Modeling Dense Multimodal Interactions Between Biological Pathways and Histology for Survival Prediction
摘要¶
整合全幅切片图像(WSIs)和整体转录组学以预测患者生存情况,可以增进我们对患者预后的理解。然而,这一多模态任务因数据性质不同而尤为具有挑战性:全幅切片图像为肿瘤提供了一种非常高维的空间描述,而整体转录组学则描述了该肿瘤内的全局基因表达水平。在这一背景下,我们的工作旨在解决两个关键挑战:
- (1)我们如何以一种语义上有意义且可解释的方式对转录组学数据进行标记化处理?及
- (2)我们如何捕捉这两种模态之间的密集多模态交互?
在此,我们提出从转录组学中学习生物途径标记,这些标记能够编码特定的细胞功能。结合编码切片形态的组织学 patches 标记,我们认为这些标记构成了适合解释性分析的基本单元。我们使用一种内存高效的多模态 Transformer 融合这两种模态,该 Transformer 能够模拟生物途径与组织学 patches 标记之间的互动。我们的模型 SurvPath 在五个来自癌症基因组图谱的数据集上的评估中达到了最新的水平,并且与单模态和多模态 baseline 相比,显示出卓越的性能。我们的解释框架确定了关键的多模态预后因素,并因此可以提供有关基因型与表型相互作用的宝贵见解。代码可在以下网址获取:https://github.com/mahmoodlab/SurvPath。
1 Introduction¶

图 1:SurvPath 的多模态可解释性。SurvPath 通过 Transformer 的交叉注意机制,实现了生物途径和形态模式之间多模态交互的可视化,这里以高风险乳腺癌为例。弦的厚度表示注意力权重。
预测患者预后是计算病理学(CPATH)的一个基本任务,旨在利用组织学全幅切片图像(WSIs)进行自动化风险评估、患者分层和治疗反应预测。患者的预后通常被视为一项生存任务,其目标是学习能正确排序原始诊断全幅切片生存时间的风险估计。由于全幅切片图像可能达到 100,000 x 100,000 像素,因此常用弱监督方法如多示例学习(MIL)进行生存预测。在 MIL 中,全幅切片图像被标记化为小块,从中提取特征并输入到汇聚网络(如注意力网络)进行下游分类。
虽然组织学提供了有关细胞类型及其在组织中的组织方式的表型信息,但其他模态可以提供可能独立与预后相关的互补信号。例如,整体转录组学代表组织中的平均基因表达,可以揭示更丰富的全局细胞类型和细胞状态,并已被证实是患者生存的强预测因子。通过结合这两种模态,我们可以将整体转录组学提供的全局信息与全幅切片图像的空间信息整合起来。虽然大多数现有方法采用后期融合机制(即,融合模态级表示),但我们设计了一种早期融合方法,可以明确模拟局部形态模式和转录组学之间的精细交叉模态关系。与广泛使用的视觉 - 语言模型相比,转录组学和组织学的多模态融合呈现出两个关键技术挑战:
- 转录组学模态的标记化:基于图像和文本的模态可以明确地标记化为对象区域和词汇标记,然而,以语义上有意义且可解释的方式标记化转录组学是具有挑战性的。由于转录组学数据已自然呈现为特征向量,许多先前研究忽略了标记化,并直接将整个特征与其他模态连接,这限制了多模态学习仅至后期融合操作。另一种方法是,可以将基因划分为代表不同基因家族的粗糙功能集(例如,肿瘤抑制基因和致癌基因),并将其用作标记。然而,这种集合提供的细胞内互动的描述是粗糙且不完整的,因为一个基因家族可以涉及不同的细胞功能。因此,它们可能缺乏与精细形态的语义对应。相反,我们提议根据已建立的生物途径对基因进行标记。途径是具有已知相互作用的基因集,与特定的细胞功能相关,例如 TGF-β 信号级联,它有助于乳腺癌中的上皮 - 间充质转化。与粗糙集相比(例如,我们工作中的 \(N_{\mathcal{P}}=331\)),基于途径的基因分组可以产生代表独特分子过程的数百到数千个标记,我们假设这些标记是与组织学多模态融合更合适的表示。此外,由于途径代表独特的细胞功能,它们构成了适合解释性的基本推理单元(见图 1)。
- 捕获密集多模态交互:利用 Transformer 通过自注意机制捕获所有标记之间的成对相似性,可以实现组织学和途径标记的早期融合。然而,模拟大量组织学 patches 标记(例如 \(\left.N_{\mathscr{H}}=15,000\right)\) 和途径标记 \(\left(N_{\mathcal{P}}=331\right)\) 之间的成对互动带来了可扩展性挑战。由于 Transformer 注意力的二次复杂性,模拟所有可能的互动需要大量的计算和内存资源。为解决这一问题,我们引入了一种新的统一的、内存高效的注意力机制,能够模拟 patches 到途径、途径到 patches 以及途径之间的互动。通过以下方式实现这三种互动的建模:(1)设计查询、键和值以跨标记类型共享参数,并(2)简化注意力层以忽略 patches 之间的互动,我们通过实验发现这对生存分析的效果不太有效。
总结来说,我们的贡献包括:
- (1)一个转录组学标记器,利用细胞生物学现有知识生成生物途径标记;
- (2)SURVPATH,一种内存高效且不依赖分辨率的多模态 Transformer 公式,集成转录组学和 patches 标记预测患者生存;
