scBERT as a large scale pretrained deep language model for cell type annotation of single cell RNA seq data
摘要¶
根据单细胞 RNA 测序数据对细胞类型进行注释是研究疾病进程和肿瘤微环境的先决条件。我们在这里展示了,现有的注释方法通常存在缺乏经过校准的标记基因列表、不当处理批次效应以及难以利用潜在的基因 - 基因相互作用信息等问题,从而影响了它们的泛化能力和鲁棒性。我们开发了一种基于预训练深度神经网络的模型,即单细胞双向编码器表示 transformer(scBERT),以克服这些挑战。借鉴 BERT 的预训练和微调方法,scBERT 通过在大量未标记的 scRNA 测序数据上进行预训练,获得了对基因 - 基因相互作用的一般理解; 之后,它将转移到未见过和用户特定的 scRNA 测序数据的细胞类型注释任务上进行有监督的微调。广泛而严格的基准研究验证了 scBERT 在细胞类型注释、新细胞类型发现、抗批次效应和模型可解释性方面的卓越性能。
正文¶
单细胞 RNA 测序 (scRNA-seq) 已被广泛用于表征单细胞水平上复杂组织和生物体,这革新了转录组学研究。在 scRNA-seq 上准确的细胞类型注释对于生物和医学研究至关重要。细胞类型注释方法可分为三类:(1) 使用标记基因进行注释,(2) 使用基于相关性的方法进行注释,(3) 通过监督分类进行注释。
聚类 - 然后 - 注释是常用的方法,其中从文献中识别出的人工 curated 的标记基因被用于为来自无监督学习的聚类指定细胞类型。然而,选择标记基因取决于研究人员的先验知识,因此容易产生偏差和错误。此外,对感兴趣的细胞类型的标记基因并不总是可用的,而新的细胞类型目前还没有标记基因集。另外,大多数细胞类型是由一组基因确定的,而不是单一的标记基因。如果没有合适的方法来整合多个标记基因的表达信息,就难以保证每个聚类的细胞类型分配是统一和准确的。例如,一些自动注释方法建立在这样的假设上: 标记基因在细胞中应该有高表达。然而,即使是一些有很好文档记录的标记基因,在相应细胞类型的所有细胞中也不一定有高表达。这些标记基因的表达缺失或波动因此可能会严重影响基于标记基因的方法的精确度。
与依赖少量标记基因不同,基于相关性的方法测量查询样本与参考数据集之间的基因表达谱相关性。这些方法可能会受到跨平台和实验的批次效应影响。尽管存在批次效应校正方法,但区分真正的生物多样性和技术差异,并因此保留重要的生物学变异仍然具有挑战性。同时,常用的相似性度量 (即余弦相似性、Spearman 相关性和 Pearson 相关性) 可能无法高效稳健地测量两组高维稀疏 scRNA-seq 数据之间的距离。
通过监督/半监督分类方法进行注释遵循机器学习中识别基因表达谱模式并将标签从有标签数据集转移到无标签数据集的经典范例。由于这些方法对噪声和数据变异的稳健性,以及它们不依赖人工选择的标记基因,最近广泛使用。然而,由于这些方法的模型容量有限,大多数需要在将数据输入分类器之前执行高变异基因 (HVG) 选择和降维。然而,不同批次和数据集之间的 HVG 是不同的,这阻碍了它们跨队列的泛化能力。如主成分分析 (PCA) 等降维技术可能会丢失高维信息,以及基因水平的独立可解释性。此外,这些方法中的 HVG 选择和 PCA 参数设置远未达成共识,不可避免地会为性能评估引入人为偏差。鉴于 HVG 是基于整个数据集的表达方差选择的,其中主导细胞类型占据了大部分方差,存在忽略罕见细胞类型关键基因的风险。选择 HVG 忽略了基因的共现性和生物学相互作用 (特别是 HVG 和非 HVG 之间),这对细胞类型注释很有用。另外,简单分类器如全连接网络无法有效捕获基因 - 基因相互作用。因此,需要一种具有改进的模式识别能力的新方法来克服以上对大规模数据集欠拟合的问题。
最近,越来越多基于深度学习的方法应用于 scRNA-seq 数据分析,并取得了卓越性能。双向编码器表示 transformer(BERT) 是一种最先进的基于 Transformer 的语言表示学习模型,由于 Transformer 层引入的强大自注意力机制和长程信息整合能力,在自然语言处理 (NLP) 领域取得了突破性进展。BERT 的预训练和微调范例使模型能够利用大规模未标记数据来提高其泛化能力。受此令人兴奋的进展的启发,我们开发了单细胞 BERT(scBERT) 模型,用于 scRNA-seq 数据的细胞注释。遵循预训练和微调范例,我们验证了在大规模未标记 scRNA-seq 数据上应用自监督学习来提高模型的泛化能力和克服批次效应的威力。广泛的基准测试表明,scBERT 可以提供稳健准确的细胞类型注释,并具有基因级的可解释性。据我们所知,scBERT 开创性地将 Transformer 架构应用于 scRNA-seq 数据分析,创新性地为基因设计了嵌入式特征。
结果¶
scBERT 算法¶
原始的 BERT 提出了一种革命性的技术,通过预训练产生语言的通用知识,然后使用微调将知识转移到不同配置的下游任务中。遵循 BERT 的思路和范例,我们开发了一种名为 scBERT 的新颖统一架构 (图 1),它通过在来自不同来源的数百万种无标签 scRNA-seq 数据 (包含各种细胞类型) 上进行预训练,学习 scRNA-seq 的一般知识; 然后仅需插入一个分类器并由参考数据集监督地对参数进行微调,即可分配细胞类型。预训练使模型能够学习基因 - 基因相互作用的一般语法,有助于消除数据集间的批次效应并提高泛化能力 (扩展数据图 1a)。微调可确保每个基因的输出嵌入编码了与参考数据集的转录谱更相关的上下文信息。为注释查询细胞,scBERT 通过挖掘高层隐式模式 (扩展数据图 1b),计算该细胞属于参考数据集中任何细胞类型的概率。需要注意的是,如果没有可以高置信度分配的细胞类型,查询细胞将被标记为未分配类型,以防止错误分配并允许发现新的细胞类型。与原始 BERT 模型相比,scBERT 在细胞类型注释任务中具有一些创新设计来发挥其潜力。
