因此,我们的公开肺数据集总共包含 1967 个 WSI(667 个 LUAD 幻灯片来自 560 个病例,792 个 LUSC 幻灯片来自 560 个病例)。每个幻灯片在 ×20 倍镜下提取的平均补丁数量为 9958 个。
Independent BWH NSCLC WSI dataset¶
我们的内部 NSCLC 数据集包括总共 131 个切除(63 个 LUAD 和 68 个 LUSC)和 110 个活检(55 个 LUAD 和 55 个 LUSC)幻灯片。每个幻灯片来自一个独特的病例。每个活检幻灯片和切除幻灯片在 ×20 倍镜下提取的平均补丁数量分别为 820 个和 24,714 个。所有幻灯片均在 2016 年至 2019 年期间在 BWH 收集和处理。我们的肺部智能手机数据集包括每个切除幻灯片的 4-8 个视野。每组视野提取的补丁平均数量为 406 个。此外,肺切除幻灯片使用 3DHistech MiraxScan 150 进行扫描,以研究对不同扫描设备和不同的 m.p.p 的适应性。
Public lymph node WSI dataset¶
CAMELYON16 和 CAMELYON17(参考文献 46)是两个最大的公开可用的、注释的乳腺癌淋巴结转移检测数据集。CAMELYON16 包括 270 个经过注释的整张幻灯片用于训练,另外还有 129 张作为来自荷兰的 Radboud 大学医疗中心和乌得勒支大学医学中心的官方测试集。另一方面,CAMELYON17 包括来自荷兰五个不同医疗中心的共计 1,000 张幻灯片。由于 CAMELYON17 官方测试集中的 500 张幻灯片的幻灯片级别标签尚未公开,因此我们只使用了 CAMELYON17 的训练部分,其中包括来自 100 个病例的 500 张幻灯片(带有相应的幻灯片级别诊断)。我们将 CAMELYON16 和 CAMELYON17 合并为一个数据集,共有 499 个病例的 899 张幻灯片(591 个阴性和 308 个阳性)。每张幻灯片在 ×40 倍镜下提取的平均补丁数量为 41,802 个。
Independent BWH lymph node metastasis (breast cancer) WSI dataset¶
我们内部的乳腺癌淋巴结转移数据集包括来自 131 个病例的 133 个 WSIs(66 张阴性切片和 67 张阳性切片)。每张切片在 ×40 倍放大倍率下平均提取了 51,426 个区块。这些切片是在 2017 年至 2019 年期间收集于 BWH(Brigham and Women's Hospital)。
WSI processing¶
Segmentation¶
对于每个数字化切片,我们的流程从对组织区域的自动分割开始。将 WSI 以降采样的分辨率(例如 32 倍降采样)读入内存,并将其从 RGB 空间转换为 HSV 颜色空间。基于对图像的饱和度通道进行中值模糊后的阈值分割计算二进制掩膜,以识别组织区域(前景),接着进行形态学闭运算以填充小的间隙和空洞。然后,根据面积阈值过滤检测到的前景对象的近似轮廓,并将其存储用于后续处理,同时该切片的分割掩膜可供可选的可视检查。此外,还自动生成一个可读的文本文件,其中包括已处理的文件列表以及包含一组关键分割参数的可编辑字段。尽管默认的参数设置通常足以可靠地进行组织分割,但如果用户对其分割结果不满意,可以轻松地手动编辑任何单个切片的参数。
Patching¶
在分割完成后,对于每个切片,我们的算法会根据用户指定的放大倍率从分割得到的前景轮廓中穷举地裁剪出 256×256 大小的图像块,并使用 hdf5 层次数据格式存储这些图像块以及它们的坐标和切片元数据。根据每个 WSI 的大小和指定的放大倍率,每个切片提取的图像块数量可以从几百个(在 ×20 放大倍率下裁剪的活检切片)到数十万个(在 ×40 放大倍率下裁剪的大切除切片)不等。
Feature extraction¶
在裁剪完成后,我们使用一个深度卷积神经网络(CNN)为每个切片的每个图像块计算一个低维特征表示。具体来说,我们使用在 ImageNet 数据集上预训练的 ResNet50 模型,并在网络的第三个残差块之后使用自适应平均空间池化,使用每个 GPU 上的 128 个图像块进行批处理,将每个 256×256 的图像块转换为一个 1,024 维的特征向量。使用提取的特征作为有监督学习中深度学习模型的输入的好处包括更快的训练时间和更低的计算成本。这使得一旦提取了特征,我们可以在几个小时内在成千上万个 WSI 上训练一个深度学习模型。与使用原始像素相比,使用低维特征还使得将一个切片中的所有图像块(高达 150,000 个或更多)同时适应单个消费级 GPU 的内存中成为可能,从而避免了对图像块进行采样和使用带有噪声的标签的需要。
Visualization¶
Visualizing slide-level feature space¶
针对每个公共 WSI 数据集,我们使用在十个用于交叉验证的训练集之一上训练的模型,为其对应的验证集和测试集中的每个切片计算了一个 512 维的切片级特征表示,用于模型的切片级预测。得到的切片级特征向量集合通过 PCA 变换降维到二维空间,用地面真值切片级标签对每个点进行着色。然后,我们在相同的训练集大小上为训练的模型分别进行了 25%、50%和 75%的相同分析。我们还对每个独立测试组中的切片执行了相同的分析,使用了每个训练集大小的最佳表现模型。