- (3)一个多级可解释性框架,使得派生单模态和跨模态的预测洞见成为可能;
- (4)一系列实验和消融研究显示了 SURVPATH 的预测能力,使用了来自癌症基因组图谱计划(TCGA)的五个数据集,并与单模态和多模态融合方法进行了基准测试。

图 2:SurvPath 的框图。(1) 我们将转录组学数据标记化为语义上有意义、可解释且可端到端学习的生物途径标记。(2) 我们进一步使用 SSL 预训练的特征提取器将相应的组织学全幅切片图像标记化为 patches 标记。(3) 我们使用一种内存高效的多模态 Transformer 将途径标记和 patches 标记结合起来,用于生存结果预测。
相关工作¶
2.1 组织学全幅切片图像的生存分析¶
最近,已提出了几种基于组织学的生存模型【92, 88, 82, 63, 66】。大部分贡献致力于使用多实例学习(MIL)来模拟肿瘤异质性和肿瘤微环境。为此,提出了几种 MIL 池化策略,如使用图神经网络来模拟局部 patches 交互【49, 16, 38】,计算 patches 嵌入之间的差异【60】,或采用多放大倍数 patches 表示【44】。
2.2 多模态 Transformer 与可解释性¶
同时,Transformer 用于多模态融合在分类和生成任务中得到了显著关注【70, 86, 61】。多模态标记可以被串联并输入到常规 Transformer【72, 18】、层次 Transformer【43】或交叉注意 Transformer【55, 46, 52】。随着模态的数量和维度增加,典型的序列长度可能变得过大,无法输入到普通 Transformer 中,因此需要低复杂性方法。已有多种模型提出了自注意力的重新表述,以减少内存和计算需求【4, 85, 31, 12, 83, 29, 15, 14】,例如,通过使用低秩分解【47, 85】来近似自注意力,使用潜在瓶颈蒸馏【31, 53, 32】,优化 GPU 读/写【15, 14】或使用稀疏注意模式【4, 56】。最近,可解释的多模态模型或事后解释方法【41, 75, 1】也已成为研究的关键领域,尤其是在医疗保健和人机交互等敏感的人工智能协作决策场景中。
2.3 多模态生存分析¶
多模态整合是癌症预后的一个重要目标【64】,因为结合组织学和如基因组学或转录组学的组学数据是许多癌症类型的当前临床实践。这些工作的大多数采用后期融合机制【71, 9】,并且在模态融合的操作方式上存在差异。融合可以基于向量串联【51】、模态级对齐【7】、双线性池化(即克罗内克积)【9, 80】或分解双线性池化【39, 57】。
与此不同,可以使用早期融合机制,其中模拟输入各成分之间的交叉模态互动【10, 91, 17, 87】。我们的工作是在 MCAT【10】的基础上进行的,MCAT 使用交叉注意模块来模拟组织学 patches(键、值)对基因集(查询)的注意力。然而,MCAT 存在几个局限性:(1)交叉注意是单向的,只模拟 patches 到基因的互动,(2)使用粗糙的集合进行转录组学标记化,这并不反映实际的分子过程,(3)集合之间的基因重叠显著,导致冗余的交叉注意热图。
3 方法¶
在这里,我们介绍 SurvPath,这是我们提出的基于组织学和转录组学的多模态生存预测方法。第 3.1 节介绍用于构建生物途径标记的转录组学编码器,第 3.2 节介绍用于构建 patches 标记的组织学编码器,第 3.3 节介绍我们基于 Transformer 的多模态聚合,第 3.4 节介绍其在生存预测中的应用(见图 2)。最后,第 3.5 节介绍我们的多层次可解释性框架。
3.1 从转录组学到途径标记器¶
构成途径:选择适当的推理单元用于转录组学分析是具有挑战性的,这归因于细胞过程的复杂和层级性质。途径由一组基因或子途径组成,这些基因或子途径参与特定的生物过程,代表了这一分析的自然推理单元。可以将这与动作识别进行比较,在动作识别中,一个动作(即生物途径)可以通过一系列由传感器捕获的动作(即一组基因的转录组学测量)来描述。
3 方法¶
在此,我们介绍 SurvPath,这是我们提出的基于组织学和转录组学的多模态生存预测方法。第 3.1 节展示了如何构建生物途径标记的转录组学编码器,第 3.2 节展示了如何构建 patches 标记的组织学编码器,第 3.3 节展示了我们基于 Transformer 的多模态聚合,第 3.4 节展示了其在生存预测中的应用(参见图 2)。最后,第 3.5 节介绍了我们的多层次可解释性框架。