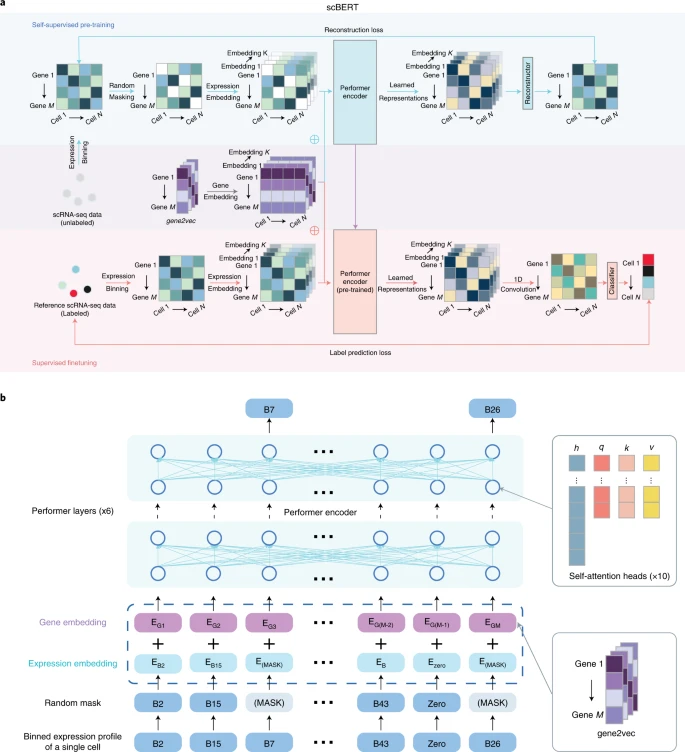
a, 在未标记数据上进行自监督学习并在特定任务数据上进行微调。在自监督预训练阶段,来自 PanglaoDB 的未标记数据被收集。遮蔽表达嵌入和基因嵌入被添加为输入,然后被馈送到 Performer 块中。重构器被用于生成输出。遮蔽基因的输出被用于计算重构损失。在有监督微调阶段,特定任务的 scRNA-seq 数据被输入到预训练的编码器中。输出表示通过一个一维卷积层和一个分类器以生成细胞类型预测。⊕ 表示元素级别的加和。Performer 编码器是预训练和微调阶段模型之间共享的组件。重构器和分类器分别独立地用于预训练和微调过程中的模型。
b, scBERT 嵌入的示意图。预处理后的 scRNA-seq 数据首先被转换为离散化表达,然后非零表达被随机遮蔽。以第一个基因为例,基因嵌入 EG1(来自 gene2vec 并落入第一个 bin 的基因标识) 和表达嵌入 EB2(落入第二个 bin 并被转换为与 EG1 相同维度的基因表达) 被求和并输入到 scBERT 中以生成基因表示。这些表示随后被用于预训练或微调。
首先,BERT 的嵌入包括词元嵌入和位置嵌入。我们的嵌入设计在某些方面类似于 BERT,但具有利用基因知识的独特特征。原始 BERT 的词元嵌入是一个离散变量 (代表一个单词),而我们模型的原始表达输入是一个连续变量 (代表一个单细胞中基因的表达),带有生物和技术噪声。我们借鉴自然语言处理领域的词袋技术,将基因表达值分箱 (可视为每个细胞中的基因转录频率),将其转换为离散值,同时在一定程度上减少数据噪声。由于改变我们输入的列顺序不会改变其含义 (就像使用 TaBERT 扩展 BERT 以理解表格数据),基因的绝对位置是无意义的。相反,我们从 gene2vec 获取基因嵌入来表示基因身份 (每个基因都有一个唯一的 gene2vec 嵌入),可将其视为相对嵌入,用于从一般共表达的角度捕获语义相似性。共表达基因保留更接近的表示,基因的分布式表示被证明对捕获基因 - 基因相互作用很有用。通过这种方式,scBERT 有效地形式化了 Transformer 中的基因表达信息,并在预训练后生成了表示细胞特异性表达的单细胞特异性嵌入 (scBERT 嵌入)(扩展数据图 1c)。
其次,由于现有的单细胞方法对有效建模高维数据的能力有限,因此必须通过基因选择或操作 (即 HVG 选择、手动选择标记基因和 PCA) 对原始数据进行预处理; 这将不可避免地带来人为偏差和过拟合问题,从而严重损害它们的泛化能力。相反,具有大感受野的 Transformer 可以有效利用 scRNA-seq 数据中的全局信息,通过无偏捕获长程基因 - 基因相互作用,为每个细胞学习全面的全局表示。由于计算复杂性,Transformer 的输入序列长度被限制为 512,而大多数 scRNA-seq 数据包含超过 10,000 个基因。因此,我们用 Performer 替换了 BERT 中使用的 Transformer 编码器,提高了模型对超过 16,000 个基因输入的处理能力。使用 Performer 后,scBERT 保留了全基因水平的解释性,放弃了使用 HVG 和降维,让显著基因和有用的相互作用自发浮现 (扩展数据图 1d)。因此,scBERT 允许以无偏的数据驱动方式发现用于细胞类型注释的基因表达模式和更长程依赖关系。scBERT 稳定且鲁棒,不过于依赖于超参数的选择 (扩展数据图 1e)。
嵌入设计创新:
- 将基因表达值离散化为 bin,借鉴自然语言处理中的 bag-of-words 技术,有助于降噪。
- 使用 gene2vec 表示基因身份,捕捉语义上的基因共表达相似性。
- 将基因表达嵌入和基因身份嵌入相加,生成每个单细胞的特定 scBERT 嵌入表示。
模型架构创新:
- 替换 BERT 的 Transformer 编码器为 Performer,提高了模型对高维数据的建模能力。
- 避免了人工选择高变异基因或降维,让显著模式自发浮现,减少人为偏差。
- 通过捕捉长程基因 - 基因相互作用,学习每个细胞的全面整体表示。
- 保留了全基因水平的可解释性,不依赖超参数选择,提高了稳健性。
评估细胞类型注释在单一数据集内的稳健性¶
我们首先在涵盖 17 个主要器官/组织、超过 50 种细胞类型、超过 50 万个细胞以及主流单细胞组学技术 (Drop-seq、10X、SMART-seq 和 Sanger-Nuclei) 的九个 scRNA-seq 数据集上,全面考虑了数据大小和数据复杂性的多样性,对 scBERT 与其他方法的性能进行了基准测试。用于比较的有基于标记基因的方法 (SCINA、Garnett、scSorter)、基于相关性的方法 (Seurat v4、SingleR、scmap_cell、scmap_cluster、Cell_ID(c)、Cell_ID(g)) 和基于机器学习的方法 (SciBet、scNym)(补充表 2)。对于每个数据集,我们采用了五折交叉验证策略,以避免随机结果对结论的影响。在大多数数据集上,scBERT 在准确性和宏 F1 分数方面都超过了对比方法 (图 2a 和扩展数据图 2)。
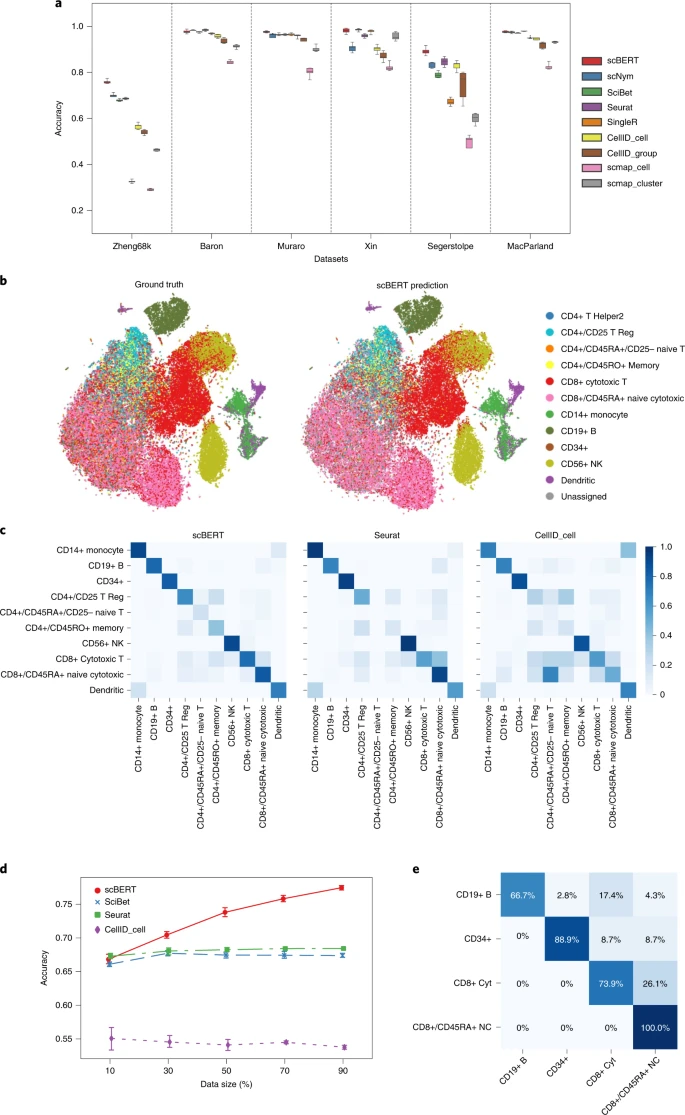
- 图 2a 显示在 9 个数据集上使用 5 折交叉验证时,scBERT 在准确率和宏 F1 分数上都优于其他对比方法。
- 图 2b 展示了在 Zheng68K 数据集 (68,450 个细胞) 上,scBERT 的预测结果与专家注释的细胞类型高度一致。
- 图 2c 给出了在 Zheng68K 上 scBERT、Seurat 和 CellID_cell 方法的交叉验证混淆矩阵热图,scBERT 表现最好。
- 图 2d 研究了将不同比例的 Zheng68K 数据集用作微调参考集对注释性能的影响。
- 图 2e 展示了在从 Zheng68K 重构的不平衡数据集上,scBERT 的交叉验证混淆矩阵
