Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning(HIPT)¶
摘要¶
视觉 Transformer (ViTs)及其多尺度和层次化变体在捕获图像表示方面取得了成功,但其使用通常针对低分辨率图像(例如 256×256、384×384)进行研究。对于计算病理学中的千亿像素全幅成像(WSI),WSI 在 20 倍放大下的大小可达 150000×150000 像素,并在不同分辨率下展示了视觉 token 的层次结构:从捕获单个细胞的 16×16 图像,到描述组织微环境内相互作用的 4096×4096 图像。我们引入了一种名为层次化图像金字塔 Transformer (HIPT)的新 ViT 架构,它利用 WSI 中固有的自然层次结构,通过两个层次的自监督学习来学习高分辨率图像表示。HIPT 在 33 种癌症类型上进行预训练,使用了 10678 张千亿像素 WSI、408218 张 4096×4096 图像和 104M 张 256×256 图像。我们在 9 个幻灯片级任务上对 HIPT 表示进行基准测试,并展示:
- 1)具有层次预训练的 HIPT 在癌症亚型和生存预测方面超越了当前最先进的方法
- 2)自监督 ViTs 能够模拟有关肿瘤微环境中表型层次结构的重要归纳偏见。
引言¶
组织表型化是计算病理学(CPATH)中的一个基本问题,旨在通过千亿像素全幅切片图像(WSIs)表征用于癌症诊断、预后和估计患者治疗反应的客观、组织病理学特征【39, 41, 54】。与自然图像不同,全幅成像是一个具有挑战性的计算机视觉领域,其中图像分辨率可达 150000×150000 像素,许多方法使用以下基于多实例学习(MIL)的三阶段、弱监督框架:
- 1)在单一放大目标(“缩放”)下的组织 patch ,
- 2)块级特征提取以构建嵌入实例序列,以及
- 3)实例的全局池化,以使用幻灯片级标签(例如 - 亚型、等级、阶段、生存、起源)构建幻灯片级表示【12, 19, 37, 38, 52, 53, 68, 70, 85】。
尽管在许多癌症亚型和分级任务上达到了“临床级”性能,这个三阶段过程有一些重要的设计限制。首先, patch 和特征提取通常固定在【256×256】的上下文区域。尽管能够辨识细粒度的形态特征,如核异型或肿瘤存在,但取决于癌症类型,【256×256】窗口在捕获如肿瘤侵袭、肿瘤大小、淋巴细胞浸润以及这些表型在组织微环境中的更广泛空间组织方面具有有限的上下文,如图 1 所示【6,15,22】。其次,与其他基于图像的序列建模方法(如视觉 Transformer (ViTs))相比,MIL 由于 WSIs 的长序列长度仅使用全局池化操作【38】。因此,这一限制阻碍了应用 Transformer 注意力来学习如肿瘤 - 免疫定位之间的长距离依赖,这在生存预测中是一个重要的预后特征【1, 44, 63】。最后,尽管最近的 MIL 方法采用了自监督学习作为块级特征提取(在 ViT 文献中称为 token 化)的策略,但聚合层中的参数仍需训练【8, 16, 18, 20, 43, 45, 62】。在将 WSIs 的基于块的序列建模与 ViTs 关联时,我们注意到使用 Transformer 注意力的架构设计选择使得 ViT 模型中的 token 化和聚合层的预训练成为可能,这在防止 MIL 模型在低数据情况下过拟合或欠拟合方面很重要【5, 13, 23, 33, 46】。
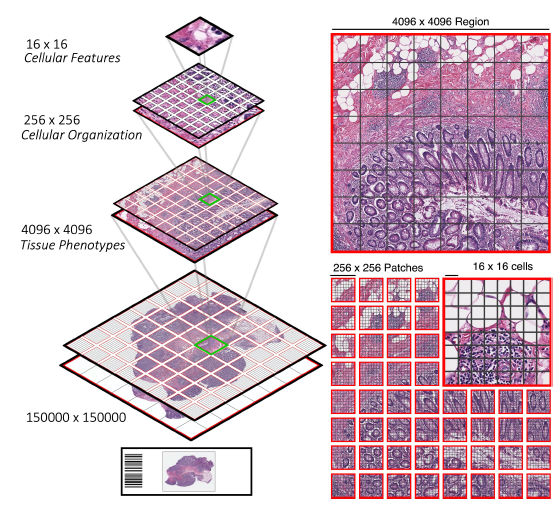
图 1. 全幅切片图像(WSIs)的层次结构。左侧。与自然图像不同,由于 WSIs 具有固定的尺度,不同图像分辨率下存在视觉 token 的层次结构。右侧。除了将单个 256×256 图像表述为 256 个 [16×16] token 的序列外,我们还可以将这些 256×256 图像视为更大的、不相交的 [256×256] token 序列中的一部分,这些 token 位于 4096×4096 区域中。