给定一组 \(N_{\mathcal{G}}\) 基因的转录组学测量值,记为 \(\mathbf{g} \in{\mathbb{R} }^{N_{\mathcal{G}}}\),以及每个途径的组成,我们的目标是构建途径级标记 \(\mathbf{X}^{(\mathcal{P})} \in{\mathbb{R}}^{N_{\mathcal{P}} \times d}\),其中 \(d\) 表示标记的维度。转录组学可以视为表格数据,可以通过多层感知器(MLPs)有效编码。具体来说,我们正在学习特定途径的权重 \(\phi_i\),即 \(\mathbf{x}_i^{(\mathcal{P})}=\phi_i\left(\mathbf{g}_{\mathcal{P}_i}\right)\),其中 \(\mathbf{g}_{\mathcal{P}_i}\) 是途径 \(\mathcal{P}_i\) 中存在的基因集。这可以视为学习一个稀疏多层感知器(S-MLP),将转录组学 \(\mathbf{g} \in{\mathbb{R}}^{N_{\mathcal{G}}}\) 映射到标记 \(\mathbf{x}^{(\mathcal{P})} \in{\mathbb{R}}^{N_{\mathcal{P}} d}\)。网络的稀疏性由嵌入在 S-MLP 权重中的基因到途径的连接性控制。通过简单地将 \(\mathbf{x}^{(\mathcal{P})} \in{ \mathbb{R}}^{N_{\mathcal{P}} d}\) 重塑为 \(\mathbf{X}^{(\mathcal{P})} \in{\mathbb{R} }^{N_{\mathcal{P}} \times d}\),我们定义了 Transformer 可以使用的途径标记。每个途径标记对应于构成其的基因级转录组学的深层表示,这既(1)可解释,因为它编码了特定的生物功能;也(2)可在端到端的预测任务中学习。
3.2 从全幅切片图像到组织学 patches 标记器¶
给定输入的全幅切片图像(WSI),我们的目标是衍生出定义 patches 标记的低维 patches 级嵌入。我们首先识别组织区域,以确保被忽略的背景不携带生物意义。然后,我们将识别的组织区域分解为一组 \(N_{\mathscr{H}}\) 非重叠 patches,放大倍数为 20 倍(或分辨率约为 0.5 微米/像素),记为 \(\mathbf{H}=\left\{\mathbf{h}_1, \ldots, \mathbf{h}_{N_{\mathfrak{H}}}\right\}\)。由于每个 WSI 的 patches 数量可能非常大(例如,可能超过 50,000 个 patches 或 78GB 的浮点数),因此需要在模型训练前提取 patches 嵌入,以减少总体内存需求。正式地,我们使用预训练的特征提取器 \(f(\cdot)\) 将每个 patches \(\mathbf{h}_i\) 映射到 patches 嵌入 \(\mathbf{x}_i^{(\mathscr{H})}=f\left(\mathbf{h}_i\right)\)。在本工作中,我们使用了一个通过对超过 1500 万个泛癌症病理学 patches 的对比学习预训练的 Swin Transformer 编码器。所得的 patches 嵌入代表了 patches 的压缩表达(压缩比为 256),我们进一步通过一个可学习的线性变换将其传递,以匹配标记维度 \(d\),从而生成 patches 标记 \(\mathbf{X}^{(\mathscr{H})} \in{\mathbb{R}}^{N_{\mathscr{H}} \times d}\)。
3.3 多模态融合¶
我们的目标是设计一种早期融合机制,以模拟途径和 patches 标记之间的密集多模态交互。我们使用 Transformer 注意力 [72] 来测量和聚合多模态标记之间的成对交互。具体来说,我们通过连接途径和 patches 标记来定义一个多模态序列,产生 \(\left(N_{\mathscr{H}}+N_{\mathcal{P}}\right)\) 维度为 \(d\) 的标记,记为 \(\mathbf{X} \in\left(N_{\mathcal{P}}+N_{\mathscr{H}}\right) \times d\)。遵循自我注意术语 [72],我们定义三个线性投影使用可学习矩阵来提取查询 \((\mathbf{Q})\)、键 \((\mathbf{K})\) 和值 \((\mathbf{V})\) 及自注意力 \(\mathbf{A}\),设置 \(d=d_k=d_q=d_v\)。然后定义 Transformer 注意力为:
其中,\(\sigma\) 是按行的 softmax。项 \(\mathbf{QK}^T\) 的内存需求为 \(\mathcal{O}\left(\left(N_{\mathcal{H}}+N_{\mathcal{P}}\right)^2\right)\),对于长序列来说,计算成本会变得很高。这构成了一个主要瓶颈,因为一个全扫描图像(WSI)可能有超过50,000个补丁,这使得在大多数硬件上进行这种计算变得具有挑战性。相反,我们提议将多模态 Transformer 注意力分解为四个内部和跨模态项:(1)内模态路径自注意力编码路径到路径的相互作用 \(\mathbf{A}_{\mathcal{P} \rightarrow \mathcal{P}} \in \mathbb{R}^{N_{\mathcal{P}} \times N_{\mathcal{P}}}\);(2)跨模态路径引导的交叉注意力编码路径到补丁的相互作用 \(\mathbf{A}_{\mathcal{P} \rightarrow \mathcal{H}} \in \mathbb{R}^{N_{\mathcal{P}} \times N_{\mathcal{H}}}\);(3)跨模态组织学引导的交叉注意力编码补丁到路径的相互作用 \(\mathbf{A}_{\mathcal{H} \rightarrow \mathcal{P}} \in \mathbb{R}^{N_{\mathcal{H}} \times N_{\mathcal{P}}}\);以及(4)内模态完全组织学自注意力编码补丁到补丁的相互作用 \(\mathbf{A}_{\mathcal{H} \rightarrow \mathcal{H}} \in \mathbb{R}^{N_{\mathcal{H}} \times N_{\mathcal{H}}}\)。