在单一数据集中,来自人外周血单个核细胞 (PBMCs) 的 Zheng68K 数据集是基准测试细胞类型注释方法的最具代表性的数据集。由于细胞类型严重不平衡,以及亚型之间的极高相似性,即使是最先进的方法也无法达到 0.71 以上的准确率。完全删除已报告的标记基因后,scBERT 的性能已与现有方法的最佳性能相当 (扩展数据图 1b),证明了 scBERT 在基因表达模式识别能力上相较于严重依赖已知标记基因的那些方法的优越性。加入标记基因后,scBERT 能捕获由它们构建的更全面的基因表达模式。以所有基因作为输入时,scBERT 在整体细胞上远超最先进方法 (图 2b,c 和扩展数据图 3 和图 4a;scBERT F1 分数=0.691,准确率=0.759; 其他方法最佳 F1 分数=0.659,准确率= 0.704),并 for CD8+ 细胞毒性 T 细胞和 CD8+/CD45RA+T 细胞取得了最高性能 (F1 分数=0.788 对 0.617,P 值=9.025×10^-5; 准确率=0.801 对 0.724,P 值=2.265×10^-5),后两者高度相似,在之前的研究中很难区分。结果表明,经过预训练,scBERT 能够识别潜在的基因表达模式和长程基因 - 基因依赖关系,通过多头注意力捕获多样化的特征子空间,并享有细胞类型特异性全局信息的全面高级表示。
值得注意的是,不同任务和数据集上表现最佳的方法名单会发生变化,而 scBERT 总是在其中。例如,在图 2 的 Xin 数据集上,跨数据集 (即 scNym 和 Seurat) 的顶级方法表现很差。这种性能的不确定性反映了对比方法在泛化能力方面的局限性,以及我们的方法在所有基准测试数据集上的泛化能力。
为探究参考数据集的细胞数量是否会影响 scBERT 的性能,我们从 Zheng68K 数据集按比例均匀采样构建了一系列 10% 到 90% 的参考数据集 (图 2d)。即使只有 30% 的细胞,scBERT 也优于所有其他方法,并且随着参考细胞数量的增加,其性能迅速提高。
我们接下来测试了当细胞类型分布严重偏向时 scBERT 的稳健性。从 Zheng68K 数据集中选择四种细胞类型 (CD8+ 细胞毒性 T 细胞、CD19+B 细胞、CD34+ 细胞和 CD8+/CD45RA+naive 细胞毒性细胞),每对之间在转录组上相似,用于类别不平衡测试。scBERT surpassed 所有其他方法 (准确率=0.840,F1 分数=0.826)。Seurat 将 CD8+ 细胞毒性 T 细胞误识为 CD8+/CD45RA+naive 细胞毒性细胞,而 SingleR 由于其稀有性而将所有 CD19+B 细胞误分类。然而,尽管这两种细胞群体高度相似,scBERT 展现出了最低的误分类率 (图 2e 和扩展数据图 4b)。总的来说,结果表明 scBERT 对类别不平衡数据集具有稳健性。
跨队列和器官的细胞类型注释¶
在现实情况下,参考和查询数据集总是来源于多项研究,甚至来自不同的测序平台,这时批次效应会导致细胞类型注释性能下降 (图 3a)。在这里,我们采用留一个数据集外的策略,使用不同测序技术生成的人胰腺数据集 (Baron35、Muraro36、Segerstolpe37 和 Xin38; 图 3 和扩展数据图 5) 对 scBERT 和对比方法进行基准测试。基于机器学习的方法 (scBERT、scNym 和 SciBet) 取得了最佳结果,表明细胞类型特异性模式可以通过模式识别发现,而不受批次效应影响; 然而,Seurat 在注释之前依赖于强制性批次校正。对于跨队列数据,scBERT 以 0.992 的准确率取得了远远优于 scNym(准确率 0.904) 的卓越性能,也优于其他流行方法 (准确率:SciBet=0.985,Seurat=0.984,SingleR=0.987; 图 3b)。scBERT 正确注释了 Muraro 数据集中大多数细胞 (>97%),以及其他三个数据集中超过 99% 的细胞,展现了我们方法在跨队列任务中出色且稳定的性能。相比之下,scNym 将 α 细胞误分为 β 细胞类型,并被 β 细胞和 δ 细胞混淆 (图 3e,f)。然后,我们使用来自不同器官的细胞来基准测试 scBERT 和对比方法在跨器官数据集上的性能。实验结果表明,scBERT 在跨器官任务上与对比方法表现相当 (扩展数据图 5b)。scBERT 展现了在不同测序技术、实验、不同疾病状态 (2 型糖尿病和健康) 乃至不同器官中识别细胞的稳健性。
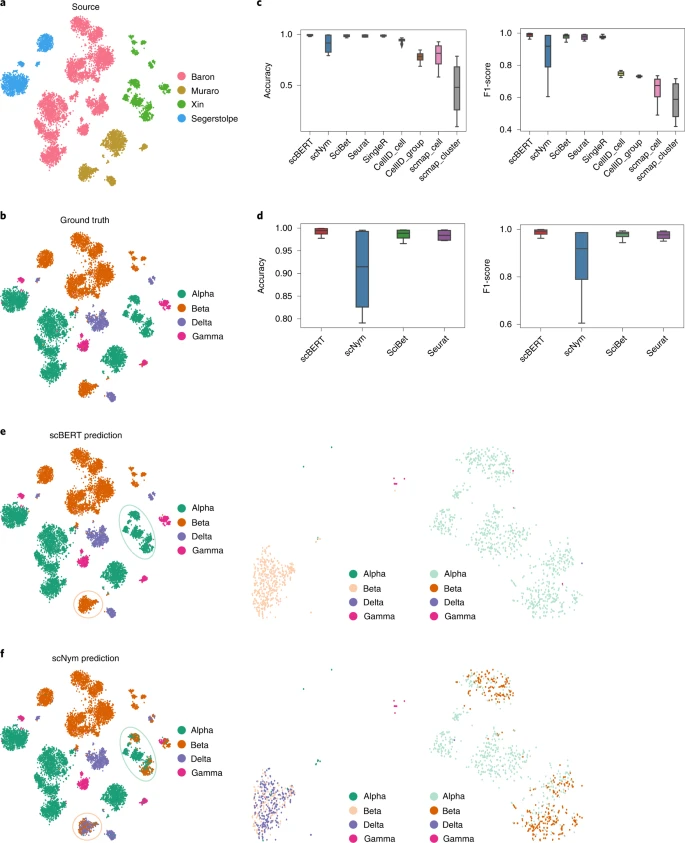
a, 来自四个独立数据集 (Baron、Muraro、Segerstolpe 和 Xin) 的 10,220 个细胞的 t-SNE 表示,这些数据集由不同的测序平台 (inDrop、CEL-Seq2、SMART-Seq2 和 SMARTer) 生成。细胞按数据集来源着色。 b, 来自四个胰腺数据集的 α、β、δ 和 γ 细胞,按原文 atlas 提供的注释细胞类型着色。 c, 不同方法在跨数据集交叉验证中的准确率和 F1 分数对比。下 hinges 和上 hinges 分别表示第一和第三四分位数,whiskers 在 1.5 倍的四分位距范围内。 d, 顶级方法的准确率和 F1 分数的局部放大图。 e, 来自四个胰腺数据集的 α、β、δ 和 γ 细胞 (左侧)、Muraro 数据集的 β 细胞 (中间) 和 Segerstolpe 数据集的 α 细胞 (右侧) 的 t-SNE 表示,按 scBERT 预测着色。 f, 来自四个胰腺数据集的 α、β、δ 和 γ 细胞 (左侧)、Muraro 数据集的 β 细胞 (中间) 和 Segerstolpe 数据集的 α 细胞 (右侧) 的 t-SNE 表示,按 scNym 预测着色。其他对比方法的 t-SNE 图显示在扩展数据图 5a。
发现新细胞类型¶