即 \(H=256,W=256,P=16 \rightarrow N=256\ \text{Token}=\{b,256(N),256(P^{2})\cdot3\}\)
为了解决这些问题,我们探索了在 WSIs 中开发视觉 Transformer 进行幻灯片级表示学习的挑战。与 ViTs 积极探索的自然图像相比,我们注意到在建模 WSIs 时的一个关键区别是,视觉 token 总是在给定放大目标的固定比例上。例如,在 20 倍目标下扫描 WSIs 得到的是每像素大约 0.5μm 的固定比例,允许对视觉元素进行一致比较,这些视觉元素可能阐明重要的组织形态学特征,超出它们正常的参考范围。此外,WSIs 在 20 倍放大下也展现了不同图像分辨率下视觉 token 的层次结构:16×16 图像涵盖细胞及其他细粒度特征(基质、肿瘤细胞、淋巴细胞)的边界框【22, 36】,256×256 图像捕获局部细胞间相互作用(肿瘤细胞性)的局部簇【2, 7, 30, 59】,1024×1024-4096×4096 图像进一步描述了细胞簇及其在组织中的组织(肿瘤浸润性与肿瘤远端淋巴细胞描述中的肿瘤 - 免疫定位范围)的宏观尺度相互作用【1,9】,以及最终在 WSI 的幻灯片级展示中描绘的组织微环境中的整体肿瘤异质性【4,35,39,57,63】。
这项工作测试的假设是,明智地使用这种层次结构在自监督学习中会产生更好的幻灯片级表示。我们介绍了一种基于 Transformer 的架构,用于层次化聚合视觉 token 并在千亿像素病理图像中进行预训练,称为层次化图像金字塔 Transformer (HIPT)。我们以类似于在语言建模中学习长文档表示的方式来处理幻灯片级表示学习任务,我们开发了一个三阶段的层次化架构,该架构从 [16×16] 视觉 token 开始,在它们各自的 256×256 和 4096×4096 窗口中自下而上地聚合,最终形成幻灯片级表示,如图 2 所示【76, 82】。我们的工作以两个重要的方式推动了视觉 Transformer 和自监督学习的边界。通过将 WSIs 建模为一组不相交的嵌套序列,在 HIPT 中:
- 1)我们将学习 WSI 的良好表示分解为层次相关的表示,每个表示都可以通过自监督学习来学习,
- 2)我们使用学生 - 教师知识蒸馏(DINO [13])技术,在最大为 4096×4096 的区域上,通过自监督学习预训练每个聚合层。
我们将 HIPT 应用于学习在 20 倍放大下提取的千亿像素组织病理学图像的表示的任务。我们展示了我们的方法相比传统的多实例学习(MIL)方法取得了更优越的性能。这一差异在如生存预测这样的上下文感知任务中尤为显著,在这些任务中,更大的上下文在表征组织微环境中更广泛的预后特征时更为重要【1, 17, 60, 63】。使用 K- 最近邻在我们模型的 4096×4096 表示上,我们超越了几种弱监督架构在幻灯片级分类上的性能——这在实现自监督幻灯片级表示方面是一个重要的进步。最后,类似于在自然图像上的自监督视觉 Transformer (ViTs)可以执行场景布局的语义分割,我们发现自监督 ViTs 中的多头自注意力学习了组织病理学组织中的视觉概念(从 ViT256-16 的细粒度视觉概念如细胞位置,到 ViT4096-256 的粗粒度视觉概念如更广泛的肿瘤细胞性),如图 3、4 所示。我们在 https://github.com/mahmoodlab/HIPT 提供了代码。
相关工作¶
全幅切片图像(WSIs)中的多实例学习。在一般的基于集合的深度学习中,Edwards & Storkey 和 Zaheer 等人提出了第一个在基于集合的数据结构上操作的网络架构,Brendel 等人展示了“特征包”能够在 ImageNet 上达到高准确率【10,25,80】。与此同时,在病理学中,Ilse 等人将基于集合的网络架构作为组织学兴趣区域中多实例学习的一种方法进行了扩展,Campanella 等人后来将端到端的弱监督扩展到千亿像素 WSIs【12, 38】。Lu 等人展示了通过使用在 ImageNet 上预训练的 ResNet-50 编码器进行实例级特征提取,仅需要训练一个全局池化操作符即可用于弱监督幻灯片级任务【53】。继 Lu 等人之后,已有许多 MIL 的变体适应了如 VAE-GANs、SimCLR 和 MOCO 等图像预训练技术作为实例级特征提取【45,62,84】。最近的 MIL 变体也发展了扩展聚合层和评分函数【17, 64, 68, 75, 77, 78, 85】。