由于 patches token 的数量远大于路径的数量,即 \(N_{\mathcal{H}} \gg N_{\mathcal{P}}\),大部分的内存需求来自于计算和存储 \(\mathbf{A}_{\mathcal{H} \rightarrow \mathcal{H}}\)。为了解决这个瓶颈,我们将 Transformer 注意力近似为:
其中 \(\mathbf{Q}_{\mathcal{P}}\)(分别为 \(\mathbf{K}_{\mathcal{P}}\))和 \(\mathbf{Q}_{\mathscr{H}}\)(分别为 \(\mathbf{K}_{\mathscr{H}}\))表示途径和组织学查询和键的子集。将 softmax 前的 patches 到 patches 交互设置为 \(-\infty\) 相当于忽略这些交互。展开方程 10,我们得到 \(\mathbf{X}_{\text {Att}}^{(\mathcal{P})}=\sigma\left(\frac{\mathbf{Q}_{\mathcal{P}} \mathbf{K}^T}{\sqrt{d}}\right) \mathbf{V}_{\mathcal{P}}\),和 \(\hat{\mathbf{X}}_{\text {Att}}^{(\mathscr{H})}=\sigma\left(\frac{\mathbf{Q}_{\mathscr{H}} \mathbf{K}_{\mathcal{P}}^T}{\sqrt{d}}\right) \mathbf{V}_{\mathscr{H}}\)。交互的数量显著减少,使得计算 \(\hat{\mathbf{A}}\) 的内存需求有限。这种表述可以视为多模态序列上的稀疏注意模式 [4],其中稀疏性是在 patches 标记之间强加的。这种表述在参数效率上也很高,因为为编码两种模态学习了一套独特的键、查询和值。此外,这种表述类似于图神经网络,在这个网络上,途径相互连接,并且每个途径都与所有 patches 连接。
通过将 \(\hat{\mathbf{x}}_{\text {Att}}\) 通过一个带有层归一化的前馈层后,我们取得了注意力后途径和 patches 标记的平均表征,分别记为 \(\overline{\mathbf{x}}_{\mathrm{Att}}^{\mathcal{P}}\) 和 \(\overline{\mathbf{x}}_{\mathrm{Att}}^{\mathfrak{H}}\)。最终的表征 \(\overline{\mathbf{x}}_{\mathrm{Att}}\),然后通过连接 \(\overline{\mathbf{x}}_{\mathrm{Att}}^{\mathcal{P}}\) 和 \(\overline{\mathbf{x}}_{\mathrm{Att}}^{\mathcal{H}}\) 来定义。
3.4 生存预测¶
使用多模态嵌入 \(\overline{\mathbf{x}}_{\text {Att }} \in{\R}^{2d}\),我们的监督目标是预测患者的生存期。根据先前的工作【90】,我们通过以下方式定义患者的生存状态:(1) 审查状态 \(c\),其中 \(c=0\) 表示观察到的患者死亡,\(c=1\) 对应于患者的最后已知随访;(2) 事件发生时间 \(t_i\),如果 \(c=0\),则对应于患者诊断和观察到的死亡之间的时间,如果 \(c=1\),则对应于最后一次随访。我们不直接预测事件的观测时间 \(t\),而是通过定义基于生存时间值四分位数的非重叠时间间隔 \(\left(t_{j-1}, t_j\right), j \in[1, \ldots, n]\) 并表示为 \(y_j\) 来近似它。问题简化为分类,每个患者现在由 \(\left(\overline{\mathbf{x}}_{\text {Att }}, y_j, c\right)\) 定义。我们定义的分类器使得每个输出逻辑(经 sigmoid 激活后)\(\sigma\left(\hat{y}_j\right)\) 表示患者在时间间隔 \(\left(t_{j-1}, t_j\right)\) 内死亡的概率。我们进一步采取逻辑的累积乘积 \(\prod_{k=1}^j\left(1-\sigma\left(\hat{y}_k\right)\right)\) 来表示患者在时间间隔 \(\left(t_{j-1}, t_j\right)\) 内生存的概率。最后,通过取所有逻辑之和的负值,我们可以定义用于训练网络的患者级风险。更多信息请参见补充材料。
3.5 多层次可解释性¶
我们提出了一个在多个层次上运作的可解释性框架,以推导转录组学、组织学和跨模态可解释性(见补充材料)。