在大多数任务中,参考数据集可能无法覆盖查询数据集中存在的所有细胞类型。基于标记基因的方法受到手动选择已知细胞类型标记基因的限制,因此可能难以区分未见过的细胞类型; 而基于相关性的方法通常会将新类型强行分配到最近的已知类型。基于机器学习的方法可以通过检查预测概率自动主动地检测新细胞类型。另外,scBERT 还享有一些潜在优势: 首先,多头注意力机制允许 scBERT 从不同的表示子空间提取信息,这可能有利于捕捉新细胞类型与已知类型之间的细微差异。其次,scBERT 可能在大规模多样数据集上的预训练过程中已经看到过新细胞并学习了它们独特的模式。第三,具有大感受野的 Transformer 可以通过捕获长程基因 - 基因相互作用有效地学习全面的全局表示,这可能更好地描述和区分新细胞类型。
scBERT 在新细胞类型上表现最佳,并在已知细胞类型上取得了顶级性能 (图 4)。CellID_cell 在已知细胞类型上表现良好,但未能发现任何新细胞。SciBet 和 scmap_cluster 倾向于将未知标签分配给来自已知类型的细胞,这大大降低了它们对已知细胞类型的分类精度。与 SciBet 和 scmap_cluster 相比,我们的方法在新细胞 (scBERT=0.329 vs SciBet=0.174 和 scmap_cluster=0.174) 和已知细胞 (scBERT=0.942 vs SciBet=0.784 和 scmap_cluster=0.666) 类型上都取得了更高的准确率。总的来说,这些结果表明 scBERT 能够正确发现原始参考数据集中不存在的新细胞类型,同时在预测其他细胞类型的性能方面保持准确性。
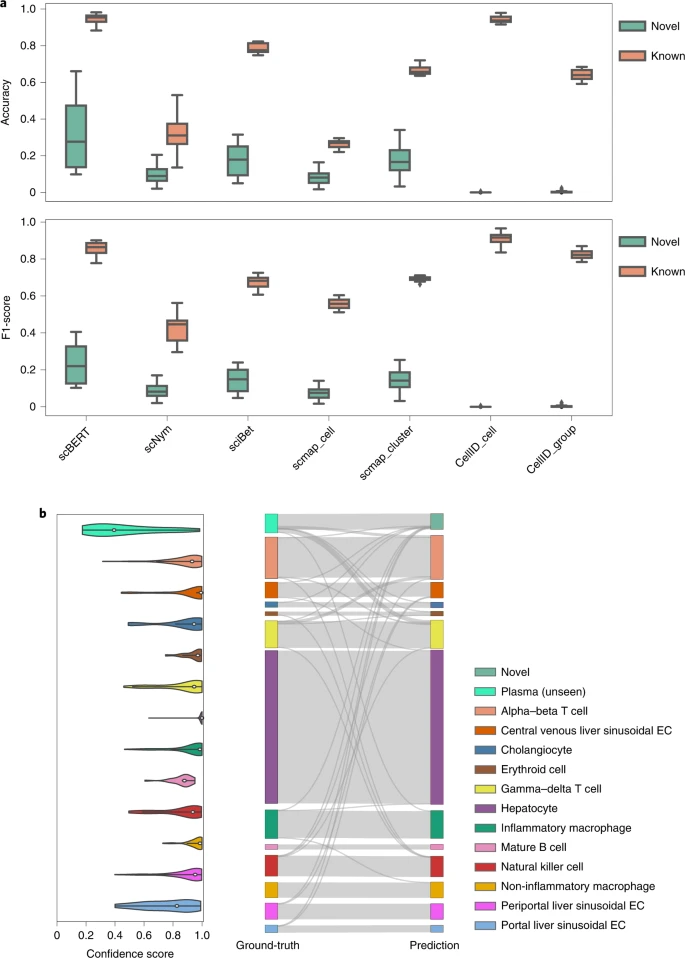
a, 在 scBERT 训练过程中移除 α-β T 细胞、γ-δ T 细胞、成熟 B 细胞和浆细胞群体后,scBERT 在来自人肝组织的 MacParland 数据集上的性能。新细胞类型和已知细胞类型的准确率和 F1 分数都显示在箱线图中,其中显示了中位数 (中心线)、四分位数范围 (hinges) 和 1.5 倍四分位数范围 (whiskers)。 b, 左图:scBERT 为 MacParland 数据集的细胞类型提供的置信度分数; 对于所有已知细胞类型的模型预测概率都很低 (概率<0.5) 的细胞被分配为潜在的新细胞类型。右图: 用桑基图比较 scBERT 对 MacParland 数据集中已知和新细胞类型的预测与原始细胞类型注释,其中浆细胞被标记为新细胞类型,因为它们在 scBERT 训练过程中未见过。EC: 内皮细胞。
研究 scBERT 模型的可解释性¶
由于其简化的网络架构和低模型容量,现有的机器学习方法必须选择 HVGs 或降低维度,因此破坏了基因水平的可解释性。相比之下,scBERT 中采用的注意力机制自然地为模型的决策提供了关于每个个体基因的线索。
在这里,我们以 Muraro 数据集为例,并为四种胰岛细胞生成了顶部注意力基因列表,这些细胞具有良好研究的生物学功能(图 5a)。顶部注意力基因包括特定细胞类型的已报道标记物(α 细胞的 LOXL4 和 β 细胞的 ADCYAP1;扩展数据图 6a)。除了标记物之外,几乎所有顶部注意力基因都被识别为使用 DESeq40 找到的差异表达基因,作为潜在的新标记物(图 5c 和扩展数据图 6b)。例如,SCD5 尚未被报道为 β 细胞的特异性标记物,但在一项 GWAS 研究中,将 2 型糖尿病易感性的新位点精细定位到了 SCD 的编码变异 41。结果表明,scBERT 能够促进理解细胞类型的注释,并为进一步的生物学发现提供一些支持。
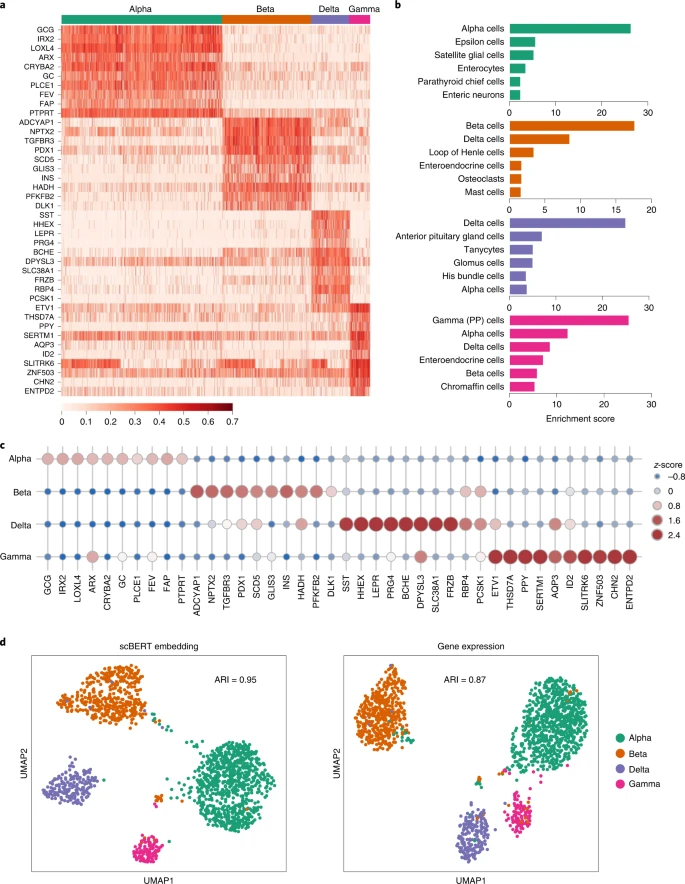
a,热图显示了 scBERT 在胰腺细胞类型注释任务上提供的注意力权重。详细的注意力估计过程在方法中描述。列出了每种细胞类型的前 10 个具有最高注意力权重的基因。完整的前列基因列表可在附录表 3 中找到。 b,来自 scBERT 的前列注意力基因的富集分析结果,完整信息详见附录表 4–15。 c,点图显示了接收到最高关注度的十个基因之间的 z 分数,以及细胞类型。每个点的大小和颜色反映了 z 分数。 d,UMAP 表示了来自 Muraro 数据集的 α、β、δ 和 γ 细胞,根据 scBERT 嵌入(左图)和每个细胞的原始表达(右图)着色。调整后的 Rand 指数(ARI)得分已计算并显示在图中。
对于前 50 个注意力基因列表进行了富集分析,使用了各种基因集库;结果显示了顶部富集术语与相应细胞类型之间的一些有趣关系(图 5b 和附录表 3–15)。特别是,使用 PanglaoDB 的细胞类型相关基因集库时,每种类型的顶部富集术语总是与真实的细胞种群相关。作为另一个例子,胰岛素分泌和 AMPK 信号通路,在 β 细胞中是前两个富集的 KEGG 通路,对 β 细胞功能至关重要。此外,基于聚类性能,scBERT 嵌入比原始基因表达更具有区分性,用于细胞类型注释(ARI:0.95 对比 0.87),表明了 scBERT 在学习单细胞特定表示方面的效率,可用于下游分析(图 5d)。
讨论¶
为了提高细胞类型注释算法的泛化能力和单个基因重要性的可解释性,我们开发了 scBERT(一种具有多头注意力机制和自监督策略的深度学习模型),通过学习大规模未标记的单细胞 RNA 测序数据的全基因组表达模式和相互作用,将通用知识转移到细胞类型注释任务中进行微调;并追溯每个单个基因的重要性以进行模型解释。通过系统分析 scBERT 的组成部分,我们对 Transformer 在单细胞数据分析中的应用有了一些见解(即预训练的好处、非标记模式的识别、微妙基因 - 基因相互作用的检测、单细胞特定嵌入和超参数敏感性)。有关系统分析,请参阅方法和扩展数据图 1。
scBERT 在多个基准测试中超越了现有的先进方法,涉及 9 个单细胞数据集、17 个主要器官/组织、50 多种细胞类型、超过 500,000 个细胞以及主流的单细胞组学技术(即 Drop-seq、10X、SMART-seq 和 Sanger-Nuclei),表明其泛化性和稳健性。值得注意的是,我们在本研究中使用准确率、宏 F1 分数和混淆矩阵作为评估指标,以公平比较细胞类型注释方法的分类能力。