Li 等人提出了一种多尺度 MIL 方法,该方法在 20 倍和 5 倍分辨率下执行 patch 和自监督实例学习,随后进行补丁的空间解析对齐【45】。在 WSIs 中集成放大目标的集成已经在其他工作中被遵循【29,32,56,58】,然而,我们注意到结合跨目标的视觉 token 不会共享相同的尺度。在这项工作中, patch 在单一放大目标下进行,使用更大的块大小来捕获宏观尺度的形态学特征,我们希望这将有助于向重新思考 WSIs 的上下文建模转变。
视觉 Transformer 和图像金字塔:Vaswani 等人的开创性工作不仅在语言建模方面,还在通过视觉 Transformer (ViTs)进行图像表示学习方面带来了显著的发展,在此过程中,256×256 图像被构建为 [16×16] 视觉 token 的图像块序列【23,69,71】。受到多尺度、基于金字塔的图像处理的启发【11,42,61】,ViT 架构开发的最近进展集中在效率和多尺度信息的整合上(例如 - Swin, ViL, TNT, PVT, MViT),以解决视觉 token 的不同尺度/长宽比【27, 31, 51, 72, 81】。与病理学相比,我们强调,如果图像尺度在给定放大倍数下是固定的,那么学习尺度不变性可能不是必需的。与我们的工作相似的是 NesT 和分层 Perciever,它们同样通过 Transformer 块从非重叠图像区域分割然后聚合特征【14, 83】。一个关键的区别是,我们展示了每个阶段的 ViT 块可以分别预训练,用于高分辨率编码(高达 4096×4096)。
方法¶
问题的提出¶
patch size 和视觉标记符号:我们使用以下符号来区分“图像”和对应该图像的“标记”的大小。对于分辨率为 \(L \times L\)(或 \(\mathbf{x}_L\))的图像 \(\mathbf{x}\),我们将从 \(\mathbf{x}_L\) 中非重叠 patch(大小为 \([l \times l]\))提取的视觉标记序列表示为 \(\left\{\mathbf{x}_l^{(i)}\right\}_{i=1}^M \in \mathbb{R}^{M \times d_l}\),其中 \(M\) 是序列长度,\(d\) 是为 \(l\) 大小的标记提取的嵌入维度。在处理 WSI 中的多个图像分辨率(及其相应的标记)时,我们还将 \(\mathbf{x}_L\) 图像内视觉标记(和补丁参数)的形状表示为 \([l \times l]\)(使用方括号)。对于大小为 \(\mathbf{x}_{256}\) 的自然图像,ViTs 通常使用 \(l=L^{1 / 2}=16\),这导致序列长度为 \(M=256\)。另外,我们表示在 \(L\) 大小图像分辨率上工作,使用 \([l \times l]\) 分割方法的 ViT 为 \(\mathrm{ViT}_L-l\)。对于 \(\mathbf{x}_{\mathrm{WSI}}\)(指的是 WSI 的幻灯片级分辨率),MIL 方法选择 \(l=256\),这适合可以预训练并用于标记化的 CNN 编码器的输入形状,导致 \(M>10,000\)(因分割组织内容的总面积而变化)。
幻灯片级弱监督:对于带有结果 \(y\) 的 WSI \(\mathrm{x}_{\text {WSI }}\),目标是解决幻灯片级分类任务 \(P\left(y \mid \mathbf{x}_{\mathrm{WSI}}\right)\)。解决此任务的传统方法使用三阶段 MIL 框架,该框架执行:
- 1)\([256 \times 256]\) 补丁
- 2)标记化
- 3)全局注意力池化。