转录组学: 我们使用积分梯度(IG)【68】来识别途径和基因的影响,得出一个描述每个途径或基因对预测风险贡献程度的分数。负 IG 分数对应于与较低风险相关的途径/基因,而正 IG 分数表明与较高风险相关。非常小的分数表示影响可以忽略。这种可解释性分析有两个目的:
- (1)验证已知与预后相关的基因和途径;
- (2)识别可能预测预后的新的基因和途径候选者。
组织学: 我们类似地使用 IG 来推导 patches 级影响,使得能够研究低风险和高风险相关 patches 的形态学。
跨模态交互: 最后,我们可以使用学习到的 Transformer 注意力矩阵 \(\hat{\mathbf{A}}\) 研究途径到 patches 和 patches 到途径的交互。具体地,我们定义 patches \(j\)(分别是途径)相对于途径 \(i\)(分别是 patches)的重要性为 \(\hat{\mathbf{A}}_{i j}\)(分别是 \(\hat{\mathbf{A}}_{j i}\))。这使得可以构建相关途径和相应形态特征的热图。这种可解释性属性是我们框架独有的,使得能够研究由途径描述的特定细胞功能如何与组织学互动。
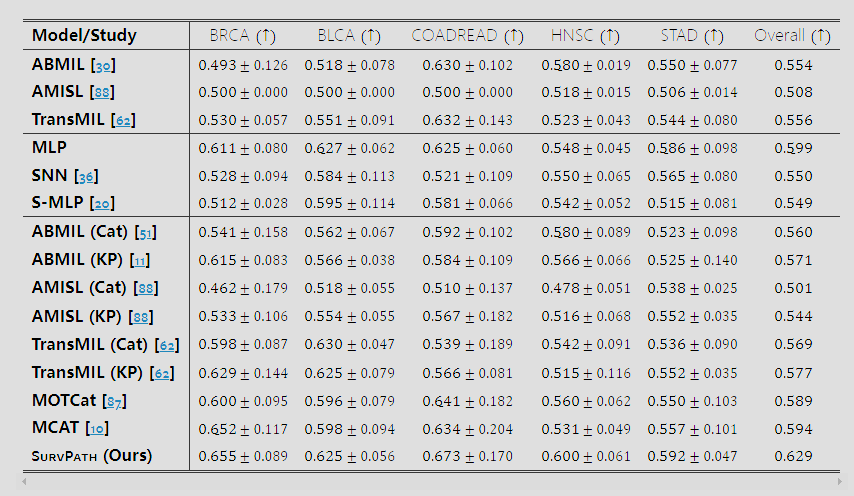
表 1: 使用 c- 指数(在 20 倍放大下)衡量的 SURVPATH 和 baseline 在预测特定疾病患者生存方面的结果。最佳表现加粗,次佳下划线。Cat 表示串联,KP 表示克罗内克积。所有组学和多模态 baseline 都使用了 Reactome 和 Hallmark 途径集进行训练。
4 实验¶
4.1 数据集与实施¶
我们在来自 TCGA 的五个数据集上评估 SurvPath:膀胱尿路上皮癌(BLCA)(n=359)、乳腺浸润性癌(BRCA)(n=869)、胃腺癌(STAD)(n=317)、结直肠腺癌(COADREAD)(n=296)以及头颈部鳞状细胞癌(HNSC)(n=392)。先前的研究集中在预测总生存期(OS)【9】,然而,这种方法有过高估计癌症相关死亡比例的风险,因为患者可能因其他原因死亡。相反,我们预测疾病特异性生存期(DSS),作为更准确的表示患者疾病状态。
途径收集:我们使用 Xena 数据库【23】访问 TCGA 的原始转录组学数据及其 DSS 标签。我们从两个资源中提取途径:Reactome【22】和人类分子标志数据库(MSigDB)- Hallmarks【67, 42】。Reactome 和 MSigDB-Hallmarks 分别包含 1,281 和 50 个人类生物途径。我们进一步选择了至少有 90% 的转录组学数据可用的途径,结果得到 331 个途径,这些途径来源于 4,999 个不同的基因(281 个 Reactome 途径来自 1,577 个基因和 50 个 Hallmarks 途径来自 4,241 个基因)。
组织学收集:我们收集了所有用于初步诊断的诊断性全幅切片图像(WSIs),共得到 2,233 个 WSIs,平均每个 WSI 有 14,509 个 patches,假设使用 256×256 的 patches。总共,我们收集了超过 2.86TB 的原始图像数据,包含约 32.4 百万个 patches。
实施:我们使用 5 折交叉验证来训练所有模型。每个分割都根据样本位置进行分层,以减少潜在的批处理伪迹【28】。为了增加训练期间的变异性,我们从 WSI 中随机采样了 4,096 个 patches。在测试时,使用所有 patches 来得出最终预测(见补充材料)。
4.2 baseline 比较¶
我们将 baseline 分为:(1) 单模态组织学方法,(2) 单模态转录组学方法,以及 (3) 多模态方法(进一步细分为早期融合与晚期融合方法)。
组织学 baseline: 所有 baseline 使用与 SurvPath 相同的预训练特征提取器【76】。我们与 ABMIL【30】进行比较,后者使用门控注意力池化;AMISL【88】,首先使用 K-means 聚类 patches 嵌入再进行注意力处理;以及 TransMIL【62】,该方法使用 Nyström 方法【85】近似 patches 自注意力。
转录组学 baseline: 所有 baseline 使用由 Reactome 和 Hallmarks 转录组学聚合定义的相同输入。(a) MLP【27】使用 4 层 MLP;(b) SNN【27, 9】在 MLP 基础上增加了额外的 alpha dropout 层;(c) S-MLP【25, 20】使用由 2 层稀疏途径感知 MLP 跟随的密集 2 层 MLP。这一 baseline 与我们的转录组学编码器有相似之处。
多模态 baseline: (a) 晚期融合:我们结合了 ABMIL【30】、AMISL【88】和 TransMIL【62】与 S-MLP,并使用串联【51】表示为 ABMIL (Cat)、AMISL (Cat) 和 TransMIL (Cat),以及使用 Kronecker 积【9, 21, 89, 81】表示为 ABMIL (KP)、AMISL (KP) 和 TransMIL (KP)。(b) 早期融合:MCAT【10】使用基因组引导的交叉注意力后跟模态特定的自注意力模块,而 MOTCat【87】使用最优运输(OT)匹配 patches 标记和基因组标记分布。