据我们所知,目前还没有研究将 Transformer 架构应用于基因表达数据分析。原始设计的端到端 scBERT 框架,具有基因表达嵌入和自学习策略,对细胞类型注释任务具有优越的性能、可解释性和泛化潜力。除此之外,scBERT 还可以通过简单修改输出和监督信号应用于其他任务。作为一种有效的细胞类型注释工具,scBERT 已发布在公共平台上供公众使用。我们希望 scBERT 能够提高对细胞类型相关基因 - 基因相互作用的理解,并促进单细胞 RNA 测序分析中人工智能范式的革命。
尽管 scBERT 具有上述优势,但可能面临潜在限制,包括基因表达嵌入、建模基因相互作用以及预训练阶段的屏蔽策略。
首先,原始 BERT 的标记嵌入是针对离散变量的(代表一个单词),而表达输入是连续变量的(代表单个细胞中基因的表达),可能存在生物和技术噪音。scBERT 将它们转换为离散值,与直接使用表达值的现有方法相比,可以减少一些数据噪音;然而,它牺牲了一些数据分辨率,优化基因表达嵌入以适应模型输入仍有改进空间。我们的表达分箱方法可能导致一些分辨率丢失。其次,基因相互作用通常以网络形式存在(即基因调控网络和生物信号传导通路),这种先验知识尚未明确纳入 scBERT。基于生物网络的图神经网络内聚信息,可能更好地模拟基因 - 基因相互作用。这个想法可以应用于单细胞分析,通过使用单细胞 RNA 测序数据构建细胞级图。从这个角度来看,可以预见到基于图的 Transformer 可能是 scBERT 未来发展的方向。第三,预训练阶段的屏蔽效率是另一个值得优化的方面。scBERT 中当前的屏蔽策略是简化的非零屏蔽。使用零膨胀的输入,模型可能倾向于在预训练期间为重构任务输出全部零值。因此,我们屏蔽了非零值,并根据非零值计算了预训练期间的损失;然而,仅屏蔽非零值可能会降低单细胞数据在预训练中的利用率,因为它们是少数。可以引入针对单细胞数据量身定制的高级屏蔽策略,以提高屏蔽过程的计算效率。
对于未来的工作,我们希望探索 scBERT 在各种下游任务中的多功能性和灵活性(例如,基因 - 基因相互作用、批次校正、聚类、疾病条件下的差异分析)。
方法¶
scBERT 模型¶
scBERT 模型采用了 BERT 的先进范式,并定制了架构以解决单细胞数据分析问题。我们的模型与 BERT 的联系如下。首先,scBERT 遵循 BERT 的革命性方法进行自监督预训练 25,并使用 Transformer 作为模型的骨干 32。其次,我们的嵌入设计在某些方面类似于 BERT,但具有利用基因知识的独特特点。从这个角度来看,我们的表达嵌入可以被视为 BERT 的标记嵌入。由于我们输入的列进行洗牌不会改变其含义(就像将 BERT 扩展为理解带有 TaBERT27 的表格数据一样),基因的绝对位置是没有意义的。我们使用 gene2vec 生成基因嵌入,它可以被视为捕捉任意两个基因之间语义相似性的相对嵌入 26。第三,具有全局感受野的 Transformer 可以在没有绝对位置信息的情况下有效地学习全局表示和长程依赖关系,从而在非顺序数据(如图像、表格)上取得出色的性能 24,27。
基因嵌入¶
在自然语言处理中,BERT 模型的输入是词嵌入,即一组实值向量,位于预定义的向量空间中,表示单个词。词嵌入技术有助于通过确保具有相似含义的单词具有相似的表示来更好地表示文本 46。然而,从单细胞 RNA 测序的角度来看,输入由个别基因组成,需要一个预定义的向量空间来表示它们之间的相似性。因此,我们采用 gene2vec28 来专门编码基因嵌入。通过这种方式,借助过去知识提供的基因间关系,减少了模型训练的难度。
表达嵌入¶
尽管有基因嵌入,但如何利用每个基因的转录水平也是一个挑战,实际上这是一个单一的连续变量。值得注意的是,一个词在文本中出现的频率对于文本分析是宝贵的信息,并且通常通过术语频率统计分析转换为词袋以用于自然语言处理领域的下游任务。基因表达也可以被视为在生物系统中已经被充分记录的每个基因的出现。基于这一洞见,我们采用了常用的术语频率分析方法,通过分箱离散化连续表达变量,并将其转换为 200 维向量,然后将其用作 scBERT 模型的标记嵌入。
模型构建¶
以 Transformer 作为基本单元的 BERT 模型的二次计算复杂度对于长序列的扩展并不是很好,而单细胞 RNA 测序的基因数可以多达 20,000 多个。为此,我们采用了一种矩阵分解版本的 Transformer(即 Performer)来扩展序列长度。Transformer 中的常规点积注意力是对输入查询、键和值的编码表示进行映射,分别为 \(Q, K, V\),这些表示是为每个单元创建的。双向注意力矩阵的公式化表示为:
在上述公式中,\(\operatorname{Att}(Q, K, V)\) 表示注意力矩阵,定义为 \(D^{-1}\left(Q K^T\right) V\),其中 \(D=\operatorname{diag}\left(Q K^T 1_L\right)\),\(Q=W_q X, K=W_K X, V=W_V X\) 是输入 \(X\) 的线性变换;\(W_Q\), \(W_K, W_V\) 是参数的权重矩阵;\(1_L\) 是长度为 \(L\) 的全 1 向量;\(\operatorname{diag}(\cdot)\) 是一个以输入向量为对角线的对角矩阵。
Performer 中的注意力矩阵描述如下:
其中 \(Q^{\prime}=\emptyset(Q), K^{\prime}=\emptyset(K)\),并且函数 \(\emptyset(x)\) 定义为:
在上述公式中,\(c\) 是一个正常数,\(\omega\) 是一个随机特征矩阵,\(m\) 是矩阵的维度。在我们的模型中,我们使用了六个 Performer 编码器层,每个层有十个头。
模型训练过程包含两个阶段:在未标记的数据上进行自监督学习以获得预训练模型,然后在特定的细胞类型注释任务上进行监督学习以获得微调模型。