Interpreting model prediction via attention heatmap¶
为了解释模型对切片的不同区域对最终切片级预测的相对重要性,我们计算并保存了从切片中提取的所有图像块的未归一化注意力分数(在应用 softmax 函数之前),使用与模型的预测类对应的注意力分支。这些注意力分数被转换为百分位分数,并缩放到 0 到 1 之间(1 表示最高注意力,0 表示最低注意力)。归一化的分数使用分散的颜色映射转换为 RGB 颜色,并在切片的相应空间位置上显示,以可视化识别和解释高注意力区域(以红色显示,表示对模型预测相对于其他图像块的贡献较高)和低注意力区域(以蓝色显示,表示对模型预测相对于其他图像块的贡献较低)。为了创建更细粒度的热图,我们使用重叠方式将切片或较小的 ROI(例如 8,000×8,000)切割成 256×256 的图像块,并计算每个图像块的原始注意力分数。然后,我们按照上述相似的过程使用相同的颜色映射将 ROI 中每个图像块的原始分数转换为 RGB 颜色。为了确保对于使用重叠的图像块产生的归一化注意力分数与模型用于预测的一组非重叠图像块的分数直接可比较,我们在计算每个图像块的百分位分数时参考整个切片(无重叠)的未归一化注意力分数。ROI 热图以透明度值为 0.5 与原始 WSI 重叠显示,以同时可视化原始 H&E 切片中的底层形态结构。活检和 ROI 热图的重叠率为 95%。为了生成 CPI 的细粒度热图,使用 95%的重叠率,并对每个图像进行注意力分数的归一化处理。
Visualizing patch-level feature space¶
对于独立测试集中的每个切片,我们均匀随机采样其组织图像块的 2%,并记录每个聚类分支的聚类概率预测,以及其第一个完全连接层后的 512 维特征表示。对于亚型问题,如果所有聚类分支对于某个图像块的所有类别都预测的正概率小于 0.5(换句话说,每个类别的聚类分支都认为它们是该类别的负证据),则将其标记为类别不可知;否则,将其标记为概率最高的类别。对于腋窝淋巴结的转移检测,使用对应于正类别的聚类分支将图像块标记为正类(正概率大于或等于 0.5)或类别不可知(正概率小于 0.5)。使用上述可视化切片级特征空间的技术,我们使用 PCA 将每个图像块级的特征向量降维为二维。
Quantitative evaluation of attention heatmaps¶
虽然使用弱监督学习方法训练的 CLAM 模型生成的注意力热图并不旨在对 ROI 进行像素级注释,为了评估在临床或研究环境中使用热图作为辅助注释工具的可能性以及注意力的正确性,我们使用包括 Dice 系数、交集联合比和 Cohen's κ 在内的定量指标评估了单个 CLAM 模型生成的预测注意力热图与病理学家注释之间的一致性。对于每个疾病模型中的所有切除切片,在内部数据集中,我们要求两名解剖病理学家使用注释工具 Automated Slide Analysis Platform (ASAP)独立且详尽地注释所有切片中的肿瘤区域。在注释腋窝淋巴结转移时,使用 AE1/AE3 免疫组织化学染色来辅助注释,并确保不会漏掉小肿瘤区域(微转移)。为了评估,所有热图都是通过以 75%的重叠瓦片化图像块生成的。在动态阈值处理后,根据可能的实际应用场景,人工操作者可以自由调整显示阈值以确定高注意力区域的连续和密集区域,从热图生成二值掩模。每个热图的阈值处理都没有借助病理学家的注释。在二值化之后,我们应用简单的后处理技术,包括形态学闭合和开运算,以减少碎片化、闭合小空洞和抑制小的伪影。对于淋巴结转移,我们没有应用闭合和开运算,因为存在微转移,这可能会形成非常小的像素岛,这些岛屿容易被这样的操作破坏。相反,我们稍微膨胀前景以连接相邻的碎片,并过滤掉所有像素的注意力小于 0.95 的像素岛。最后,尽管我们进行了广泛而细致的工作,但是无法排除所有存在于肿瘤区域内的负像素,因此我们应用组织分割算法来检测组织内的大空洞,并将这些区域排除在热图的评估之外。然而,我们注意到,这不能自动识别所有的空洞区域,特别是如果它们很小,并且也没有考虑到注释肿瘤区域内的小面积正常组织。所有疾病模型的两组病理学家注释结果的总结见补充图 7。
Data availability¶
TCGA 诊断性整切片数据(NSCLC,RCC)及其相应标签可从 NIH 基因组数据共享中心( https://portal.gdc.cancer.gov )获取。CPTAC 诊断性整切片数据(NSCLC)及其相应标签可从 NIH 癌症成像存档( https://cancerimagingarchive.net/datascope/cptac )获取。转移性淋巴结数据可从 CAMELYON16 和 CAMELYON17 网站( https://camelyon17.grand-challenge.org/Data )公开获取。我们在附表 20 中提供了所有公开数据的链接。所有对内部原始和分析数据的合理学术使用请求可以提交给对应的作者。所有请求将迅速审核,以确定请求是否受到任何知识产权或患者保密义务的限制,将根据机构和部门的指导方针进行处理,并需要签署物质转让协议。