4.3 生存预测结果¶
表 1 展示了在 20 倍放大下评估的 SurvPath 和 baseline 的结果(参见补充材料中 10 倍分析)。SurvPath 在 20 倍和 10 倍放大下均表现出最佳的整体性能,超越单模态和多模态 baseline。在 20 倍放大下,SurvPath 比 TransMIL 高出 +7.3%,比 MLP 高出 +3.0%,比 MCAT 高出 +3.5%。我们将 SurvPath 的高性能归因于:(1) 使用两种模态,(2) 统一、简单且参数高效的融合模型,(3) 语义意义明确的转录组学标记器。
转录组学 vs. 组织学 vs. 多模态: 多模态 baseline 显著优于组织学 baseline。有趣的是,训练在我们的转录组学集上的简单 MLP 构成了一个强大的 baseline,其性能超过了几种多模态方法。这突出了执行稳健的特征选择和整合异质和高维数据模态的挑战。此外,相对较小的数据集大小进一步复杂化了复杂模型的学习和过拟合风险。与临床变量的比较在补充材料中提供。
有上下文 vs. 无上下文: 尽管 TransMIL 使用 Nyström 注意力模拟路径到 patches 的交互,ABMIL 和 TransMIL 的表现相似。这一观察支持了我们忽略 patches 到 patches 交互的设计选择。此外,SurvPath 在不同放大倍数下的表现相似(在两种情况下整体 c 指数均为 0.629)。这一观察也适用于大多数组织学和多模态 baseline。
稀疏 vs. 密集转录组学编码器: 密集的 MLP 提供了比稀疏途径感知 MLP 更好的表现。然而,当考虑的基因数量显著增加时,稀疏网络已显示出特别的参数效率,并且比常规 MLP 更具可解释性【20】。随着基因数量的增加,这一趋势可能会发展变化。
早期融合 vs. 晚期融合: 早期融合方法(MCAT【10】、MOTCat【87】和 SurvPath)优于所有晚期融合方法。我们将这一观察归因于创建了一个可以模拟转录组学和组织学标记之间精细互动的联合特征空间。总的来说,这些发现证明了需要(1)模拟途径和 patches 标记之间的密集交互,以及(2)在单一 Transformer 注意力中统一融合的必要性。
4.4 消融研究¶
为了评估我们的设计选择,我们进行了一系列消融研究,探讨了不同的标记器和融合方案。
标记器: SURVPATH 采用 Reactome 和 Hallmarks 数据库作为生物途径的来源。我们评估了仅使用其中每个数据库的模型性能,以及将所有基因分配给一个标记(单一)和在【10】中使用的基因家族。随着转录组学标记的粒度增加,整体性能提高,表明构建具有语义的标记带来了可解释性属性并提高了性能。我们将这一观察归因于每个标记编码了越来越具体的生物功能,从而更好地实现了跨模态建模。
融合: 我们通过进一步简化 Transformer 注意力,只考虑其左部分 \(A_{\mathcal{P}} \rightarrow \mathcal{P}\) 和 \(A_{\mathscr{H} \rightarrow \mathcal{P}}\),以及其顶部部分 \(A_{\mathcal{P} \rightarrow \mathcal{P}}\) 和 \(A_{\mathcal{P} \rightarrow \mathscr{H}}\)(这种设计类似于 MCAT【10】中学习的单一共享多模态注意力层)来对 SURVPATH 进行消融。两个分支带来了互补信息(观察到 c 指数的下降分别为 -5.6% 和 -7.5%),这证明了需要模拟途径到 patches 和 patches 到途径的交互。我们进一步将 SURVPATH 适配为 Nyström 注意力,该注意力通过使用低秩近似简化自注意力,使得在非常长的序列上进行训练成为可能。这导致了性能显著下降 -6.9%。我们假设“真正的全注意力”具有低熵,使其更难通过低秩方法近似【8】,并且稀疏注意力模式提供了更好的近似。

图 3:乳腺癌患者多层次可解释性可视化 顶部:低风险患者。底部:高风险患者。红色的基因和途径表示增加风险,蓝色的基因和途径表示降低风险。热图颜色表示重要性,红色表示高重要性,蓝色表示低重要性。在这些案例中识别为重要的途径和形态学通常与先前在侵袭性乳腺癌中描述的模式(例如,晚期雌激素反应)相符。
4.5 可解释性¶
对多层次可解释性的研究可以带来关于途径和组织学在决定患者风险方面的相互作用的新的生物学见解。这里,我们比较了乳腺侵袭性癌症(BRCA)的低风险(顶部)和高风险(底部)案例(图 3)以及膀胱尿路上皮癌(BLCA)(见补充材料)。