在未标记数据上的自监督学习¶
在本研究中,我们遵循了 NLP 任务中 BERT 模型的传统自学习策略,即通过随机屏蔽输入数据值并基于剩余输入进行预测。考虑到辍学零现象,我们随机屏蔽了非零基因表达,然后通过模型对剩余基因进行预测来重构原始输入。我们利用交叉熵损失作为重构损失,其公式为:
其中 \(M\) 是细胞数,\(N\) 是屏蔽的基因表达值的数量;\(y_{i, j}\) 和 \(p_{i, j}\) 分别是细胞 \(i\) 中基因 \(j\) 的真实和预测表达。通过这种自监督策略,模型可以在大量未标记的数据上学习基因表达模式的通用深度表示,这可能会减轻下游微调过程的工作量。
在特定任务上的受监督学习¶
scBERT 的输出是与每个基因对应的 200 维特征,对于每个基因特征,我们应用了一维卷积来提取抽象信息。然后,我们应用了一个三层神经网络作为分类头,并将基因特征转换为每种细胞类型的概率。交叉熵损失也被用作细胞类型标签预测损失,计算如下:
其中 \(z_i\) 和 \(q_i\) 分别表示细胞 \(i\) 的真实细胞类型标签和预测标签。
数据集¶
由于模型训练包含两个阶段,即对无标签数据进行自监督学习和对特定任务数据进行微调,所以在这两个阶段使用的数据集来自不同的来源,以避免数据泄漏。在第一个阶段,我们使用大量未经注释的数据进行通用模式学习,而在第二个阶段,需要具有良好注释的细胞标签的特定任务数据,以便对 scBERT 和 SOTA 方法进行后续系统性基准测试。为此,我们仅包括提供高度可信的细胞类型注释并且被大多数细胞类型注释方法引用的 scRNA-seq 数据集用于性能评估。
Panglao 数据集
Panglao 数据集从 PanglaoDB 网站(https://panglaodb.se/)下载。简而言之,PanglaoDB 通过各种平台整合了 209 个人类单细胞数据集,包括来自不同实验来源的 74 种组织的 1,126,580 个细胞。在本研究中,我们使用了 PanglaoDB 中的 scRNA-seq 数据进行第一阶段的预训练。在第一阶段,我们采用了自我学习策略,不使用任何注释或细胞标签,仅需要基因及其表达水平作为 scBERT 模型的输入。
Zheng68k 数据集
Zheng68k 是一个经典的 10X CHROMIUM 的 PBMC 数据集,被广泛用于细胞类型注释性能评估。它包含约 68,450 个细胞,分为十一个细胞亚型:CD8+ 细胞毒性 T 细胞(30.3%)、CD8+/CD45RA+ 天然细胞毒性细胞(24.3%)、CD56+ 自然杀伤细胞(12.8%)、CD4+/CD25 T 调节细胞(9.0%)、CD19+ B 细胞(8.6%)、CD4+/CD45RO+ 记忆细胞(4.5%)、CD14+ 单核细胞(4.2%)、树突状细胞(3.1%)、CD4+/CD45RA+/CD25- 天然 T 细胞(2.7%)、CD34+ 细胞(0.4%)和 CD4+ T 辅助细胞 2(0.1%)。Zheng68k 数据集包含罕见的细胞类型,并且该数据集中细胞类型的分布不平衡。细胞类型之间的强相关性使得它们难以区分。
胰腺数据集
胰腺数据集包括 Baron、Muraro、Segerstolpe 和 Xin。细胞类型标签已对齐,包括四种细胞类型。Baron 数据集从 Gene Expression Omnibus(GEO)(存取号 GSE84133)下载,采用 inDrop35 协议。Muraro 数据集从 GEO(存取号 GSE85241)下载,采用 CEL-Seq236 协议。Segerstolpe 数据集从 ArrayExpress(存取号 E-MTAB-5061)获取,采用 Smart-Seq237 协议。Xin 数据集从 GEO(存取号 GSE81608)下载,采用 SMARTer38 协议。上述胰腺数据集是从不同的实验平台生成的(见补充表格 1)。
MacParland 数据集
MacParland 数据集是来自人类肝脏组织的数据,包含了来自 10X CHROMIUM 的 20 种肝细胞群的 8,444 个细胞的转录谱。我们从 GEO(存取号 GSE115469)下载了数据,并按照作者报告的过程生成了细胞类型注释。
心脏数据集
心脏数据集包括一个用于预训练的大型数据集,以及一个用于超参数敏感性分析中的基准测试和评估的 Tucker 数据集。大型心脏数据集用于预训练,包含了来自 11 种细胞类型的 451,513 个细胞,由四种不同的测序平台(Harvard-Nuclei、Sanger-Nuclei、Sanger-Cells 和 Sanger-CD45)生成,并从 https://data.humancellatlas.org/explore/projects/ad98d3cd-26fb-4ee3-99c9-8a2ab085e737 下载。Tucker 数据集包含了来自单核 RNA 测序的 11 种细胞类型的 287,269 个细胞,从 https://singlecell.broadinstitute.org/single_cell/study/SCP498/transcriptional-and-cellular-diversity-of-the-human-heart 下载。
肺数据集
肺数据集来自人类肺组织,并对与 COVID-19 相关的疾病机制进行了分析。该数据集包含了来自 12 名供体的样本,使用 10X Genomics 测序,共有来自九种细胞类型的 39,778 个细胞。数据从 https://doi.org/10.6084/m9.figshare.11981034.v1 下载。
人类细胞图谱数据集
人类细胞图谱数据集包含了来自 15 个主要器官(皮肤、食道、气管、心脏、脾脏、胆总管、胃、肝脏、血液、淋巴结、小肠、膀胱、直肠、骨髓、肌肉)的 27 种细胞类型,共 84,363 个细胞,通过 HiSeq X Ten 测序。该数据集从 GEO(存取号 GSE159929)下载。
数据预处理