\(\mathbf{x}_{\text {WSI }}\) 被构造为序列 \(\left\{\mathbf{x}_{256}^{(i)}\right\}_{i=1}^M \in \mathbb{R}^{M \times 1024}\),这是使用在 ImageNet 上预训练的 ResNet50 编码器(在第三个残差块后截断)的结果。由于 \(l=256\) 的大序列长度,这项任务中的神经网络架构限于每个补丁和全局池化操作符,以提取用于下游任务的幻灯片级嵌入。
就是说只有两层,分别是 256 像素级别的,训练时会被分割成 16 × 16,以及 4096 像素级别的,训练时会被分割为 256 × 256
层次化图像金字塔 Transformer (HIPT)架构¶
在将 ViTs 适应于幻灯片级别的表示学习时,我们重申两个与自然图像中的计算机视觉截然不同的重要挑战:
- 1)Token 的固定尺度及其在图像分辨率中的层次关系;
- 2)展开的 WSIs 的大序列长度。
如前所述,在组织病理学中,视觉标记通常以物体为中心(并且在图像分辨率中的细粒度变化),并且还具有重要的上下文依赖性,例如肿瘤 - 免疫(推断良好的预后)或肿瘤 - 基质相互作用(推断侵袭)。如果对像 WSI 这样的极高分辨率目标进行较小像素尺度的 patch 化(例如 \(\mathbf{x}_{256}\) 在 \(20 \times\)),那么不可避免的会产生非常大的序列长度,这同时会使得自注意力变得难以进行;而对分辨率不高的对象使用较大像素尺度的 patch 化则会导致细粒度形态结构的细节丢失(例如 \(\mathbf{x}_{256}\) 在 \(5 \times\)),这使得我们仍然需要在 \(20 \times\) 放大倍数下进行分辨率大小为 \([256 \times 256]\) 的 patch 化处理。
为了捕捉这种层次结构和可能存在于每个图像分辨率的重要依赖性,我们将 WSIs 视为类似于长文档的嵌套 Visual Token 聚合,这些标记递归分解为更小的标记,直到细胞级别(图 2),写作:
其中 256 是 \(\mathbf{x}_{256}\) 和 \(\mathbf{x}_{4096}\) 图像中 \([16 \times 16]\) 和 \([256 \times 256]\) 补丁的序列长度,\(M\) 是 \(\mathbf{X}_{\text {WSI }}\) 中 \(\mathbf{x}_{4096}\) 图像的总数。为了简化符号,我们将 \(\mathbf{x}_{16}\) 图像称为细胞级别,\(\mathbf{x}_{256}\) 图像称为补丁级别,\(\mathbf{x}_{4096}\) 图像称为区域级别,整个 WSI 为幻灯片级别。在选择这些图像大小时, token 的输入序列长度在 \(\mathrm{ViT}_{256}-16\) 和 \(\mathrm{ViT}_{4096}-256\)(细胞和补丁级别聚合)的前向传递中总是 \(M=256\),并且通常在 \(\operatorname{ViT_{WSI}}-4096\)(幻灯片级别聚合)的前向传递中,序列长度 \(M<256\)。从 \(\mathrm{ViT}_{256}-16\)(模型的输出)中的 [CLS] 标记被用作 \(\mathrm{ViT}_{4096}-256\) 的输入序列,随后 \(\mathrm{ViT}_{4096}-256\) 中的 [CLS] 标记被用作 \(\mathrm{ViT}_{\mathrm{WSI}}-4096\) 的输入序列,每个阶段的总视觉标记数量按 256 的因子几何级数减少。通过为每个阶段选择 ViT-S backbone,HIPT 的参数少于 \(10M\),易于在商用工作站上实现和训练。我们在下面描述每个阶段。
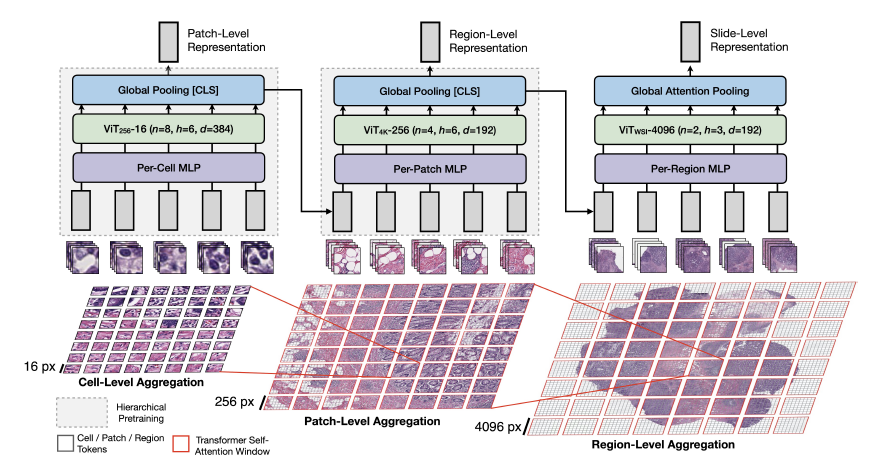