在分析图 3 时,我们观察到在低风险和高风险案例中,几个途径具有高绝对重要性分数,尤其是标志性上皮 - 间质转换(EMT)【79】和 COX 反应途径【50】,这两个途径已知参与乳腺癌。EMT 被认为是肿瘤细胞侵袭和转移的基础【34】,而这一途径对低风险和高风险案例的反向重要性与这一分析相符。这一发现通过研究突出 EMT 与肿瘤细胞群侵袭基质的关联的跨模态可解释性得到加强。COX 家族的环氧化酶成员,尤其是 COX-2,也与乳腺癌发生有关,并且作为治疗方案的组成部分正在研究中【26】。跨模态可解释性在两种案例中均显示了间质和免疫细胞。尽管图 3 中两种案例的重要途径有一些重叠,但大多数途径在两者之间是不同的。例如,在高风险案例中,识别了与铁代谢相关的途径(已知对乳腺癌的发生和预后有贡献【69】),显示了小团肿瘤细胞穿过密集基质侵袭的 patches。在低风险案例中,发现与细胞对雌激素反应相关的途径很重要,相应的 patches 显示了低级别侵袭性癌症或原位癌的形态,这与他人观察到的激素阳性乳腺癌往往等级较低并具有较长生存时间的观点一致【19】。有趣的是,标志性肌肉生成途径在图 3 的两种案例中都被赋予了相对较高的正面重要性。肌肉生成在乳腺癌中尚未被广泛研究,但假设肿瘤细胞自身可能表达这一途径中涉及的基因作为其上皮 - 间质转化的一部分,或它们诱导间质细胞这样做。这突出了我们的方法推动对后续研究的新的生物学见解的能力。
我们方法在提供单模态和跨模态可解释性方面的灵活性,使我们能够发现可能用于设计更好的癌症治疗方案的新的多模态生物标志物。随着我们对疾病分子基础的理解加深,SurvPath 的可解释性可能会激发针对特定形态和途径组合的靶向研究。
结论¶
本文解决了转录组学和组织学多模态融合面临的两个挑战:(1)通过定义编码语义上有意义且可解释功能的生物途径标记,我们解决了转录组学标记化的挑战;(2)我们通过设计一个具有稀疏模态特定注意力模式的多模态 Transformer,克服了整合长多模态序列的计算挑战。我们的模型在测试 TCGA 的五个数据集时实现了最先进的生存性能。此外,我们的可解释性框架揭示了已知的和候选的预后特征。尽管我们的可解释性框架能够识别预后特征,但这些发现仍然是定性的。未来的工作可以关注在数据集级别推广发现的可解释性指标,例如,对特定途径的定量形态特征描述。此外,我们的发现表明,包括 patches 到 patches 的交互并没有提高性能。尽管如此,性能未提升不应被视为 patches 到 patches 交互不必要的证据,而应视为模拟这种交互是一个仍待解决的挑战性问题。
补充材料¶
1. 生存预测¶
根据前面引入的符号,我们的目标是通过多模态嵌入 \(\overline{\mathrm{x}}_{\mathrm{Att}} \in \mathbb{R}^{2d}\) 来预测患者的生存情况。与之前的工作【90】一致,我们通过以下方式定义患者的生存状态:(1) 审查状态 \(c\),其中 \(c=0\) 表示观测到的患者死亡,\(c=1\) 对应于患者的最后已知随访;(2) 事件到发生时间 \(t_i\),如果 \(c=0\),对应于患者诊断和观测到的死亡之间的时间,如果 \(c=1\),则对应于最后一次随访。我们没有直接预测事件发生的观测时间 \(t\),而是通过定义基于生存时间值四分位数的非重叠时间间隔 \(\left(t_{j-1}, t_j\right),j \in[1, \ldots, n]\) 并表示为 \(y_j\) 来近似它。这个问题简化为带有审查信息的分类问题,每个患者现在由 \(\left(\overline{\mathrm{x}}_{\mathrm{Att}}, y_j, c\right)\) 定义。我们构建了一个分类器,网络预测的每个输出逻辑 \(\hat{y}_j\) 对应一个时间间隔。由此,我们定义离散危险函数 \(f_{\text {hazard }}\left(y_j \mid \overline{\mathrm{x}}_{\mathrm{Att}}\right)=S\left(\hat{y}_j\right)\),其中 \(S\) 是 sigmoid 激活函数。直观上,\(f_{\text {hazard }}\left(y_j \mid \overline{\mathrm{x}}_{\text {Att }}\right)\) 表示患者在时间间隔 \(\left(t_{j-1}, t_j\right)\) 内死亡的概率。此外,我们定义了离散生存函数 \(f_{\text {surv }}\left(y_j \mid \overline{\mathrm{x}}_{\text {Att }}\right) = \prod_{k=1}^j\left(1-f_{\text {hazard }}\left(y_k \mid \overline{\mathrm{x}}_{\text {Att }}\right)\right)\),表示患者在时间间隔 \(\left(t_{j-1}, t_j\right)\) 内生存的概率。这使我们能够定义负对数似然(NLL)生存损失【90】,将 NLL 推广到具有审查的数据。正式地,我们表示为:
其中 \(N_{\mathcal{D}}\) 是数据集中的样本数。直观上,方程 2 确保了在最终随访后仍然存活的患者具有高生存概率,方程 3 确保了观察到死亡的患者在死亡时间戳之前有高生存概率,方程 4 确保了观察到死亡的患者的正确时间戳被预测。更全面的数学描述可以在【90】中找到。
最后,通过取所有逻辑的负和,我们可以定义用于识别不同风险组和分层患者的患者级风险。
2. 实施细节¶
2.1 模型训练¶