对于以基因表达矩阵格式提供的数据,对数据进行对数归一化处理,使用大小因子为 10,000,并通过筛选表达少于 200 个基因的细胞异常值进行质量控制。至于 scBERT 的输入,没有进行降维或 HVG 选择处理,因为 scBERT 作为输入具有超过 20,000 个基因的容量,并保留了完整的基因级可解释性。
比较方法¶
为了进行基准测试,我们实施了三种注释类别的 SOTA 方法:基于标记基因、基于相关性和监督分类。其中,SCINA、Garnett 和 scSorter 代表使用标记基因数据库进行注释;Seurat、SingleR、CellID 和 scmap 是基于相关性的方法;而 scNym 和 Scibet 是通过监督/半监督分类进行注释的 SOTA 方法。值得注意的是,这种分类取决于最重要的过程是如何进行的。至于基于标记基因的注释,采用了 CellMarker 数据库,该数据库使用对超过 100,000 篇文献的文献搜索手动筛选了细胞类型标记物。没有包括手动选择标记基因,以进行所有方法的无偏和公平比较。
scNym
scNym 是一种最近提出的半监督学习注释方法,通过训练域对手来利用未标记的目标数据。它不需要事先手动指定标记基因。它通过域适应利用目标数据,并在几个任务上取得了最佳性能;然而,用户必须忍受重新训练模型以适应每批新数据的不便。
Scibet
Scibet 是一种监督分类方法,使用 E 检验选择基因进行多项模型构建,并为测试集中的新细胞注释细胞类型。我们采用 R 包中的 SciBet 进行基准测试。
Seurat
作为流行的单细胞数据分析流程,Seurat 被生物学家和临床专家广泛使用。Seurat 将查询样本映射到参考数据集中,以参考为基础的注释方式进行注释。在本研究中,我们采用了 Seurat v.4.0 的细胞类型注释实现,并按照 Seurat 提供的细胞类型注释教程进行基准测试。
SingleR
SingleR 是一种基于参考的分析方法,它计算变量基因上的 Spearman 系数,并将系数聚合到每个细胞类型的得分中。它通过对顶级基因进行子采样,直到区分出最相关的细胞类型为止,迭代上述过程。我们采用了 SingleR 包进行基准测试。
CellID
CellID 是一种无聚类的多变量统计方法,用于细胞类型注释,它执行降维,评估基因与细胞之间的距离,并为细胞(基于细胞的策略)和组(基于组的策略)提取基因特征。在本研究中,我们使用 R 包中的两种策略进行基准测试。
scmap scmap 是一种基于参考的注释方法,包括两种策略:scmap_cluster 和 scmap_cell;scmap_cluster 将查询样本中的个体细胞映射到参考数据集中的特定细胞类型,而 scmap_cell 将查询样本中的个体细胞映射到参考数据集中的个体细胞 30。scmap_cluster 和 scmap_cell 都执行特征选择和计算距离(余弦距离和欧氏距离)。搜索参考数据集以找到与查询细胞最近邻的细胞。我们使用 scmap 的 R 包进行 scmap-cluster 和 scmap_cell 工具的使用。
SCINA SCINA 是一种典型的基于标记基因的注释方法,需要不同细胞类型的标记基因列表,并根据假设每个标记基因存在双峰分布,并且较高的模式属于相关的细胞类型 9。我们使用 Scina 包进行基准测试。
Garnett Garnett 需要用户定义的细胞类型细胞层次结构和标记基因作为输入。Garnett 使用术语频率 - 逆文件频率变换来聚合标记基因分数,并使用基于弹性网络回归的模型进行注释 10。我们采用原始的 R 包使用 garnet 模型进行基准测试。
scSorter Scsorter 利用标记基因和 HVG 进行聚类和细胞类型注释,基于观察到大多数标记基因不会在属于相关细胞类型的所有细胞中保持一致高的表达水平 31。在这里,我们采用 Scsorter 的 R 实现。
基准测试 为了评估注释方法在不同场景下的性能,生成了九对参考和测试数据集,并使用 scBERT 和所有上述方法进行评估。详细信息如下。
在使用交叉验证的内部数据集上的性能¶
PBMC 数据来自 Zheng68k,具有高的类间相似性,胰腺数据集(Baron、Muraro、Segerstolpe 和 Xin)、MacParland 数据集、Tucker 数据集、肺数据集和人类细胞图谱数据集,采用五折交叉验证的方式测试了内部数据集的性能。值得注意的是,本节中的参考数据集也指的是监督方法的训练数据集,包括 scBERT。
对跨数据集数据的性能¶
为了评估不同单细胞测序平台的批次效应的跨队列数据的方法的稳健性,我们在四个胰腺数据集(Baron、Muraro、Segerstolpe 和 Xin)上测试了方法,每次将三个数据集作为训练集,其余一个作为测试集。考虑到这些数据集中细胞种群的差异,所有数据集都进行了对齐,仅保留了这些数据集中共同的四种胰岛细胞(alpha、beta、delta 和 gamma 细胞)。为了评估方法在跨器官数据上的稳健性,我们在来自人类细胞图谱数据集的三个主要器官(食道、直肠和胃)上测试了方法。
参考细胞数量对性能的影响¶
参考细胞的数量易于影响模型的性能。在本研究中,将来自 Zheng68K 数据集的 PBMC 细胞的 10%、30%、50%、70% 和 90% 随机选择作为微调的参考,而剩余的作为测试样本。
scBERT 系统分析¶
预训练与非预训练¶
遵循 BERT 的预训练和微调范式,我们的方法倾向于生成高效的编码器,并通过揭示关键模式和降低数据噪声,提供更好地表示每个细胞基因表达的普遍嵌入。对具有和不具有预训练的模型性能进行消融研究的结果(Extended Data Fig. 1a)表明,预训练对于模型的下游任务(即细胞类型注释)是至关重要的,在生物信息学领域具有相对大且重要的差异。scBERT 模型从大规模的各种 scRNA-seq 数据中提取有用的基因表达和相互作用的注意模式,减轻了对特定下游任务的微调过程的工作量。
利用基因表达模式进行分类的可行性¶