图 2. HIPT 架构。受到在自然语言处理中使用层次化表示的启发,其中嵌入可以在字符级、词级、句子级和段落级聚合形成文档表示,我们在 x16 细胞级、x256 补丁级、x4096 区域级聚合 Visual Token 以形成幻灯片表示。为了还能在每个阶段模拟视觉概念之间的重要依赖性,我们将 Transformer 自注意力作为一种排列等变的聚合层进行适配。注意,由于使用 x256 标记对 x4096 区域进行补丁处理的复杂性与使用 x16 标记对 x256 图像进行补丁处理的复杂性相同,我们可以使用适用于低分辨率图像的类似自监督 ViT 技术预训练高分辨率图像的聚合层。
\(\mathrm{ViT}_{256}-16\) 用于细胞级别聚合。在 \(\mathrm{x}_{256}\) 窗口内计算 \(\mathrm{x}_{16}\) 细胞级别标记聚合遵循了在自然图像中实现的标准 ViT[23]。给定一个 \(\mathrm{x}_{256}\) 补丁,ViT 将这个图像展开为一系列非重叠的 \([16 \times 16]\) 标记,随后通过一个 MLP (线性层,用来将输入的 patch 序列从 \(P^{2}\cdot C\) 变成 384)以及添加的 PE 来产生一组 384 维嵌入 \(\left\{\mathbf{x}_{16}^{(i)}\right\}_{i=1}^{256} \in \mathbb{R}^{256 \times 384}\),并添加了一个可学习的 [CLS] 标记来聚合序列中的细胞嵌入。在这个设置中,我们选择 \(l=16\),不仅是为了遵循传统的 ViT 架构,还因为在这个分辨率下,一个 \([16 \times 16]\) 的边界框在 \(20 \times \approx 8 \mu m^2\) 面积内编码了以单个细胞为中心的视觉概念(例如:细胞身份、形状、圆度)。
\(\mathrm{ViT}_{4096}-256\) 用于补丁级别聚合。为了表示 \(\mathrm{X}_{4096}\) 区域,尽管图像分辨率比传统自然图像大得多,但 token 数量保持不变,因为补丁大小随图像分辨率而缩放。从前一个阶段,我们使用 \(\mathrm{ViT}_{256}-16\) 对每个 \(\mathrm{x}_{4096}\) 区域内的非重叠 \(\mathrm{x}_{256}\) 补丁进行标记化,形成序列 \(\left\{[\mathrm{CLS}]_{256}^{(j)}\right\}_{j=1}^{256}\),可以插入到 ViT 块中以模拟更大的图像上下文。我们使用 \(\mathrm{ViT}_{4096}-256(\mathrm{n}=4, \mathrm{~h}=3, \mathrm{~d}=192)\),输出 \([\mathrm{CLS}]_{4096}\)。
ViT \(_{\text {WSI-4096 }}\) 用于区域级别聚合。在计算 \(\mathbf{x}_{\text {WSI }}\) 的幻灯片级表示时,我们使用 \(\mathrm{ViT}_{\mathrm{WSI}}-4096(\mathrm{n}=2, \mathrm{~h}=3, \mathrm{~d}=192)\) 来聚合 \([\mathrm{CLS}]_{4096}\) 标记。\(M\) 的范围从 \(1-256\),取决于 WSI 的大小。由于在 [4096×4096] 的补丁过程中可能出现的组织分割不规则性,我们在这个阶段忽略位置嵌入。
层次预训练¶
在仅使用 Transformer 块构建 MIL 框架时,我们还探索并提出了一个称为幻灯片级自监督学习的新挑战——旨在提取千兆像素图像中的幻灯片级特征表示,用于下游的诊断和预后任务。这是一个重要问题,因为目前在 CPATH 中的幻灯片级训练数据集通常有 100 到 10,000 个数据点,这可能会导致 MIL 方法因过度参数化和标签缺乏而过拟合。 为了解决这个问题,我们假设 HIPT 的递归性质可以使得常规的 ViT 预训练技术(如 DINO[13])在高分辨率图像的阶段(相似的子问题)中仍然具有泛化能力。为了预训练 HIPT,首先,我们利用 DINO 来预训练 \(\mathrm{ViT}_{256}-16\)。