代码使用 Python 3.9 实现,模型在 PyTorch 中实现,可解释性基于 Captum【37】。SuRvPATH、baseline 和消融研究使用 RAdam 优化器【45】进行优化,批大小为 1,学习率为 \(5 \times 10^{-4}\),权重衰减为 \(10^{-3}\)。patches 编码器产生 768 维嵌入(CTransPath 输出),这些嵌入被投影到 \(d=256\),即标记维度。转录组学编码器由 2 层前馈网络组成,带有 alpha dropout【36】以产生途径标记。Transformer 实现为单头和单层,不使用类(CLS)标记。Transformer 后跟一个层归一化、一个前馈层和一个 2 层分类头。所有模型训练均在单个 NVIDIA RTX 3090Ti 上完成。
2.2 评估指标¶
模型使用以下两个指标进行评估:(1) 一致性指数(c-index,越高越好),这一指标测量模型预测值正确预测实际生存顺序的所有可能观察对的比例(从 0.5(随机预测)到 1.0(完美预测));(2) Kaplan-Meier(KM)曲线,用于可视化不同风险组患者在一定时间内的生存概率。我们应用 logrank 统计显著性检验来确定低风险和高风险组之间的分离是否具有统计意义(\(\mathrm{p}\) 值 \(<0.05\))。
3. 额外的可解释性¶
图 1 展示了所提出的多层次可解释性框架的高级描述。
为了补充主文中提出的可解释性分析,我们进一步分析了 BLCA 中的低风险和高风险案例(见图 2)。组织学解释表明,健康膀胱肌肉的存在降低风险,而多形性肿瘤细胞和泡沫样细胞质增加风险。大多数重要途径与细胞周期控制(例如 G2M 检查点,SCF \(\beta \operatorname{TrCP}\) 降解 em1)、代谢(例如脂肪酸代谢)和免疫相关功能(异体排斥和 IL2 STAT5 信号)相关。途径对总体风险的贡献也与以前的文献一致。例如,先前的途径表达分析发现 G2M 检查点和免疫相关途径在预测膀胱癌预后中具有重要意义【33】。通过 SURVPATH 发现的跨模态交互的定性评估在科学上是合理的。例如,异体排斥途径包括多个在免疫反应中激活的基因。在低风险案例中,异体排斥高度关注肿瘤浸润的淋巴细胞和靠近膀胱肌肉墙的淋巴细胞集合。在高风险案例中,这一途径再次关注分散在肌肉壁中的炎症细胞。SCF \(\beta \operatorname{TrCP}\) 降解 em1 途径在控制有丝分裂的细胞分裂中起重要作用。在低风险案例中,该途径关注未受累的膀胱肌肉;而在高风险案例中,同一途径关注侵入膀胱肌肉的肿瘤细胞。尽管在低风险和高风险案例中存在途径的重叠,但 SURVPATH 也识别出仅在一种案例中出现的途径。例如,在低风险案例中,SURVPATH 发现蛋白质分泌途径高度关注肿瘤细胞而非健康的膀胱肌肉细胞。在两种情况下,G2M 检查点途径(对细胞周期的健康进程至关重要)都被认为是重要的。在高风险案例中,我们看到这一途径主要是增加风险。有趣的是,我们还发现这一途径关注大面积的坏死区,这是合理的,因为细胞周期调控的异常会导致细胞死亡。
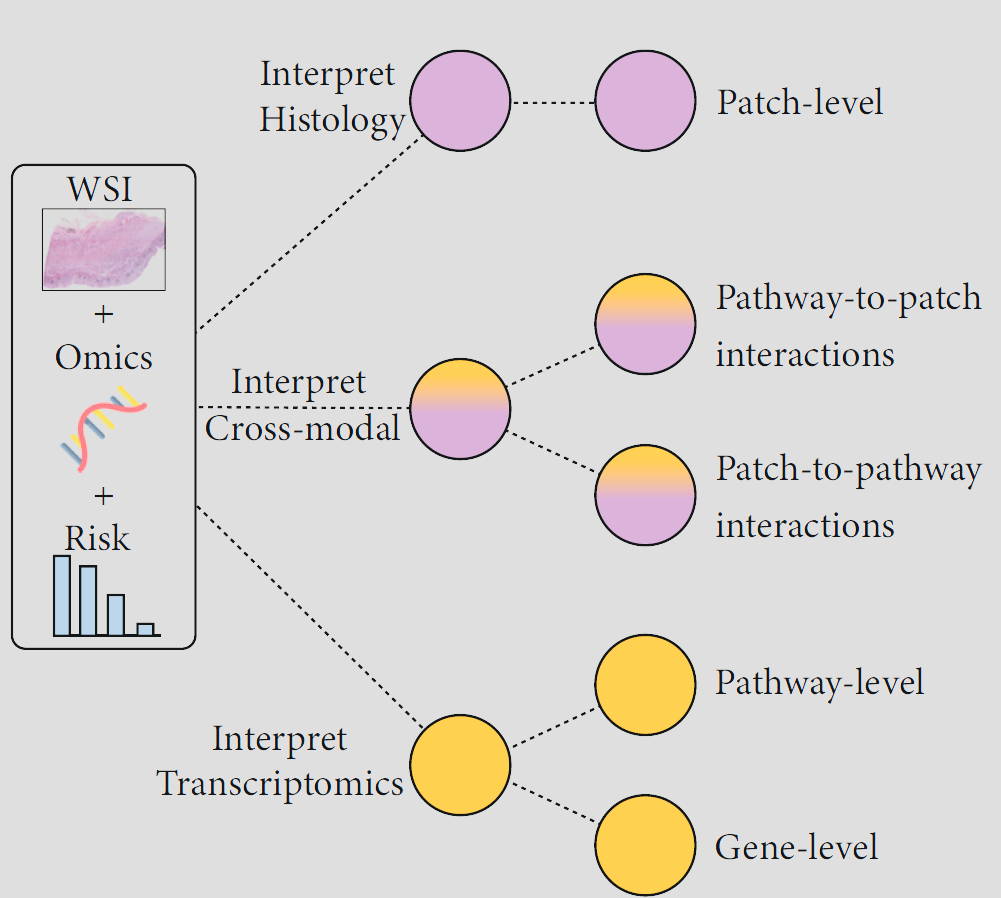
图 1. 多层次可解释性框架。 从包含全幅切片图像(WSI)和转录组学测量的多模态输入以及预测的风险,我们可以在切片级、基因级和生物途径级别上进行风险归因。该框架还支持研究途径到 patches 的交互和 patches 到途径的交互,以解开两种模态之间的对应关系。
4. 额外结果¶
10 倍放大下的结果¶
我们也在 10 倍放大下对 SURVPATH 及 baseline(表 1)和消融研究(表 2)进行了分析。从 20 倍放大分析的趋势仍然存在:(1)SURVPATH 实现了最佳的整体性能,(2)转录组学 baseline 仍是强有力的竞争者,(3)多模态模型提供了更好的整体性能。有趣的是,SURVPATH 在 10 倍和 20 倍放大下提供相同的性能(在五个队列中为 62.9%)。
Kaplan-Meier 分析¶
图 3 展示了 20 倍放大下预测的高风险和低风险组的 Kaplan-Meier 生存曲线。所有风险高于整个队列中位数的患者被分配为高风险(红色),风险低于中位数的患者被分配为低风险(蓝色)。对于所有五种疾病,SURVPATH 相较于最佳组织学 baseline(TransMIL)、转录组学 baseline(MLP)和多模态 baseline(MCAT),在两个风险组之间展示了统计上更好的区分度。
我们相信 SURVPATH 能更好地区分风险组,因为简化的早期融合机制使其能够在患者风险方面找到转录组学和组织学之间更好的相关性。
与临床协变量的比较¶
从临床上,预后可以基于患者信息如年龄,以及癌症进展评估如癌症分级。我们使用 Cox 比例风险模型从临床协变量(年龄、性别、分级)单独和组合预测生存。我们发现 SURVPATH 在所有临床协变量的生存预测中表现更佳(表 3)。
模态归因¶
通过对每种模态的整合梯度(IG)值进行预协注意总和,我们可以得出模态归因分数(表 4)。我们发现组织学在队列中贡献了 77.2%,突显了多模态在预后中的必要性。

图 2:膀胱癌患者的多层次可解释性可视化 顶部:低风险患者。底部:高风险患者。红色的基因和途径表示增加风险,蓝色的基因和途径表示降低风险。热图颜色表示重要性,红色表示高重要性,蓝色表示低重要性。在这些案例中识别为重要的途径和形态通常与先前在膀胱尿路上皮癌中描述的模式相符(例如,G2M 检查点)。