众所周知,标记基因在基于标记基因的注释和大多数基于参考的注释中起着关键作用。甚至一些监督方法也严重依赖于先前的标记基因知识。在使用标记基因进行分类的当前主流方法中,一些方法使用基因表达模式进行细胞类型注释。据报道,这两种类型的数据都在可变细胞类型注释任务中表现出良好的性能,表明这两种数据都暗示了不同细胞类型的有区别的信息。为了调查标记基因的影响以及仅包含非标记基因的剩余表达模式的区分能力,我们进行了一系列实验,逐渐消除标记基因,仅留下非标记基因的剩余表达模式进行细胞类型注释(Extended Data Fig. 1b 和 Supplementary Table 16)。结果证明了标记基因对于细胞类型注释是重要的;然而,除了标记基因之外,仍然存在一些具有良好区分能力的信息基因模式。删除 100% 的标记基因后,scBERT 仍然可以有效地学习信息基因模式,并在代表性的 Zheng68K 数据集上达到了与所有标记基因的比较方法相媲美的性能(Extended Data Fig. 1b)。我们还探索了在 MacParland 和 Baron 上检测到的基因列表,以及其他机器学习(scNym)和非机器学习(Seurat)方法(Supplementary Tables 17 和 18)。与上述标记删除实验一致,我们观察到基于机器学习的方法倾向于学习高级别的隐式细胞类型特异模式(即,在各种细胞类型之间发现一些排名较高的基因),而非机器学习的方法通常只是通过统计分析找到差异性表达的基因。结果表明,注意机制、显著性机制和统计分析可以从不同角度获得单细胞数据挖掘模式的互补信息。
通用基因嵌入与单细胞特定嵌入¶
Gene2vec 基于大规模数据 28,它测量了来自组织的基因的平均表达,并且是细胞类型特异性基因表达的总和,按细胞类型比例加权 59。在这方面,gene2vec 保持了基因的一般共表达模式,但远离了单细胞测序的强噪声和高稀疏性。因此,我们利用 gene2vec 作为我们的基因嵌入,以表示基因的身份(每个基因具有唯一的 gene2vec 嵌入)和从一般共表达模式的角度来看语义相似性。scBERT 的编码器也可以学习单细胞特定的嵌入(我们简称为 scBERT 嵌入),表示细胞特定的表达。为了说明模型学习过程中嵌入(或表示)的演变,我们在 Extended Data Fig. 1b 中可视化了 gene2vec 和 scBERT 嵌入的示例。我们的模型可以为不同的细胞输入生成同一基因的不同表示,而 gene2vec 为不同细胞输入生成了相同的基因表示。我们观察到 scBERT 嵌入展现了细胞类型特定的表达(即,基因的示例表示在 alpha 细胞中明显丰富),这适用于下游的细胞类型注释任务。此外,细胞类型特定的表示学习了一些超出 gene2vec 的相关性。受益于 Performer 的注意机制,模型可以检测出微妙的基因相互作用模式,这些模式只能在对 scRNA-seq 数据进行模型训练后在单细胞数据中看到(Extended Data Fig. 1d)。可以观察到一些基因对所有其他基因有强烈的注意权重,表明它在识别隐含模式中发挥着关键作用,这与在补充表 17 和 18 中检测到的基因列表的结论一致。
超参数的影响¶
对 scBERT 的超参数敏感性进行了系统的调查,包括 bin 的数量、scBERT 嵌入向量的大小、注意力头的数量和 Performer 编码器层的数量(Extended Data Fig. 1b)。首先,通过将原始表达式排名分为七个 bin 来进行表达嵌入适合 scBERT。将 bin 数量增加到九会妨碍模型的性能,这表明对基因表达进行排名会去噪原始数据,并提高 scBERT 在学习有意义模式方面的效率。相比之下,减少 bin 数量也会影响模型的性能,因为会丢失基因表达信息(即,模糊了相对较大的基因表达差异)。以上实验结果证明了平衡去噪和保留表达信息的 bin 数量的正确设计将有益于模型的性能。其次,gene2vec 提供了一个维度为 200 的嵌入,并且与其他维度相比表现最佳。在潜在空间中减少 scBERT 嵌入向量的维度会损害模型的表示能力和性能(特别是当维度为 50 时)。第三,具有十个注意力头的 Performer 适用于我们的方法。减少注意头的数量可能会减少模型的表示能力,因为代表性子空间较少。增加注意头的数量似乎对性能影响有限;然而,过参数化的模型(带有 20 个注意头)在应用于小型数据集时面临过拟合的风险。类似地,模型在具有四和六个 Performer 编码器层时表现稳定,但在减少或增加层数时可能会遇到欠拟合或过拟合问题。总的来说,上述参数的小波动对模型的性能影响很小,这也验证了 scBERT 的稳健性。
模型可解释性¶
我们进行了全面的可解释性分析,以探索决策制定的关键基因,因为 scBERT 模型是建立在自注意机制上的,并且所有基因的表示都保留在我们工作流程的末尾。注意权重反映了每个基因的贡献以及基因对的相互作用。注意权重可以从方程(1)中获得,通过将 \(V\) 替换为 \(V^0\) 进行修改,其中 \(V^0\) 包含每个位置索引的 one-hot 指示符。我们将所有注意力矩阵整合到一个矩阵中,通过对多头多层 Performer 中的所有注意力矩阵进行逐元素平均。在这个平均注意力矩阵中,每个值 \(A(i, j)\) 表示了基因 \(i\) 对基因 \(j\) 的关注程度。为了关注基因对每个细胞的重要性,我们将注意力矩阵与列一起求和为一个注意力总和向量,其长度等于基因的数量。通过这种方式,我们可以获得与其他细胞类型相比,与特定细胞类型对应的前几个关注基因。注意权重进行了可视化,然后将前几个基因发送到 Enrichr32 进行富集分析。
使用各种基因集库对前 50 个关注基因列表进行了富集分析,结果显示了顶部富集术语与相应细胞类型之间存在一些有趣的关系。
统计分析¶
对显著性检验采用了 Wilcoxon 检验。在所有的基准实验中都采用了交叉验证,并在图中绘制了标准偏差。标准化混淆矩阵用于显示预测结果。显著性是通过 Wilcoxon 检验计算的。对于不同方法检测到的基因列表,使用 Jaccard 指数进行相似度测量。ARI 被用于对聚类进行相似度测量。