然后,保持 \(\mathrm{ViT}_{256}-16\) 的权重不变,我们在 DINO 的第二阶段中重用 \(\mathrm{ViT}_{256}-16\) 作为 \(\mathrm{ViT}_{4096}-256\) 的 embedding layer。我们将这个过程称为层次预训练,这在学习深度信念网络 [26] 和长文档的层次化 transformers[82] 的上下文中以类似方式进行。虽然层次预训练没有达到幻灯片级别,但我们展示了:1) 在自监督评估中预训练的 \(\mathbf{x}_{4096}\) 表示与幻灯片级亚型的监督方法具有竞争力,以及 2) HIPT 通过两阶段层次预训练可以达到最先进的性能。
第一阶段:\(256 \times 256\) 补丁级预训练。为了预训练 \(\mathrm{ViT}_{256}-16\),我们使用 DINO 框架对 \(\mathrm{x}_{256}\) 的 patches (即 16 × 16 分辨率的 patch)进行预训练,其中学生网络 \(\phi_{s_{256}}\) 被训练以匹配具有动量编码的双胞胎教师网络 \(\phi_{t_{256}}\) 的概率分布,使用交叉熵损失 \(-p_{t_{256}}(\cdot) \log p_{s_{256}}(\cdot)\),其中 \(p_{t_{256}}, p_{g_{256}}\) 分别表示 \(\phi_{t_{256}}(\cdot), \phi_{g_{256}}(\cdot)\) 的输出,对于 \(\mathrm{x}_{256}\)。作为每个 \(\mathrm{x}_{256}\) 补丁的数据增强,DINO 构建了一组 \(M_l=8\) 个局部视图(\(\mathrm{x}_{96}\) 裁剪,通过 \(\phi_{g_{256}}\) 传递)和 \(M_g=2\) 个全局视图(\(\mathrm{x}_{224}\) 裁剪,通过 \(\phi_{t_{256}}\) 传递),以鼓励学生和教师之间的局部到全局对应,最小化函数:
这种数据增强方法适用于组织学数据的原因同样是由于细胞在组织补丁中的自然而然的“部分 - 整体”层次结构。与自然图像中 \([96 \times 96]\) 裁剪可能只捕捉颜色和纹理而没有任何语义信息相比,在 \(20 \times\) 下,局部 \([96 \times 96]\) 裁剪将捕获多个细胞及其周围细胞外基质的上下文,这与更广泛的细胞社区共享相互信息。与原始 DINO 实现类似,我们对所有视图使用水平翻转和颜色抖动,其中一个全局视图执行了日晒效果。
第二阶段:\(4096 \times 4096\) 区域级预训练。由于 \(\mathrm{X}_{4096}\) 区域的序列长度和计算复杂性与 \(\mathrm{x}_{256}\) 补丁相似,我们也可以借用几乎相同的 DINO 配方同时预训练 \(\mathrm{ViT}_{4096}-256\) 并在此阶段定义学生 - 教师网络 \(\phi_{s_{4096}}(\cdot), \phi_{t_{4096}}(\cdot)\)。在提取 \(\mathrm{ViT}_{256}-16\) 的 \([\mathrm{CLS}]_{256}\) 标记作为 \(\mathrm{ViT}_{4096}-256\) 输入后,我们将 \(\left\{[\mathrm{CLS}]_{256}^{(j)}\right\}_{j=1}^{M=256}\) 重新排列为 \(16 \times 16 \times 384\) 的 2D 特征网格,用于数据增强,执行 \([6 \times 6],[14 \times 14]\) 的局部 - 全局裁剪,以匹配 \(256 \times 256\) 输入的 \([96 \times 96],[224 \times 224]\) 裁剪的规模。作为额外的数据增强,我们根据 Gao 等人 [28] 的工作,在所有视图后应用标准的 dropout(\(p=0.10\))。